
شروع Machine Learning با استفاده از scikit-learn در IOS
این نوشته توسط عطیه غفارلوی مقدم و من نوشته شده است:)
مقدمه:
وقتی دربارهی استفاده از ماشین لرنینگ در برنامه نویسی موبایل حرف میزنیم، منظور استنتاج و یا پیشگویی دادههای کاربر به کمک یک مدل یادگیری ماشین pre-trained شدهاست.
توسعه دهندگان ios برای آن که بتوانند چنین ابزاری در اختیار کاربران خود قرار دهند و به مدلهای trained شده دسترسی پیدا کنند ۳ انتخاب دارند:
۱- استفاده از CoreML : که امکان دسترسی به مدل های trained شده را به صورت local (محلی) و بر روی دستگاه کاربر برای او فراهم میکند.
۲- ذخیره سازی مدل یادگیری ماشین در یک cloud : که نیازمند این است که دادهها به آن cloud ارسال کرده و سپس نتیجه لازم را دریافت نماییم.
۳- استفاده از سرویسهای مدیریت ابری یادگیری ماشین مبتنی بر API: در این روش مدل های trained شده از پیش تعریف شدهای در آن سرویسها ذخیره و مدیریت شدهاند و دادههای کاربران از طریق فراخوانی API به آن سرویسها ارسال میشود و پیشبینی و استنتاج لازم را دریافت میکنند.
در این آموزش ما از روش اول یعنی استفاده از CoreML برای به کاربردن ماشین لرنینگ در اپلیکیشن ios خود استفاده میکنیم. ابتدا تولید این مدل با استفاده از scikit-learn را شرح میدهیم و سپس به استفاده از آن در اپلیکیشن خود میپردازیم.
نیازمندیهای تکنیکال:
به منظور استفاده از چارچوب CoreML حداقل به ios 11 نیاز دارید. همچنین برای استفاده از scikit-learn در این آموزش از Anaconda با python2 استفاده میکنیم. به علاوه ورژن XCode مورد استفاده 9 میباشد که بر اساس Swift4 است.
(این ورژن از xcode قابل استفاده بر روی Mac در ماشین مجازی نیز میباشد.)
توضیح اپلیکیشن:
با توجه به آنکه هدف این آموزش بیشتر استفاده از ویژگی CoreML در ios است، توضیحات فنی اپلیکیشن در این بخش آورده نمیشوند و تنها به توضیح کلی و هدف آن اپلیکیشن میپردازیم.
این اپلیکیشن را میتوانید از اینجا دانلود کنید.
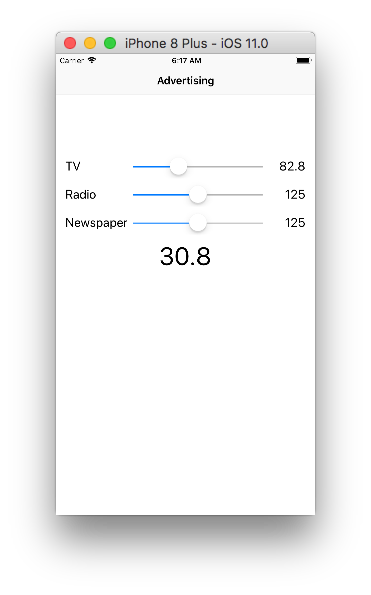
این اپلیکیشن با هدف استفاده از یادگیری ماشین در پیشبینی افزایش فروش حاصل از تبلیغات ایجاد شدهاست. فرض کنید که در طی سالیان گذشته هزینههای صرف شده در تبلیغات در سه پلتفرم تلویزیون، رادیو و روزنامه (بر اساس هزار دلار) را به همراه افزایش فروشی (بر حسب هزار واحد) که هر کدام، سبب آن بودهاند، ثبت نمودهاید.

همانطور که مشاهده میکنید، این اپلیکیشن یک صفحه داشته که شامل سه اسلایدر است که هر کدام هزینه صرف شده در هر پلتفرم تبلیغاتی است و در پایین آنها میزان فروش نمایش داده میشود. این عدد ابتدا به طور ثابت 0 گذاشته شده است و سپس با استفاده از مدل یادگیری ماشینی که آن را ایجاد میکنید مقدار فروش را پیش بینی خواهد کرد.
