

خنیاگر غمگین
ReadySet انقلابی در کش کردن پاسخ دیتابیس

مقدمه
در دنیای دیجیتال که سرعت و پاسخگویی حرف اول را میزند، عملکرد برنامههای بکاند نقشی حیاتی در جلب رضایت کاربران ایفا میکند. پایگاه داده، بهعنوان قلب تپنده بسیاری از این برنامهها، اغلب به دلیل حجم بالای پرسوجوها یا پیچیدگی آنها به گلوگاه عملکرد تبدیل میشود. تأخیر در پاسخگویی به پرسوجوها میتواند تجربه کاربری را مختل کند، فروش را کاهش دهد یا حتی مشکلات عملیاتی جدی ایجاد کند. برای مثال، در یک پلتفرم تجارت الکترونیک، جستجوی کند محصولات میتواند مشتریان را ناامید کند، یا در برنامههای رسانههای اجتماعی، بارگذاری کند فیدها باعث کاهش تعامل کاربران میشود.
برای رفع این مشکلات، توسعهدهندگان به روشهای سنتی مانند کشینگ دستی، استفاده از replicaهای خواندنی و بهینهسازی پرسوجوها روی آوردهاند. اما این روشها اغلب پیچیده، زمانبر و با محدودیتهای مقیاسپذیری همراه هستند. در این میان، ReadySet بهعنوان یک موتور کشینگ SQL نوآورانه وارد صحنه شده است که میتواند عملکرد پایگاههای داده MySQL و PostgreSQL را تا 100 برابر بهبود بخشد، بدون نیاز به تغییر کد برنامه یا ساختار پایگاه داده.
در این مقاله، ابتدا تأثیر سرعت پایگاه داده بر برنامههای بکاند را بررسی میکنیم، سپس روشهای قدیمی بهبود عملکرد را مرور میکنیم، ReadySet و مزایای آن را معرفی میکنیم، نحوه عملکرد آن و استفاده از گراف دادهای را توضیح میدهیم و در نهایت آن را با روشهای مشابه از نظر مقیاسپذیری، سرعت و سهولت پیادهسازی مقایسه میکنیم.
تأثیر سرعت پایگاه داده بر برنامههای بکاند
پایگاه داده یکی از اجزای اصلی برنامههای بکاند است که وظیفه ذخیره، بازیابی و بهروزرسانی دادهها را بر عهده دارد. سرعت پاسخگویی پایگاه داده مستقیماً بر عملکرد کلی برنامه تأثیر میگذارد. وقتی یک کاربر درخواستی مانند بارگذاری یک صفحه وب، جستجوی محصول یا ارسال فرم را انجام میدهد، برنامه باید پرسوجوهایی را به پایگاه داده ارسال کند. اگر این پرسوجوها کند باشند، تأخیر در پاسخگویی ایجاد میشود که میتواند تجربه کاربری را به شدت تحت تأثیر قرار دهد.
به عنوان مثال:
در یک برنامه تجارت الکترونیک، جستجوی کند محصولات میتواند باعث تأخیر در بارگذاری صفحه شود و مشتریان را از خرید منصرف کند.
در پلتفرمهای رسانههای اجتماعی، فیدهای کند میتوانند کاربران را از تعامل با برنامه بازدارند.
در برنامههای مالی، تأخیر در پردازش تراکنشها میتواند منجر به از دست دادن فرصتها یا مشکلات انطباق با مقررات شود.
با افزایش تعداد کاربران و حجم دادهها، بار روی پایگاه داده افزایش مییابد و مشکلات عملکردی تشدید میشوند. مقیاسپذیری پایگاه داده برای مدیریت این بار اضافی معمولاً نیازمند افزودن سختافزارهای گرانقیمت یا بهینهسازی پیچیده پرسوجوهاست که هر دو زمانبر و پرهزینه هستند.
