
دوستدار نرمافزار، فلسفه و ادبیات. وب سایت:http://www.alihoseiny.ir
چگونه با پایتون ابرِ کلمات فارسی بسازیم؟

برای زبان پایتون پکیجهای بسیار زیادی وجود دارند که اکثر کارهای روزانهی ما را انجام میدهند. امّا مثل همیشه موقع کار با زبان فارسی، خیلی از این پکیجها خروجی درستی را به ما نمیدهند.
حالا در این نوشته میخواهیم با هم ببینیم که چطوری میتوان در پایتون ابرِ کلمات (word cloud) به زبان فارسی ساخت.
قبل از اینکه سراغ آموزش برویم، اوّل ببینم که اصلاً این ابر کلمات چیست و به چه دردی میخورد.
ابر کلمات چیست؟
ابرِ کلمات که با عناوینی مثل: tag cloud ، word cloud و weighted list هم شناخته میشود، روشی برای تجسّم دادهها است.
ابر کلمات یک عکس است که کلماتی که در یک متن حضور دارند را به ما نمایش میدهد. امّا موقع نمایش، با توجّه به میزان تکرار هر کلمه، اندازهی آن را تغییر میدهد.
یعنی هرچقدر یک کلمه بیشتر در متن ورودی حضور داشته باشد، در تصویر نهایی اندازهی بزرگتری خواهد داشت.
ابر کلمات به چه دردی میخورد؟
خب حالا یک تعریف کلّی از ابر کلمات را دیدیم. امّا داشتن این تصویر اصلاً چه دردی را از ما دوا میکند؟
ما با نگاه به ابر کلمات یک متن، خیلی سریع میتوانیم نتایج مهمی را از آن استخراج کنیم. وقتی که به ابر کلمات یک متن نگاه میکنیم، میتوانیم در یک نگاه بفهمیم که چه کلماتی بیشتر از بقیه استفاده شده اند.
مثلاً فرضکنید که شما یک نویسنده هستید. استفادهی بیش از حد از بعضی کلمات و داشتن تیکهای نوشتاری در بسیاری از اوقات موضوع خیلی بدی است. شما با دیدن ابر کلمات نوشتهی خودتان میتوانید خیلی سریع بفهمید که از چه کلماتی بیش از حد استفاده کردهاید.
یا مثلاً شما با نگاه کردن به ابر کلمات یک نوشته (مثلاً یک صفحهی وب) خیلی خیلی سریع میتوانید کلمات کلیدی آن را پیدا کنید. حالا اگر وبلاگنویس هستید، در پایان نوشته میتوانید با نگاه به ابر کلماتتان ببینید که کلمات کلیدی موردنظرتان برای آن نوشته بیشترین تکرار را داشته اند یا نه.
مثلاً تصویر زیر ابر کلمات همین نوشتهای است که الان دارید میخوانید:

اینطوری میتوانید بهتر متنتان را از نظر SEO بررسی کنید.
البته کاربردهای ابر کلمه به اینجاها ختم نمیشود. شما به کمک آن میتوانید دو نوشته را از نظر موضوعی مقایسه کنید، بدون اینکه لازم باشد آنها را بخوانید یا کلّی کار دیگر.
چطوری با پایتون ابر کلمات بسازیم؟
خب حالا فهمیدیم که ابر کلمات چیست و به چه دردی میخورد. حالا چطوری خودمان ابر کلمات متنهایی که میخواهیم را تولید کنیم؟
برای زبانهای چپچین یک ماژول خیلی معروف به نام wordcloud وجود دارد. امّا با استفادهی مستقیم از این ماژول نمیتوانید برای متنهایی که شامل زبان فارسی هستند ابر کلمه درست کنید.
به همین خاطر من یک پکیج روی این ماژول معروف به نام wordcloud-fa ساختهام. برای شروع ساخت ابر کلمهی خودمان، اوّل باید این پکیج را نصب کنیم.
نصب پکیج
از آنجایی که این پکیج روی پایتون ۳ تست شده (هنوز از پایتون ۲ استفاده میکنید؟ متأسفانه تاریخ انقضای آن گذشته است. بهتر است همین الان بیخیال آن مار پیر بشوید)، شما میتوانید خیلی راحت با این دستور این پکیج را نصب کنید:
pip3 install wordcloud-faدر اکثر قریب به اتّفاق مواقع شما لازم نیست هیچ کار دیگری بکنید. امّا اگر به هر دلیلی به مشکل خوردید، میتوانید از راهنماییهای موجود در document پکیج در گیتهاب استفاده کنید.
حالا برای ساخت ابر کلمات، یک فایل پایتون جدید درست میکنیم. من اسم فایل را example.py میگذارم، ولی شما طبیعتاً میتوانید هر اسمی که دوستدارید را روی فایلتان بگذارید.