نصب Anaconda:
ابزار Anaconda یک جعبه ابزار مجهز به منظور کار با هزاران بسته و کتابخانه به صورت متن باز است که به کاربران خود امکان استفاده از محبوبترین ابزارهای یادگیری ماشین و علوم داده را میدهد. برای نصب Anaconda میتوانید از این لینک استفاده کنید. هنگامی که فرایند نصب را طی کردید بررسی کنید که آیا نصب با موفقیت انجام شدهاست و یا خیر.
نصب ابزارهای انجمن CoreML:
آناکوندا به خودی خود coremltools را ندارد. coremltools همان پروژه متن باز شرکت اپل است که در این آموزش برای تبدیل مدل ایجاد شده به وسیلهی scikit-learn به فرمتی قابل استفاده در اپلیکیشن ios خود از آن استفاده میکنید.
در ترمینال دستور زیر را به منظور نصب این بسته وارد کنید:
کار با jupyter notebook
بعد از نصب موارد مورد نیاز نوبت به کار با jupyter notebook میرسد. دو دستور زیر را در ترمینال بزنید:
mkdir notebooks
./anaconda2/bin/jupyter notebook notebooksدستور اول یک دایرکتوری notebooks میسازد و دستور دوم ژوپیتر را در این دایرکتوری باز میکند. بعد از زدن این دستور باید به طور خودکار یک صفحه در مرورگر باز شود که همان صفحه ی ژوپیتر است. اگر باز نشد، یک URL در ترمینال میدهد که میتوانید به صورت دستی آن را در مرورگر باز کنید. این آدرس معمولا به صورت زیر است:
http://localhost:8888/?token=305b51e1e3553993c373f2f9e930ffb93a9b6a81d373c517 سپس، در ژوپیتر به صورت زیر یک فایل بسازید و از منوی file در بالای صفحه ی باز شده نام آن را به Advertising تغییر دهید. در این فایل میتوانید همه ی آنچه که در یک فایل پایتون اجرا میکنید را اجرا کنید.در مرحله ی بعد باید یک مدل رگرسیون خطی برای پیش بینی درآمد تبلیغات بسازیم.
یادگیری و تایید یک مدل رگرسیون خطی
دادهی advertising.csv را دانلود کنید. این داده مربوط به فروش حاصل از تبلیغات در سه رسانه ی مختلف است. برای وارد کردن این داده در ژوپیتر ابتدا کتابخانه ی pandas را import کنید:
import pandas as pdکتابخانه ی pandas یک کتابخانه ی تحلیل داده است که برای تغییر داده، اضافه کردن و مرتب کردن آن به کار میرود. Pandas یک کتابخانه ی کاربردی است چراکه دادههای دنیای واقعی معمولا داده آمادهی استفاده نیستند و باید آنها را برای ماشین یادگیرنده مرتب کنیم. در کد زیر ابتدا فایل دادهها را اضافه میکنیم و بعد آن به فرمت pandas درمیآوریم. این فرمت یک فرمت استاندارد و قابل استفاده در بسیاری از کتابخانههای یادگیری ماشین است.
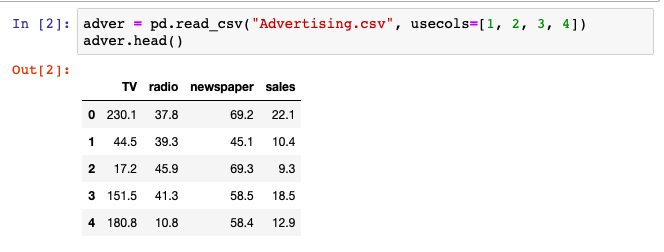
adver = pd.read_csv("Advertising.csv", usecols=[1, 2, 3, 4])
adver.head()خروجی کد بالا چند خط ابتدایی داده است که نشان میدهد چقدر برای تبلیغات تلویزیون رادیو و روزنامه هزینه شده و میزان فروش منتج شده در آن بازه چقدر است.
در کد بعدی قسمت های ورودی و خروجی داده را مشخص میکنیم قسمت ورودی داده شامل اطلاعات سرمایه گذاری های انجام شده روی هر رسانه است و اطلاعات خروجی هم شامل میزان فروش حاصل از این سرمایه گذاری است. این دو قسمت را با متغییر های X و y جدا میکنیم.
X, y = adver.iloc[:, :-1], adver.iloc[:, -1]همانطور که میدانید برای اینکه یک داده را به درستی یادگیری و تایید کنیم؛ لازم است داده را به دو قسمت داده های آموزش و داده های تست تقسیم کنیم.