روشهای قدیمی برای بهبود عملکرد پایگاه داده
برای مقابله با چالشهای عملکرد پایگاه داده، توسعهدهندگان از روشهای مختلفی استفاده کردهاند که هر کدام مزایا و معایب خاص خود را دارند:
1. کشینگ دستی
کشینگ دستی شامل ذخیره دادههای پراستفاده در یک سیستم سریع مانند Redis یا Memcached است تا تعداد پرسوجوهای ارسالی به پایگاه داده کاهش یابد. این روش میتواند عملکرد را بهبود بخشد، اما مدیریت invalidation کش—یعنی بهروزرسانی دادههای کش شده هنگام تغییر دادههای اصلی—پیچیده و مستعد خطاست. توسعهدهندگان باید منطق سفارشی برای مدیریت کش بنویسند که میتواند منجر به ناسازگاری دادهها یا اشکالات برنامهنویسی شود.
2. Replicaهای خواندنی
بسیاری از پایگاههای داده از replicaهای خواندنی پشتیبانی میکنند که کپیهایی از پایگاه داده اصلی هستند و پرسوجوهای خواندنی را مدیریت میکنند. این روش بار خواندنی را از پایگاه داده اصلی تخلیه میکند و عملکرد را بهبود میبخشد. با این حال، replicaهای خواندنی ممکن است با تأخیر replication مواجه شوند، که منجر به مشکلات consistency eventual میشود، یعنی دادههای روی replica ممکن است بهروز نباشند. علاوه بر این، راهاندازی و نگهداری replicaها نیازمند زیرساخت اضافی و مدیریت پیچیده است.
3. بهینهسازی پرسوجو
بهینهسازی پرسوجوهای SQL و ایندکسهای پایگاه داده میتواند عملکرد را بهطور قابل توجهی بهبود بخشد. این فرآیند شامل تجزیه و تحلیل برنامههای اجرای پرسوجو، افزودن ایندکسهای مناسب و گاهی بازنویسی پرسوجوهاست. اگرچه این روش مؤثر است، اما نیاز به دانش عمیق از ساختار پایگاه داده دارد و با افزایش حجم دادهها یا تغییر الگوهای پرسوجو، نیاز به بهینهسازی مداوم دارد.
این روشها، هرچند مفید، اغلب با پیچیدگیهای پیادهسازی، هزینههای زیرساختی بالا و چالشهای حفظ consistency دادهها همراه هستند.
معرفی ReadySet
ReadySet یک موتور کشینگ SQL است که بهعنوان یک لایه شفاف بین برنامه و پایگاه دادههای MySQL یا PostgreSQL عمل میکند. این ابزار با کش کردن نتایج پرسوجوهای select و بهروزرسانی تدریجی آنها با تغییر دادههای اصلی، عملکرد را بهطور چشمگیری بهبود میبخشد. برخلاف روشهای سنتی، ReadySet نیازی به تغییر کد برنامه یا schema پایگاه داده ندارد و میتواند با تغییر یک connection string ساده در برنامه ادغام شود.
ویژگیهای کلیدی ReadySet عبارتند از:
سازگاری Wire: سازگار با پروتکلهای MySQL و PostgreSQL، که امکان ادغام آسان را فراهم میکند.
مدیریت خودکار کش: بهطور خودکار invalidation و بهروزرسانی کش را مدیریت میکند، و نیاز به منطق سفارشی را از بین میبرد.
مقیاسپذیری افقی: میتواند برای مدیریت ترافیک خواندنی افزایش یافته مقیاسپذیر شود.
بهروزرسانیهای بیدرنگ: دادههای کش شده را با استفاده از replication stream پایگاه داده بهروز نگه میدارد.
بدون نیاز به تغییر کد: توسعهدهندگان میتوانند بدون تغییر برنامههای موجود از ReadySet استفاده کنند.
