MapReduce یک مدل برنامهنویسی برای پردازش حجمیِ مقدار زیادی داده بهصورت دستهای (bulk) روی تعداد زیادی ماشین است که توسط گوگل محبوب شد. شکل محدودی از MapReduce توسط برخی دیتابیسهای NoSQL از جمله MongoDB و CouchDB پشتیبانی میشود، بهعنوان مکانیزمی برای انجام پرسوجوهای فقطخواندنی (read-only) روی تعداد زیادی سند.
بهطور کلی، MapReduce با جزئیات بیشتری در فصل ۱۰ توضیح داده شده است. فعلاً فقط بهطور خلاصه به نحوهی استفادهی MongoDB از این مدل میپردازیم.
MapReduce نه یک زبان پرسوجوی کاملاً اعلانی (declarative) است و نه یک API پرسوجوی کاملاً امری (imperative)، بلکه جایی بین این دو قرار میگیرد: منطق پرسوجو با تکهکدهایی بیان میشود که توسط چارچوب پردازش بهصورت تکرارشونده فراخوانی میشوند. این مدل بر پایهی توابع map (که collect هم نامیده میشود) و reduce (که fold یا inject نیز گفته میشود) است؛ توابعی که در بسیاری از زبانهای برنامهنویسی تابعی وجود دارند.
برای مثال، تصور کنید یک زیستشناس دریایی هستید و هر بار که حیوانی را در اقیانوس مشاهده میکنید، یک رکورد مشاهده (observation) به دیتابیس خود اضافه میکنید. حالا میخواهید گزارشی تولید کنید که نشان دهد در هر ماه چند کوسه دیدهاید.
در PostgreSQL میتوانید این پرسوجو را به این شکل بنویسید:
SELECT date_trunc('month', observation_timestamp) AS observation_month, sum(num_animals) AS total_animals FROM observations WHERE family = 'Sharks' GROUP BY observation_month;
تابع date_trunc('month', timestamp) ماه تقویمیای را که timestamp در آن قرار دارد مشخص میکند و timestamp دیگری را که نشاندهندهی ابتدای آن ماه است برمیگرداند. به عبارت دیگر، این تابع یک timestamp را به نزدیکترین ماهِ پایینتر گرد میکند.
این پرسوجو ابتدا مشاهدهها را فیلتر میکند تا فقط گونههایی از خانوادهی Sharks باقی بمانند، سپس مشاهدهها را بر اساس ماه تقویمیای که در آن رخ دادهاند گروهبندی میکند، و در نهایت تعداد حیوانات دیدهشده در همهی مشاهدههای آن ماه را با هم جمع میکند.
همین کار را میتوان با قابلیت MapReduce در MongoDB به شکل زیر بیان کرد:
db.observations.mapReduce( function map() { var year = this.observationTimestamp.getFullYear(); var month = this.observationTimestamp.getMonth() + 1; emit(year + "-" + month, this.numAnimals); }, function reduce(key, values) { return Array.sum(values); }, { query: { family: "Sharks" }, out: "monthlySharkReport" } );
فیلتر مربوط به در نظر گرفتن فقط گونههای کوسه میتواند بهصورت اعلانی مشخص شود (این یک افزونهی مخصوص MongoDB به MapReduce است).
تابع JavaScriptِ map یک بار برای هر سندی که با query مطابقت دارد فراخوانی میشود، بهطوری که this به شیء سند اشاره میکند.
تابع map یک کلید (رشتهای شامل سال و ماه، مثل "2013-12" یا "2014-1") و یک مقدار (تعداد حیوانات در آن مشاهده) را emit میکند.
جفتهای کلید–مقدارِ تولیدشده توسط map بر اساس کلید گروهبندی میشوند. برای تمام جفتهای کلید–مقداری که کلید یکسانی دارند (یعنی همان ماه و سال)، تابع reduce یک بار فراخوانی میشود.
تابع reduce تعداد حیوانات مربوط به همهی مشاهدههای یک ماه مشخص را با هم جمع میکند.