ساخت شئ WordCloudFa
کل این پکیج یک کلاس به نام WordCloudFa است. ما برای ساخت ابر کلمه اوّل از همه باید این کلاس را import کنیم و بعد یک نمونه (instance) از آن بسازیم:
from wordcloud_fa import WordCloudFa
wc = WordCloudFa()خب این سادهترین حالت کار با این ماژول است. ما بدون دادن هیچ پارامتر اضافهای، صرفاً یک نمونه از این کلاس ساختهایم.
آمادهسازی متن ورودی
متن ورودی ما صرفاً یک string سادهی پایتون است. شما میتوانید به صورت دستی یک string درست کنید و از آن به عنوان ورودی استفاده کنید.
امّا اکثر اوقات ورودی ما متنی طولانی است که در یک فایل ذخیره شده است. برای استفاده از آن، باید محتوای فایل را به صورت یک رشتهی واحد بخوانیم:
with open('persian-example.txt', 'r') as file:
text = file.read()ما اینجا درون یک بلوک with، فایل persian-example.txt را میخوانیم و شیٔ فایل را درون متغیّری به نام file میریزیم. چرا از with استفاده میکنیم؟ چون اینطوری دیگر لازم نیست نگران بستن فایل پس از استفاده از آن باشیم.
حالا تمام محتوای موجود در فایل را با فراخوانی متد read درون متغیّر text میریزیم. وقتی از این متد استفاده میکنیم، تمام محتوای فایل به شکل یک str خوانده میشود. یعنی text یک رشتهی سادهی پایتون است.
ساخت، نمایش و ذخیرهی ابر کلمه
حالا میخواهیم از متنی که درونی متغیّر text قرار دارد یک ابر کلمه درست کنیم. ساخت ابرِ کلمه به سادگی فراخوانی یک متد است:
word_cloud = wc.generate(text)همین! الان ابر کلمهی ما ساخته شده است. حالا چطوری میتوانیم آن را مشاهده کنیم؟
image = word_cloud.to_image()
image.show()ما اوّل تصویر ابرِ کلمه را با فراخوانی متد to_image درون متغیّر image میریزیم و بعد با فراخوانی متد show روی آن تصویر، ابرِ کلمه را نمایش میدهیم.
حالا اگر بخواهیم این تصویر را ذخیره کنیم هم لازم نیست کار سختی انجام بدهیم. با یک خط کد میتوانیم خروجی را در هرجایی که دوستداریم ذخیره کنیم:
image.save('persian-example.png')حالا ابر کلمات ما درون فایلی به نام persian-example.png ذخیره شده است. به همین سادگی.
ولی ما میتوانیم کارهای خیلی بیشتری با ابرِ کلماتمان انجام بدهیم. حالا که نحوهی سادهی کار با این پکیج را یادگرفتیم، میتوانیم کارهای جالبتر را هم ببینم.
تعیین اندازهی تصویر خروجی
در حالت پیشفرض، طول و عرض تصویر خروجی به ترتیب ۴۰۰ و ۲۰۰ پیکسل است. خب خیلی اوقات ما نیازداریم که تصویر خروجی بزرگتر باشد. برای این کار خیلی راحت موقع ساختن نمونه (instance) از کلاس WordCloudFa میتوانیم طول و عرض تصویری که میخواهیم بگیریم را تعیین کنیم.
مثلاً در مرحلهی ابتدایی مثال قبلی، اگر بخواهیم خروجی تصویری ۱۲۰۰ × ۸۰۰ باشد، میتوانیم از این کد استفاده کنیم:
wc = WordCloudFa(width=1200, height=800)حالا اگر این کد را اجرا کنیم، حاصل میشود یک تصویر ۱۲۰۰ × ۸۰۰ مثل عکس زیر:

تغییر رنگ زمینه
در حالت عادی رنگ پسزمینهی ابر کلمات سیاه است. برای اینکه رنگ آن را عوض کنیم، میتوانیم مقدار background_color را هنگام ساخت نمونهی WordCloudFa تعیین کنیم.
wc = WordCloudFa(background_color="white")در این حالت پسزمینهی تمامی ابر کلماتی که توسّط این شئ ساخته میشوند سفید خواهد بود.
تغییر فونت
اگر استفاده از فونت پیشفرض را دوستندارید، میتوانید پارامتر font_path را موقع ساخت شئ تعیین کنید. مقدار این پارامتر باید path فونتی باشد که دوستدارید استفاده بشود. حواستان باشد که فونتی که انتخاب میکنید باید از زبان فارسی پشتیبانی کند. اگر در متنتان کلمات انگلیسی هم وجود دارند، فونتتان باید بتواند از آن هم پشتیبانی بکند.
wc = WordCloudFa(font_path="fontfile.ttf")فونت پیشفرض قابلیّت پشتیبانی از زبانهای فارسی و انگلیسی را دارد.