ReadySet بر اساس تحقیقات Jon Gjengset در پایاننامه دکتری او در MIT با عنوان "Partial State in Dataflow-Based Materialized Views" توسعه یافته است و از یک رویکرد مبتنی بر گراف دادهای برای مدیریت کارآمد دادهها استفاده میکند.
نحوه عملکرد ReadySet و نگهداری دادهها بهصورت گراف
ReadySet از یک گراف دادهای (dataflow graph) برای مدیریت و نگهداری نتایج پرسوجوها بهصورت materialized views استفاده میکند. این گراف، وابستگیهای محاسباتی پرسوجوهای SQL را نشان میدهد، جایی که:
گرهها (vertices): نشاندهنده عملیاتهای محاسباتی مانند تجمیع (aggregation) یا اتصال (join) هستند.
لبهها (edges): وابستگیهای دادهای بین این عملیاتها را نشان میدهند.
فرآیند کار
کش کردن پرسوجوها: وقتی یک پرسوجو اجرا میشود، ReadySet بررسی میکند که آیا نتیجه در materialized view موجود است یا خیر. اگر موجود باشد، نتیجه بهسرعت از کش برگردانده میشود. در غیر این صورت، نتیجه بهصورت درخواستی محاسبه و در کش ذخیره میشود.
بهروزرسانیهای تدریجی: ReadySet به replication stream پایگاه داده گوش میدهد. وقتی دادههای اصلی تغییر میکنند (مثلاً افزودن یک رأی به جدول Votes)، این تغییر بهعنوان یک بهروزرسانی به گراف دادهای تزریق میشود. گرههای مربوطه در گراف بهروزرسانیهای لازم را انجام میدهند و نتایج جدید را به گرههای فرزند منتقل میکنند.
حالت جزئی (Partial State): برخلاف materialized views سنتی که تمام دادهها را ذخیره میکنند، ReadySet از حالت جزئی پشتیبانی میکند. این یعنی فقط دادههای پراستفاده در حافظه نگه داشته میشوند. اگر دادهای در کش موجود نباشد، ReadySet از upqueries استفاده میکند که بهصورت معکوس در گراف دادهای حرکت میکنند تا دادههای مورد نیاز را از جداول پایه یا سایر materialized views بازیابی کنند.
نگهداری گراف دادهای: گراف دادهای به ReadySet امکان میدهد تا بهروزرسانیها را بهصورت تدریجی و کارآمد انجام دهد. برای مثال، اگر یک رأی جدید به یک داستان اضافه شود، ReadySet فقط تعداد آرای مربوط به آن داستان را افزایش میدهد، به جای بازسازی کل materialized view.
این رویکرد مبتنی بر گراف دادهای، همراه با حالت جزئی و upqueries، به ReadySet امکان میدهد تا حافظه را بهینه استفاده کند و عملکرد را برای پرسوجوهای پیچیده بهبود بخشد.
مثال عملی
فرض کنید یک برنامه وب دارای جداول Stories و Votes است و یک پرسوجو برای شمارش تعداد آرای هر داستان اجرا میشود. ReadySet یک گراف دادهای ایجاد میکند که شامل گرههایی برای جدول پایه Votes، عملیات تجمیع (شمارش آراء) و یک گره خواننده (reader node) برای ذخیره نتایج است. وقتی یک رأی جدید اضافه میشود، ReadySet فقط تعداد آرای داستان مربوطه را بهروزرسانی میکند، که این فرآیند بسیار سریعتر از محاسبه مجدد کل پرسوجوست.
مزایای ReadySet
ReadySet مزایای متعددی نسبت به روشهای سنتی ارائه میدهد:
سهولت ادغام: با سازگاری با پروتکلهای MySQL و PostgreSQL، ReadySet میتواند با تغییر یک connection string ادغام شود، بدون نیاز به تغییر کد برنامه.