- دادههای آموزش: برای آموزش مدل استفاده میشوند و نمونهها همراه با نتیجه به عنوان ورودی به الگوریتم های یادگیری ماشین داده میشوند.
- دادههای تست: این داده ها برای ارزیابی مدل به کار میروند. و از آنجایی که مقدار فروش برای دادههای تست هم مشخص است، داده های تست مشخص میکنند که مدل چقدر خوب ساخته شده است و این مقدار را به صورت یک نمره خروجی میدهند.
در کتابخانه ی scikit-learn یک تابع ساده برای تقسیم دادهها به دو دستهی آموزش و تست وجود دارد. ابتدا در cell ابتدایی ژوپیتر این کتابخانه را اضافه کنید:
import sklearn.model_selection as msسپس cell اول را با control-Enter اجرا کنید. و بعد کد زیر را برای تقسیم دادهها در آخرین cell اجرا کنید:
X_train, X_test, y_train, y_test = ms.train_test_split(X, y, test_size=0.25, random_state=42)این تابع چهار خروجی دارد :
- مجموعه دادهی ورودی آموزش
- مجموعه دادهی خروجی آموزش
- مجموعه دادهی ورودی تست
- مجموعه دادهی خروجی تست
و همچنین چهار مقدار ورودی میگیرد که عبارتند از:
- متغیرهای X و y که دادههای ورودی و خروجی به دست آمده از فایل advertising.csv هستند.
- اندازهی دادهی تست: درصد داده ای که برای تست مورد استفاده قرار میگیرد. این درصد به طور معمول بین ۲۵ تا ۴۰ درصد است.
- حالت رندوم: اگر این مقدار را وارد نکنیم دادهی تست و آموزش به صورت رندوم از بین سطرها انتخاب میشود. در کاربرد هم باید به صورت رندوم انتخاب شود؛ اما در زمان توسعه ی برنامه و متون آموزشی خوب است که این مقدار را مشخص کنیم تا بدانیم دقیقا چه مشکلی در کدام بخش ایجاد میشود.
پس از تقسیم داده، نوبت به ساخت مدل رگرسیون خطی از دادهها میرسد. برای مطالعه ی بیشتر در خصوص رگرسیون خطی به این لینک مراجعه کنید.
ابتدا مدل خطی را از کتابخانه ی scikit_learn به cell اول اضافه کنید و آن را اجرا کنید:
import sklearn.linear_model as lmسپس در آخرین cell کد زیر را اضافه کنید:
regr = lm.LinearRegression() # 1
regr.fit(X_train, y_train) # 2
regr.score(X_test, y_test) # 3این کد ابتدا یک شی از مدل رگرسیون خطی میسازد. سپس آن را روی دادهی آموزش فیت میکند به این معنی که بهترین خطی را پیدا میکند که از دادهها عبور میکند. و در خط آخر امتیاز این مدل را روی دادهی تست مشخص میکند. در خصوص رگرسیون خطی، این امتیاز نشان میدهد که دادههای خروجی پیش بینی شده چقدر نزدیک به دادههای اصلی هستند. در مورد مدل ما همانطور که در شکل زیر میبینید این امتیاز ۰.۸۹ است.
حالا میشود این مدل را برای پیش بینی به ازای هر ورودی دلخواه به کار برد. در کد زیر این مدل regr برای پیش بینی داده های x_new به کار رفته است:
X_new = [[ 50.0, 150.0, 150.0], [250.0, 50.0, 50.0], [100.0, 125.0, 125.0] ]
regr.predict(X_new)همانطور که در عکس زیر مشاهده میکنید خروجی به صورت یک آرایه از مقادیر است و نشان میدهد که به عنوان مثال اگر ۵۰ هزار دلار روی تلویزیون، ۱۵۰ هزار دلار روی رادیو و ۱۵۰ هزار دلار روی روزنامه سرمایه گذاری کنید؛ باید انتظار فروش ۳۴.۱۵۰ واحدی داشته باشید.

تبدیل مدل به فرمت Apple’s coreml
بعد از ساخت مدل، نوبت به استفاده از coremltools برای استخراج آن میرسد. ابتدا این کتابخانه را با قرار دادن کد زیر در اولین cell، به ژوپیتر اضافه کنید.
import coremltoolsو بعد کد زیر را در انتهای ژوپیتر اضافه کرده و آن را اجرا کنید:
input_features = ["tv", "radio", "newspaper"]
output_feature = "sales"
model = coremltools.converters.sklearn.convert(regr, input_features, output_feature)
model.save("Advertising.mlmodel")تابع convert دو مقدار ورودی زیر را میگیرد:
- مدل ساخته شده توسط کتابخانه ی scikit-learn
- ویژگیهای ورودی و خروجی که Xcode آن ها را برای ساختن interface کلاس سوییفت استفاده میکند.