استفاده از ماسک
حالا چه میشود اگر ما نخواهیم از فرمت مستطیلی پیشفرض استفاده کنیم؟ مثلاً تصور اوّل همین نوشته را ببینید. کلمات درون نقشهی ایران قرار گرفته اند.
برای اینکه ابر کلمههایی مثل این بسازیم، به استفاده از یک تصویر ماسک نیاز داریم. تصویر شما باید یک تصویر سیاه و سفید باشد. بخشهای سیاه همان بخشهایی هستند که کلمات درونشان قرار میگیرند.
مثلاً این ماسک تصویر ابتدای این نوشته است:
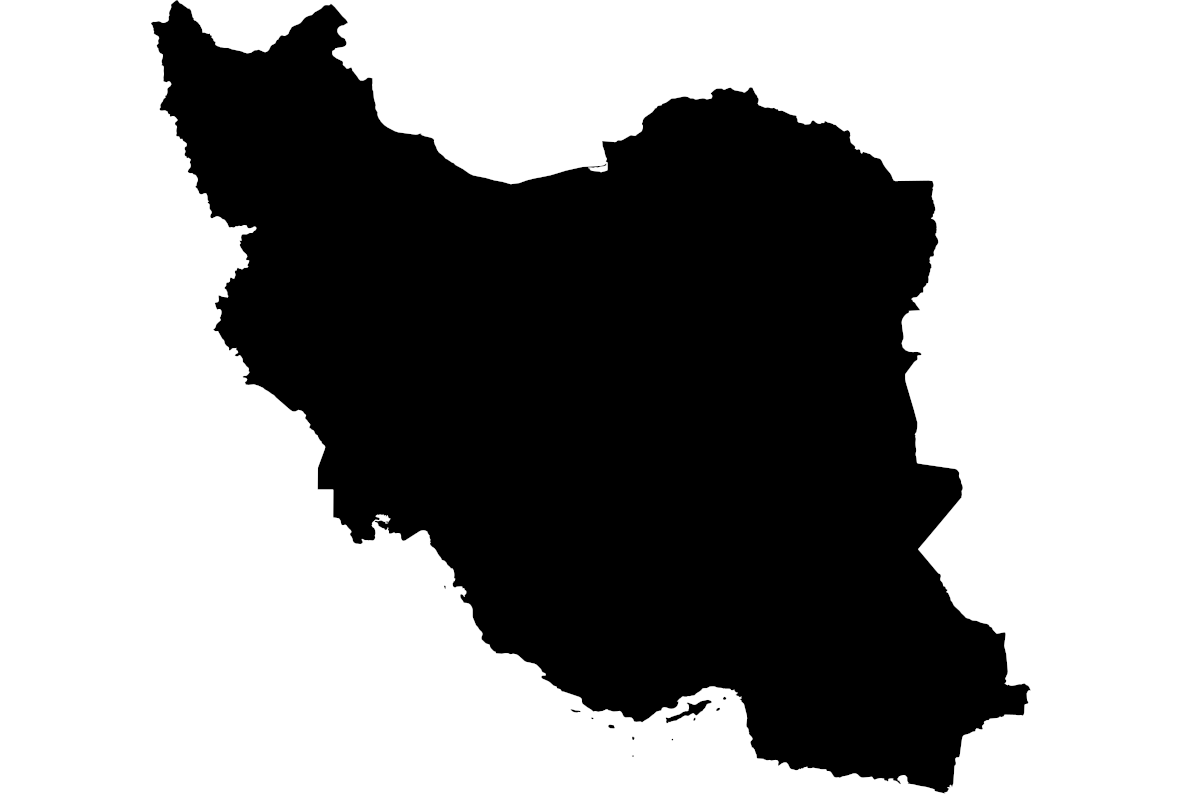
خب حالا میخواهیم این تصویر را به عنوان ماسک به WordCloudFa بدهیم. برای این کار باید تصویر را به یک آرایهی numpy تبدیل کنیم.
لازم نیست نگران باشید، کاری که میخواهیم بکنیم خیلی خیلی ساده است:
import numpy as np
from PIL import Image
mask_array = np.array(Image.open("maskImage.png"))کاری که میکنیم خیلی ساده است. ابتدا با استفاده از Image.open ماژول PIL تصویر را میخوانیم و بعد با استفاده از تابع array ماژول numpy خروجی آن را به یک آرایه تبدیل میکنیم.
لازم هم نیست نگران نصب ماژولهای PIL و numpy باشید. با نصب ماژول wordcloud-fa هر دو به صورت پیشفرض نصب میشوند.
