

دانشجو ارشد هوش مصنوعی توسعه دهنده (پایتون - جنگو) حوزه تحقیقاتی تخصصی: سیستم پیشنهاد دهنده شغل: توسعه دهنده تیم امنیت ایرانسل شغل دوم: مدرس پایتون
آموزش کتابخانه pandas در پایتون 2
در قسمت های پیشین تعریفی از پاندا و کار کردن با آن و در پستی دیگر تعریفی از مکعب داده نیز داشتیم.
تعریف Panel: یک آرایه سه بعدی است که دقیقا به مانند مکعب داده رفتار می کند.
تعریف مکعب داده: یک انبار داده معمولا با کمک یک ساختار چند بُعدی با نام مکعب داده مدل سازی می شود. به عبارتی یک مکعب داده، یک دید چند بُعدی را به کاربر ارائه می کند و با پیش محاسبه ی آن می توان دسترسی سریعی به داده های خلاصه شده داشت.
یک مکعب داده یا همان ظرف سه بعدی برای نگهداری داده را در پاندا به عنوان پنل می شناسند. هر پنل از سه قسمت بسیار مهم با نام های items، major_axis، minor_axis معرفی شده اند.
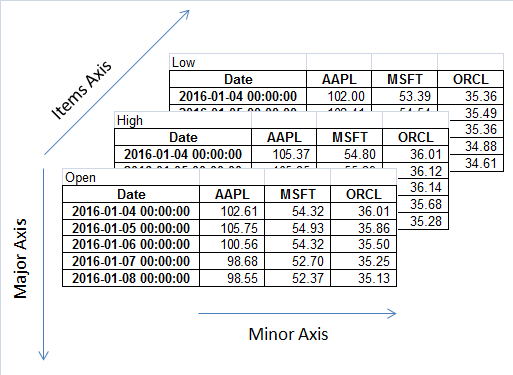
همانطور که در عکس بالا مشاهده می کنید تعریف های هر کدام از مفاهیم بالا را می توانیم به این شکل بیان کنیم:
تعریف items: در محور Z قرار می گیرد و اشاره به DataFrame های داخلی دارد.
تعریف major_axis: در محور y قرار می گیرد و اشاره به تمامی رکورد های ثبت شده در DataFrame دارد.
تعریف minor_axis: در محور x قرار می گیرد و اشاره به تمامی نام ستون های DataFrame دارد.
بسیار عالی تا اینجا مفهوم پنل را متوجه شدیم. حالا وقت آن رسیده تا وارد محیط کدنویسی شویم.
pandas.Panel(data, items, major_axis, minor_axis, dtype, copy)دقت کنید که در آرگومان data هر نوع داده ای نظیر (ndarray، series، map، lists، dict، constants و حتی DataFrame) قرار گیرد. بنابراین کاملا انعطاف پذیر می توانیم نسبت به ماجرا برخورد کنیم.
import pandas as pd
import numpy as np
data = np.random.rand(2, 4, 5)
p = pd.Panel(data)
print(p)
# Output<class 'pandas.core.panel.Panel'>
Dimensions: 2 (items) x 4 (major_axis) x 5 (minor_axis)
Items axis: 0 to 1
Major_axis axis: 0 to 3
Minor_axis axis: 0 to 4اکنون متغیر data توسط Numpy یک آرایه سه بُعدی به شکل زیر است که عدد دو نمایانگر محور Z ها، عدد چهار نشان دهنده تعداد سطرها یا به عبارتی رکورد ها و عدد پنج نشان دهنده تعداد ستون ها است.