خروجی نهایی در کالکشنی به نام monthlySharkReport نوشته میشود.
برای مثال، فرض کنید کالکشن observations شامل این دو سند باشد:
{ observationTimestamp: Date.parse("Mon, 25 Dec 1995 12:34:56 GMT"), family: "Sharks", species: "Carcharodon carcharias", numAnimals: 3 } { observationTimestamp: Date.parse("Tue, 12 Dec 1995 16:17:18 GMT"), family: "Sharks", species: "Carcharias taurus", numAnimals: 4 }
در این حالت، تابع map یک بار برای هر سند فراخوانی میشود و در نتیجه emit("1995-12", 3) و emit("1995-12", 4) تولید میشود. سپس تابع reduce با reduce("1995-12", [3, 4]) فراخوانی شده و مقدار ۷ را برمیگرداند.
توابع map و reduce تا حدی در کارهایی که اجازه دارند انجام دهند محدود هستند. آنها باید توابعی خالص (pure functions) باشند؛ یعنی فقط از دادهای که بهعنوان ورودی به آنها داده میشود استفاده کنند، نمیتوانند پرسوجوی دیگری به دیتابیس بزنند و نباید هیچ اثر جانبی (side effect) داشته باشند. این محدودیتها به دیتابیس اجازه میدهد این توابع را در هر جایی، با هر ترتیبی اجرا کند و در صورت بروز خطا دوباره آنها را اجرا کند. با این حال، این توابع همچنان قدرتمند هستند: میتوانند رشتهها را پردازش کنند، توابع کتابخانهای را فراخوانی کنند، محاسبات انجام دهند و کارهای بیشتری انجام دهند.
MapReduce یک مدل برنامهنویسی نسبتاً سطح پایین برای اجرای توزیعشده روی خوشهای از ماشینها است. زبانهای پرسوجوی سطح بالاتر مانند SQL را میتوان بهصورت یک خط لوله (pipeline) از عملیات MapReduce پیادهسازی کرد (به فصل ۱۰ مراجعه کنید)، اما پیادهسازیهای توزیعشدهی زیادی از SQL وجود دارند که از MapReduce استفاده نمیکنند. توجه کنید که در خود SQL هیچ چیزی وجود ندارد که آن را محدود به اجرا روی یک ماشین واحد کند، و MapReduce هم انحصار اجرای پرسوجوهای توزیعشده را در اختیار ندارد.
امکان استفاده از کد JavaScript در میانهی یک پرسوجو ویژگی بسیار خوبی برای پرسوجوهای پیشرفته است، اما این قابلیت فقط محدود به MapReduce نیست—برخی دیتابیسهای SQL نیز میتوانند با توابع JavaScript توسعه داده شوند.
یکی از مشکلات کاربری MapReduce این است که باید دو تابع JavaScript که با دقت با هم هماهنگ شدهاند بنویسید، که اغلب سختتر از نوشتن یک پرسوجوی واحد است. علاوه بر این، یک زبان پرسوجوی اعلانی فرصتهای بیشتری به بهینهساز پرسوجو میدهد تا عملکرد پرسوجو را بهبود دهد. به همین دلایل، MongoDB در نسخهی 2.2 پشتیبانی از یک زبان پرسوجوی اعلانی به نام aggregation pipeline را اضافه کرد.
در این زبان، همان پرسوجوی شمارش کوسهها به شکل زیر نوشته میشود:
db.observations.aggregate([
{ $match: { family: "Sharks" } },
{ $group: {
_id: {
year: { $year: "$observationTimestamp" },
month: { $month: "$observationTimestamp" }
},
totalAnimals: { $sum: "$numAnimals" }
}}
]);
زبان aggregation pipeline از نظر قدرت بیان شبیه به زیرمجموعهای از SQL است، اما بهجای نحوِ جملهمانند SQL از نحو مبتنی بر JSON استفاده میکند؛ تفاوتی که شاید بیشتر به سلیقه برگردد. پیام نهایی داستان این است که یک سیستم NoSQL ممکن است ناخواسته در حال بازآفرینی SQL باشد، هرچند در لباسی مبدل.