حالا که ما تصویر ماسک را به یک آرایه تبدیل کردیم، میتوانیم آن را موقع ساخت نمونهی WordCloudFa به عنوان mask معرّفی کنیم:
wc = WordCloudFa(mask=mask_array)فقط حواستان باشد که موقع استفاده از ماسکها، اندازهی ابر کلمات نهایی اندازهی تصویر ماسک خواهد بود و تعیین کردن مقادیر width و height اندازهی خروجی را تغییر نمیدهد.
Normalize کردن متن ورودی
شما میتوانید از WordCloudFa بخواهید که متن ورودی را normalize کند. یعنی حروف عربی را با حروف فارسی جایگزین کند، از نیمفاصله استفاده کند و نویسهها را اصلاح کند تا متن شما یکدست شود.
این ماژول برای این کار از ماژول hazm استفاده میکند. برای اینکه قبل از تولید ابر کلمات، متنتان normalize شود، کافی است موقع ساخت نمونه از WordCloudFa، مقدار پارامتر persian_normalize را برابر با True قرار بدهید:
wc = WordCloud(persian_normalize=True)حذف اعداد
ما میخواهیم از کلمات موجود در متن ابر کلمه بسازیم. پس بهتر است که اعداد را از نوشته حذف کنیم. برای این کار، میتوانیم پارامتر include_numbers را موقع ساخت نمونه از WordCloudFa برابر با False بگذاریم. اینطوری تمامی اعداد فارسی، انگلیسی و عربی از متن حذف میشوند و سپس ابر کلمات از آن ساخته میشود:
wc = WordCloudFa(include_numbers=False)ساخت ابر کلمات از بسامد آنها
در حالت کلّی ما متن را به متد generate میدهیم و خود ماژول بسامد یا همان فرکانس کلمات را محسابه میکند و با استفاده از آن ابر کلمات را تولید میکند.
امّا اگر فرکانس کلمات را از قبل دارید و حالا میخواهید از روی آن ابر کلماتتان را بسازید، کافی است که به جای generate از متد generate_from_frequencies استفاده کنید.
اگر هم میخواهید فرکانس کلمات یک متن را دریافت کنید، میتوانید این کار را با فراخوانی متد process_text انجام بدهید.
wc = WordCloudFa()
frequencies = wc.process_text(text)
word_cloud = wc.generate_from_frequencies(frequencies)ما در اینجا ابتدا با استفاده از process_text فرکانس کلمات موجود در text را گرفتیم و آن را درون متغیّر frequencies ریختیم. سپس با استفاده از متد generate_from_frequencies ابر کلمات را از روی بسامد ساخته شده ایجاد کردیم.
کلمات ممنوعه
کلمات ممنوعه یا stopwords کلماتی هستند که ما نمیخواهیم آنها را درنظر بگیریم. چرا؟ چون بیش از حد استفاده میشوند و از منظر کاربرد ما، بیمعنی هستند.
کلماتی مثل: در، به، را، از،و ، است و … کلماتی هستند که ما دوستنداریم آنها را در ابر کلماتمان ببینیم.
به صورت پیشفرض، WordCloudFa کلماتی را به عنوان کلمات ممنوعه درنظر میگیرد که میتوانید لیست آنها در این لینک ببینید.
اگر میخواهید کلماتی را به این لیست اضافه کنید، خیلی راحت میتوانید از متد add_stop_words استفاده کنید:
wc = WordCloudFa()
wc.add_stop_words(['کلمهی اول', 'کلمهی دوم'])از این به بعد مقادیری که در لیست ورودی به این متد هستند در شمارش نهایی ما درنظر گرفته نمیشوند.
اگر هم نمیخواهید کلاً از کلمات ممنوعهی پیشفرض استفاده نکنید، میتوانید کلمات ممنوعهی خود را به صورت یک set موقع ساخت نمونه از WordCloudFa به آن بدهید:
stop_words = set(['کلمهی اول', 'کلمهی دوم'])
wc = WordCloudFa(stopwords=stop_words)اگر هم کلاً نمیخواهید کلمهی ممنوعهای داشته باشید میتوایند یک set خالی را به عنوان مقدار پارامتر stopwords قرار بدهید.
خب در این نوشته با هم بخش بزرگی از تواناییهای این پکیج آشنا شدیم. حالا میتوانید خیلی سریع و بدون مشکل از متنهایی که شامل کلمات فارسی، عربی و انگلیسی میشوند ابر کلمات درست کنید.
اگر از این پروژه خوشتان آمده یا بهدردتان خورده است، میتوانید با رفتن به مخزن پروژه در گیتهاب به آن ستاره بدهید تا افراد بیشتری بتوانند آن را پیداکنند.
مطلبی دیگر از این انتشارات
۲۴ تله ی رایج در اسکرام (بخش اول)
مطلبی دیگر از این انتشارات
راه اندازی NEXUS OSS برای مدیریت Dependecy های Java
مطلبی دیگر از این انتشارات
آموزش زبان برنامهنویسی Rust – قسمت۱۳- شروع کار با Enumeration ها