در نهایت تابع ()save این مدل را با پسوند mlmodel. در فولدر ژوپیتر ذخیره میکند.
کد مربوط به این بخش در این لینک موجود است.
استفاده از مدل CoreML در اپلیکیشن:
فایل Advertising.mlmodel را به دایرکتوری Resources درون اپلیکیشن خود منتقل کنید.
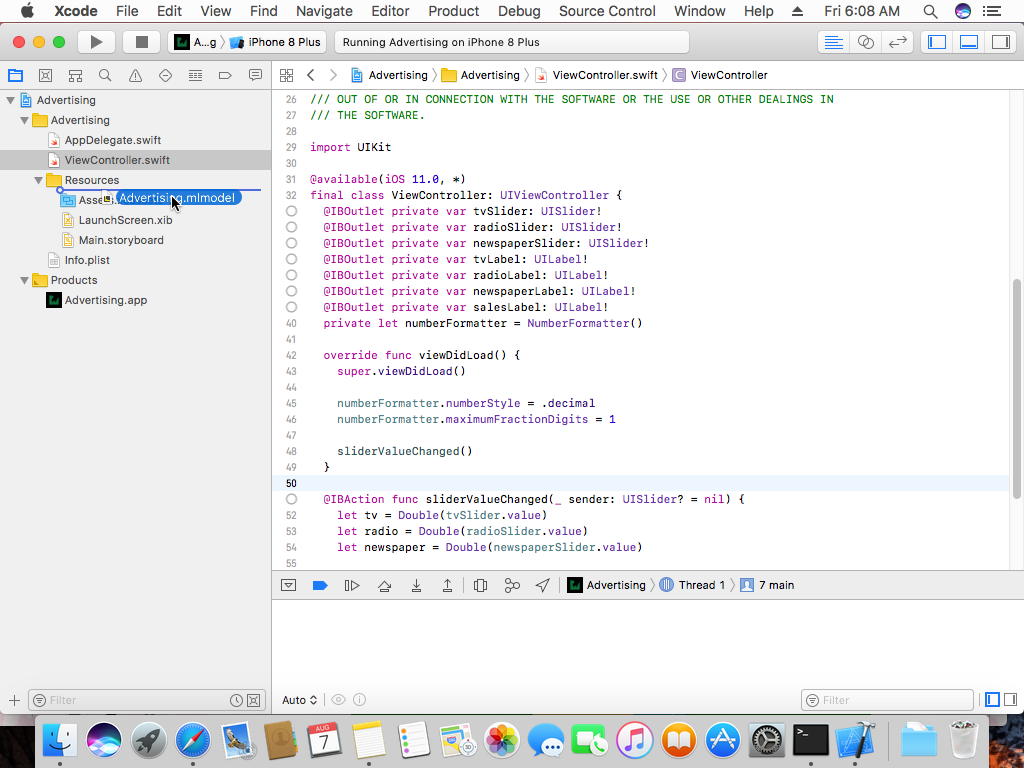
و در دیالوگی که برای انجام این انتقال به شما نشان داده میشود گزینههای Copy items if needed و Create groups و همچنین Advertising را تیک بزنید و سپس بر روی Finish کلیک کنید.