این بخش دقیقاً جاییه که انتخاب مدل داده از «کدنویسی» میره توی «تفکر معماری».
ایدهی اصلی در یک جمله
وقتی ارتباط بین دادهها زیاد و پیچیده میشه، جدول و داکیومنت اذیت میکنن؛ گراف طبیعیترین مدل میشه.
1. بدون رابطه یا خیلی کم
مثلاً:
لاگها
eventها
پیامها
📌 Document DB عالیه (Mongo)
2. One-to-Many (درختی)
مثلاً:
بلاگ → پستها → کامنتها
سفارش → آیتمها
📌 Document Model هنوز خوبه
{ "post": "Graph DB", "comments": [ { "text": "good" }, { "text": "nice" } ] }
3. Many-to-Many (اینجا درد شروع میشه)
مثلاً:
کاربر ↔ گروه
دانشجو ↔ درس
آدمها ↔ آدمها (دوستی، ازدواج، فالو)
📌 اینجا Relational سخت میشه
📌 Document تقریباً شکست میخوره
📌 Graph میدرخشه
مثال:
یک کاربر در ۱۰۰ گروه
هر گروه ۱۰۰۰ کاربر
اگر embed کنی:
دیتا تکراری
آپدیت کابوس
consistency مشکل
اگر reference بدی:
query پیچیده
join دستی
performance بد
Relational میگه:
users groups user_groups
تا اینجا اوکیه 👌
اما وقتی:
depth زیاد میشه
رابطه روی رابطه میخوای
traversal میخوای
مثلاً:
دوستِ دوستِ دوستِ من کیه؟
SQL شروع میکنه به زجر دادن.
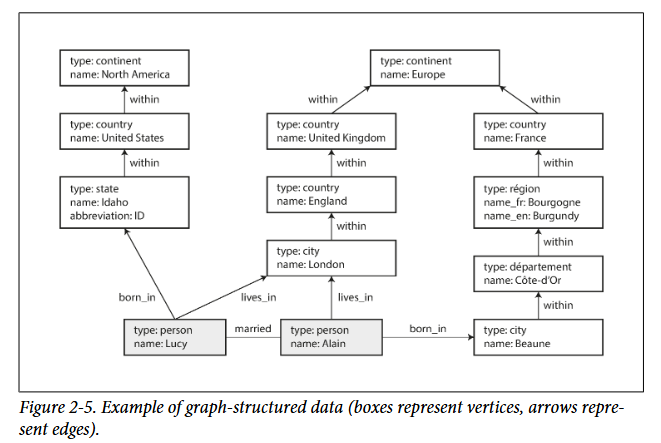
Vertex (Node)
آدم
شهر
پست
رویداد
Edge (Relation)
دوستِ
ازدواج با
زندگی میکند در
شرکت کرده در
(Lucy) --[married_to]-- (Alain) | | [lives_in] [lives_in] | | (London) (London)
همه چیز رابطهمحوره.
چون سؤالهامون رابطهایه:
لوسی کجا زندگی میکنه؟
همسرش کیه؟
دوستان همسرش کیان؟
کیا توی لندن هستن و متأهلن؟
در گراف:
اینا traversal هستن، نه join
JOIN JOIN JOIN
Lucy → married_to → Alain → lives_in → London
خوانا
طبیعی
نزدیک به مدل ذهنی انسان
دوست
فالو
لایک
کامنت
📌 Facebook, LinkedIn
اینو دیدی → اونا رو هم دیدن
دوستات چی دوست دارن؟
📌 Netflix, Spotify
ارتباط مشکوک بین حسابها
پول از کجا به کجا میچرخه؟
📌 بانکها
shortest path
cheapest route
📌 Google Maps
Wiki
Knowledge Graph
📌 Google Search
Graph DB برای «data with rich relationships» است، نه برای همهچیز
❌ جایگزین همه دیتابیسها نیست
✔ کنار بقیه میدرخشه
«وقتی پرسشهای اصلی سیستم حول traversal رابطهها میچرخد، Graph DB طبیعیترین انتخاب است.»