تا اینجای کار توانستیم توسط تولید کردن یک آرایه سه بُعدی توسط Numpy یک پنل سه بعدی ایجاد کنیم. اما این حالت شاید شما را اقناء نکند و بخواهید نامی برای محور Z ها مشخص کنید. برای اینکار مثال زیر را دنبال کنید:
import pandas as pd
import numpy as np
data = {'Item1' : pd.DataFrame(np.random.randn(4, 3)),
'Item2' : pd.DataFrame(np.random.randn(4, 2))}
p = pd.Panel(data)
print(p)
#output <class 'pandas.core.panel.Panel'>
Dimensions: 2 (items) x 4 (major_axis) x 5 (minor_axis)
Items axis: 0 to 1
Major_axis axis: 0 to 3
Minor_axis axis: 0 to 4اکنون توسط یک دیکشنری موفق شدیم برای محور Z نامگذاری را انجام دهیم. اکنون به راحتی می توانید تصور کنید که در محور Z و item 1 شما یک DataFrame سه ستون و چهار رکورد دارید و در item 2 شما یک DataFrame دو ستون و چهار رکورد مطابق عکس زیر دارید:
اما شاید سوال برایتان پیش آمده باشد که چگونه می توانید به محور Z دسترسی داشته باشید و اگر دسترسی پیدا کنید، داده به شما چگونه نمایش داده می شود:
import pandas as pd
import numpy as np
data = {'Item1' : pd.DataFrame(np.random.randn(4, 3)),
'Item2' : pd.DataFrame(np.random.randn(4, 2))}
p = pd.Panel(data)
print(p['Item1']) 0 1 2
0 0.488224 -0.128637 0.930817
1 0.417497 0.896681 0.576657
2 -2.775266 0.571668 0.290082
3 -0.400538 -0.144234 1.110535اکنون به راحتی مشاهده می کنید که در item 1 ما یک DataFrame داریم که به مانند یک جدول رفتار می کند. برای درک بهتر مسئله می توانید به عکسی که در ابتدای پست قرار داده شد، توجه کنید.
برای دسترسی به محور Major_axis شما کافیست بصورت زیر عمل کنید:
import pandas as pd
import numpy as np
data = {'Item1' : pd.DataFrame(np.random.randn(4, 3)),
'Item2' : pd.DataFrame(np.random.randn(4, 2))}
p = pd.Panel(data)
print(p.major_xs(1))
Item1 Item2
0 0.417497 0.748412
1 0.896681 -0.557322
2 0.576657 NaNبرای دسترسی به محور major_axis کافیست از شیئ ساخته شده تنها major_xs را صدا بزنید و نام آن ستون را بگویید. در این حالت به شما تعداد ستون ها را در سمت چپ مشخص کرده است که سه ستون داریم و در بالا نام هر جدول را برای ما مشخص کرده است که به عبارتی محور Z ها است و در نهایت ما 5 رکورد داشتیم اما در خروجی کنونی ما می تواند 6 رکورد را نمایش دهد به همین دلیل است که مقدار Nan در آخرین مختصات قرار گرفته است.
توجه: برای اینکه بتوانید راحت درک کنید با خودتان تعداد محور ها را مرور کنید و به عکس اول پست توجه کنید در نهایت خروجی را مشاهده کنید. با یک نتیجه گیری ساده موفق می شوید تا تمامی مفاهیم گفته شده را درک نمایید.
برای نمایش محور minor_axis کافیست به شکل زیر برخورد کنیم:
import pandas as pd
import numpy as np
data = {'Item1' : pd.DataFrame(np.random.randn(4, 3)),
'Item2' : pd.DataFrame(np.random.randn(4, 2))}
p = pd.Panel(data)
print p.minor_xs(1)
Item1 Item2
0 -0.128637 -1.047032
1 0.896681 -0.557322
2 0.571668 0.431953
3 -0.144234 1.302466در حال حاضر به نظر می رسد که کامل مسئله را درک کرده باشید و بنده می خواهم به شما نشان دهم تا به خوبی یاد گرفته ام.
در بالای خروجی محور Z ها را دارم که نام دو جدول را برای من نگهداری کرده است.
در سمت چپ خروجی محور y ها را دارم که رکورد های من را نمایش می دهد.
در میان خروجی به عبارتی مقدار دهی سطر و ستون مقدار ستون یکم را برای من نگهداری کرده است.
در واقع به من می گوید در جدول item 1 شما در سطر صفرم در ستون یکم (ستون یکم را توسط تابع minor_xs مشخص کردیم) مقدار 0.128637- را داریم. یا به عنوان مثال در جدول item 2 در سطر سوم (اندیس 2) مقدار 0.431953 را داریم.
در پست بعدی با ضمن یادگیری وارد کردن داده از طریق فایل های excel و با استفاده از داده واقعی اینکار را مجددا انجام می دهیم و همچنین توضیح می دهیم که چرا از پنل استفاده می کنیم.
توجه: آیا مطلب برایتان مفید بوده است؟ درصورت مفید بودن و درک مطلب نظر خود را وارد نمایید.
توجه: درصورتیکه هر قسمتی را متوجه نشدید، می توانید سوال بپرسید.
مطلبی دیگر از این انتشارات
CRISP-DM فرآیند اجرای پروژههای دادهکاوی
مطلبی دیگر از این انتشارات
آینده از آن بات ها است
مطلبی دیگر از این انتشارات
مجموعه کاملی از فوت و فن های کار با Jupyter Notebook - بخش 1/4