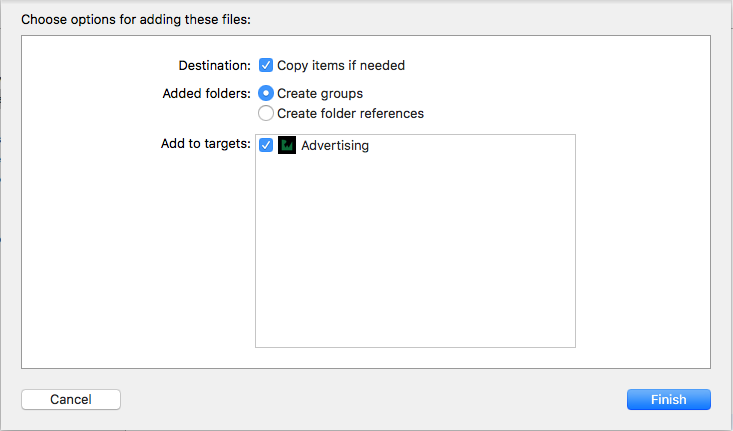
سپس بر روی فایل مدل import شده خود در project navigator کلیک کنید تا اطلاعات زیر به شما نمایش داده شوند:
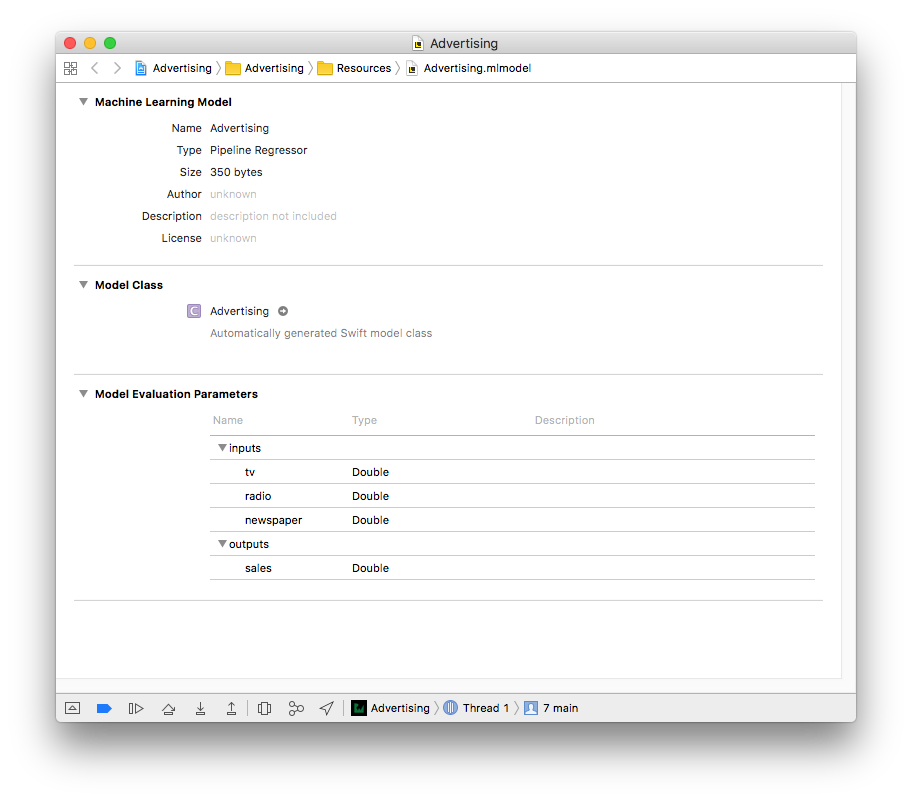
در بخش Model Class کلاسی که به طور خودکار ایجاد میشود به همراه یک فلش کوچک قابل مشاهده میباشد.
اگر در بخش Model Class پیغام "model is not part of any target. add the model to a target to enable generation of the model class" برای شما نمایش داده شد، فرایند زیر را انجام دهید:
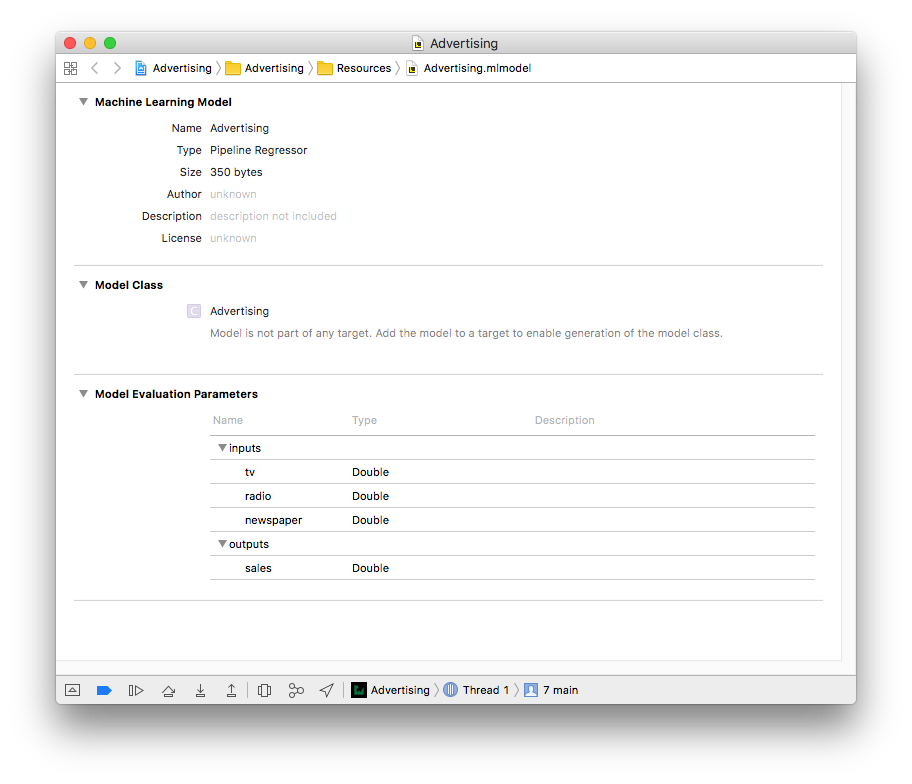
بر روی پروژه در Project navigator کلیک کنید تا تنظیمات پروژه به شما نشان داده شود. سپس در بخش Build Phases به قسمت compile sources بروید و فایل Advertising.mlmodel خود را به آنجا اضافه کنید.