(Neo4j، Titan، InfiniteGraph)
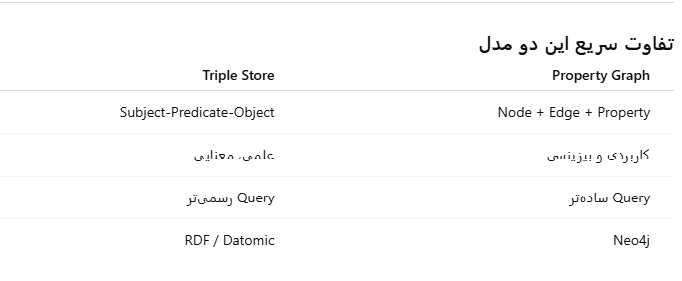
در Property Graph:
Node (Vertex) داریم
Edge (Relationship) داریم
هر دو میتونن Property داشته باشن (key-value)
مثال ذهنی
(:Person {name: "Lucy", from: "Idaho"}) -[:MARRIED_TO {since: 2015}]-> (:Person {name: "Alain", from: "France"})
ویژگی مهم
Node و Edge هر دو دیتا دارن
Edge فقط لینک نیست، خودش معنا داره
📌 خیلی نزدیک به مدل ذهنی انسان
📌 برای شبکههای اجتماعی عالی
کاربرد واقعی
Social Network
Recommendation
Fraud detection
(Datomic، AllegroGraph، RDF)
همهچیز میشه سهتایی:
(subject, predicate, object)
مثال
(Lucy, marriedTo, Alain) (Lucy, livesIn, London)
حتی ویژگیها:
(Lucy, age, 30)
ویژگی مهم
ساختار خیلی عمومی
Schema آزاد
مناسب knowledge graph
📌 رسمیتر
📌 semantic web
📌 استاندارد محور
حس و حال
Cypher طوری طراحی شده که:
Query مثل نقاشی گراف نوشته بشه
مثال
MATCH (p:Person)-[:MARRIED_TO]->(s:Person) RETURN p.name, s.name
تقریباً شبیه جملهی انگلیسی 😄
📌 خیلی خوانا
📌 محبوب برای Neo4j
حس و حال
SPARQL رسمی و استاندارده (W3C)
SELECT ?person ?city WHERE { ?person :livesIn ?city . }
📌 شبیه SQL
📌 مناسب knowledge graph و وب معنایی
تعریف ساده
Datalog یه زبان Rule-based است
ancestor(X, Y) :- parent(X, Y). ancestor(X, Y) :- parent(X, Z), ancestor(Z, Y).
📌 فکر کردن منطقی
📌 مناسب inference و تحلیل عمیق
همون حرفهای قبلی ولی در گراف:
✔ فقط میگی «چی میخوای»
✔ traversal رو engine انجام میده
✔ optimizer مسیر رو انتخاب میکنه
✔ parallelization ممکنه
g.V().has("name","Lucy").out("marriedTo").out("livesIn")
اینجا:
step به step میگی کجا بره
traversal مشخصه
📌 انعطافپذیر
❌ سخت بهینهسازی
❌ وابسته به ترتیب
پردازش گرافهای خیلی بزرگ
الگوریتم محور (PageRank)
📌 analytics
❌ query روزمره نیست
✔ اپلیکیشن
✔ query تعاملی
✔ business logic
✔ knowledge graph
✔ ontology
✔ semantic data
✔ تحلیل سنگین
✔ batch processing
✔ الگوریتمهای گرافی
Graph DB خودش یک دنیا است:
مدل داده + زبان پرسوجو + فلسفهی فکر کردن.
برای query روزمره، declarative؛ برای الگوریتم، imperative.
«Property graph برای اپلیکیشنها طبیعیتر است، در حالی که triple-store برای دادههای معنایی و inference مناسبتر است.»