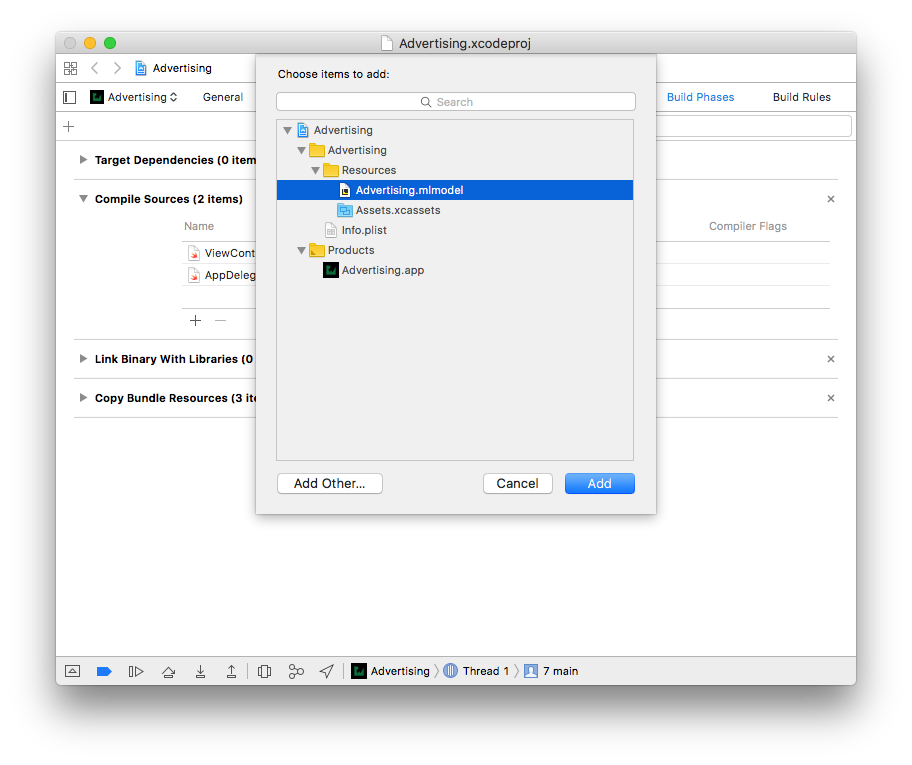
اگر بر روی فلش کوچک در عکس بالا کلیک کنید به interface ای که توسط Xcode از فایل .mlmodel شما تولید شدهاست میروید.
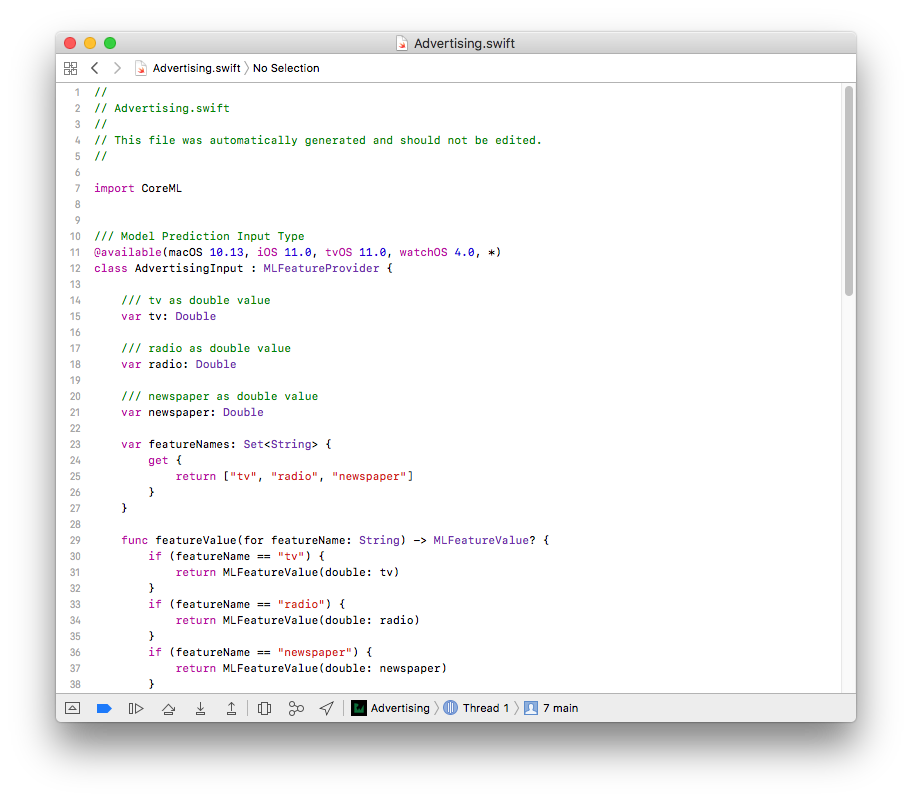
حال ViewController.swift را باز نمایید و خط مشخص شده در زیر را به آن اضافه کنید.
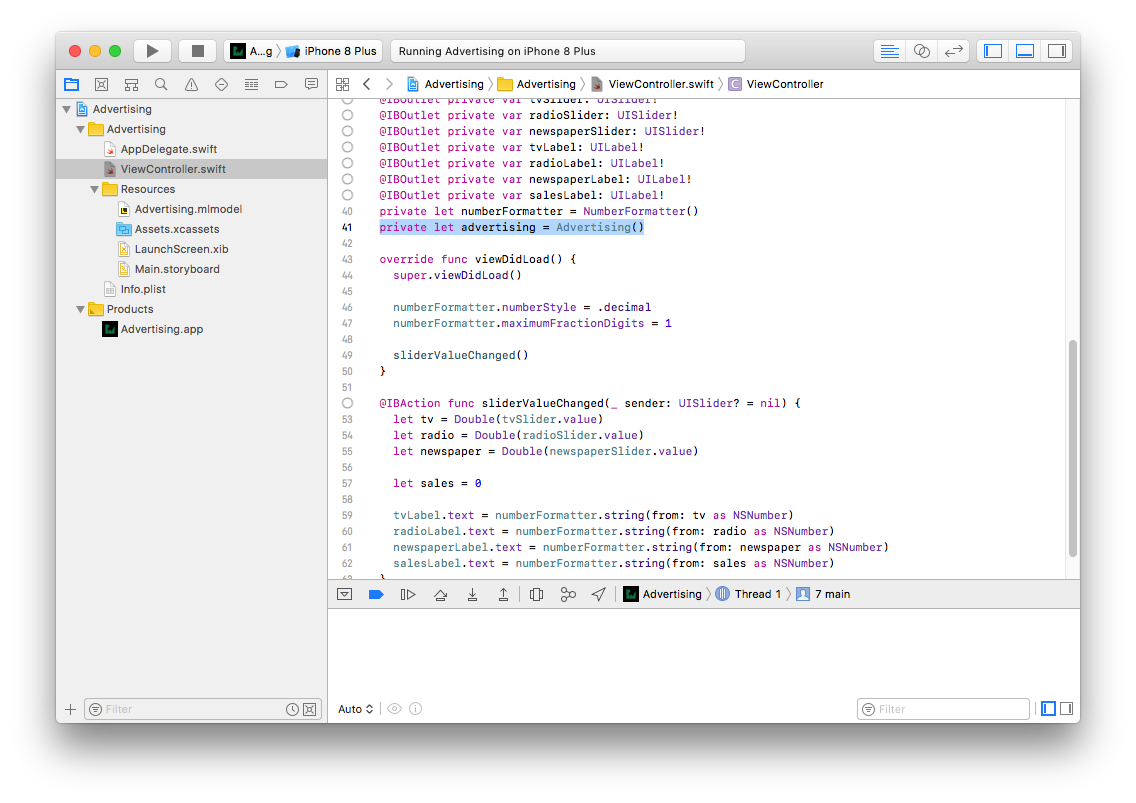
فایل را اسکرول کنید و در تعریف تابع SliderValueChanged مقدار ثابت 0 برای متغیر sales را با عبارت زیر جایگزین کنید:
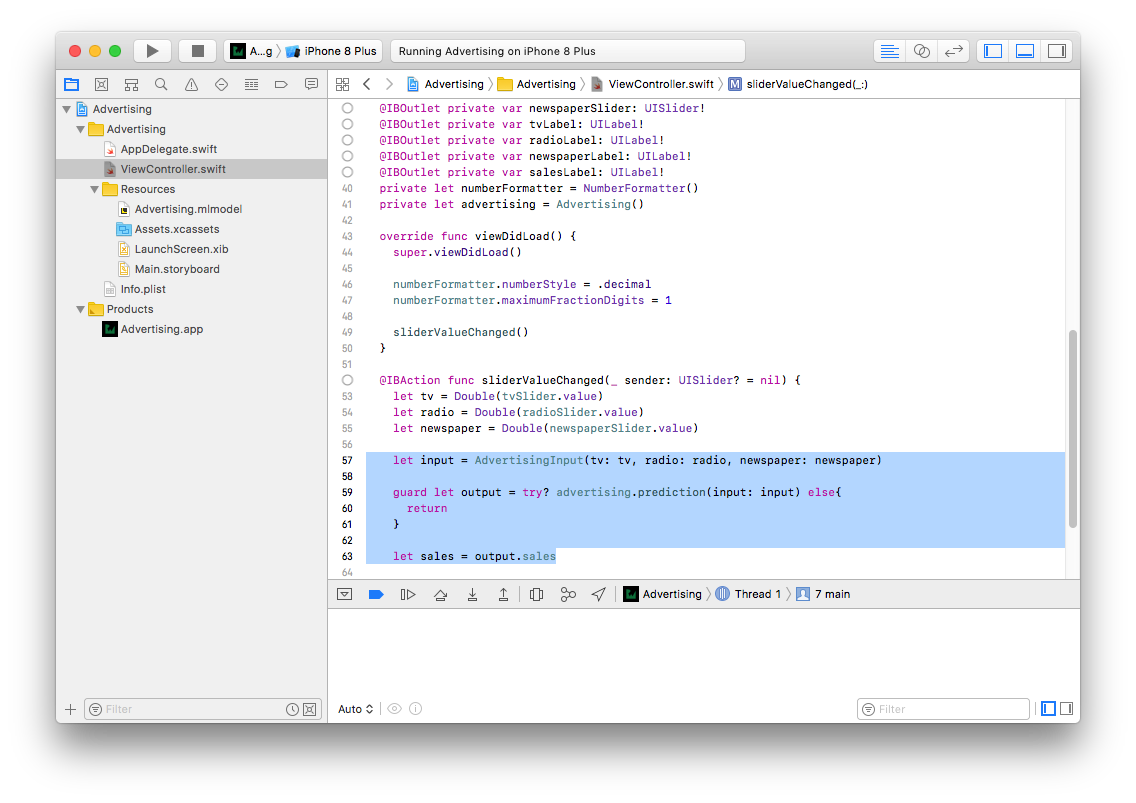
مشابه متد ()predict در scikit-learn، مدل CoreML نیز متد prediction ای دارد که ورودی را در فرمت به خصوصی به عنوان آرگومان ورودی دریافت کرده و خروجی را در فرمتی مشخص تولید میکند.
حال اپلیکیشن را دوباره Build نموده و اجرا کنید. مقدار پیشبینی فروش بر اساس سه پارامتر ورودی تغییر خواهد کرد!
منبع:
منبع اصلی ما در این نوشته این لینک بود.
مطلبی دیگر از این انتشارات
۹ روش بازاریابی دیجیتال که به کسب و کار شما رونق میبخشند
مطلبی دیگر از این انتشارات
سومین مدرسه فصلی مقدماتی هوش مصنوعی و علم داده دانشگاه تهران (مرکز نوآوری علم داده)
مطلبی دیگر از این انتشارات
ربات های نویسنده و آشنایی بهتر با آنها در عصر هوش مصنوعی