افزایش عملکرد: آزمایشها نشان میدهند که ReadySet میتواند عملکرد پرسوجوها را تا 100 برابر بهبود بخشد، با کاهش زمان پاسخگویی از 250-1500 میلیثانیه به 15-150 میلیثانیه یا حتی کمتر از یک میلیثانیه برای پرسوجوهای کش شده.
صرفهجویی در هزینه: با تخلیه بار خواندنی از پایگاه داده اصلی، ReadySet امکان کاهش اندازه instanceهای پایگاه داده یا تعداد replicaهای خواندنی را فراهم میکند، که میتواند تا 70٪ در هزینههای زیرساختی صرفهجویی کند.
مقیاسپذیری: ReadySet میتواند بهصورت افقی مقیاسپذیر شود تا ترافیک خواندنی بالا را مدیریت کند، و عملکرد را با رشد برنامه حفظ میکند.
Consistency بیدرنگ: برخلاف replicaهای خواندنی که ممکن است با تأخیر replication مواجه شوند، ReadySet دادههای کش شده را با استفاده از replication stream بهروز نگه میدارد.
بهرهوری توسعهدهنده: با حذف نیاز به منطق کشینگ سفارشی یا بهینهسازی دستی پرسوجوها، ReadySet به توسعهدهندگان اجازه میدهد تا روی توسعه ویژگیهای جدید تمرکز کنند.
مقایسه ReadySet با روشهای مشابه
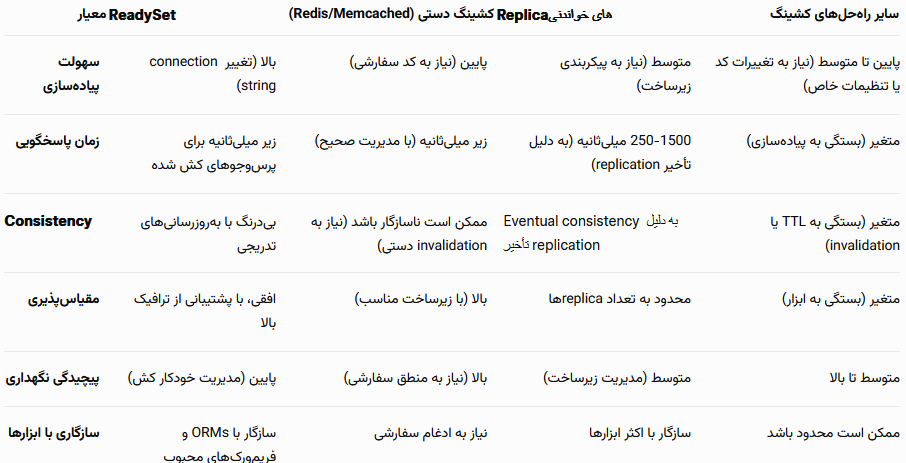
در مقابل کشینگ دستی
کشینگ دستی با ابزارهایی مانند Redis یا Memcached میتواند عملکرد بالایی ارائه دهد، اما نیاز به نوشتن کدهای پیچیده برای مدیریت invalidation و بهروزرسانی کش دارد. این فرآیند مستعد خطاست و میتواند منجر به ناسازگاری دادهها شود. ReadySet این پیچیدگی را با مدیریت خودکار کش حذف میکند و عملکرد مشابه یا بهتری را با تلاش کمتر ارائه میدهد.
در مقابل Replicaهای خواندنی
Replicaهای خواندنی بار خواندنی را از پایگاه داده اصلی تخلیه میکنند، اما تأخیر replication میتواند باعث ناسازگاری دادهها شود. همچنین، راهاندازی و نگهداری replicaها نیازمند زیرساخت اضافی و مدیریت پیچیده است. ReadySet بدون تأخیر replication، دادهها را بهروز نگه میدارد و با یک تغییر ساده در connection string قابل ادغام است.
در مقابل سایر راهحلهای کشینگ
سایر راهحلهای کشینگ ممکن است نیاز به تغییرات در کد برنامه یا الگوهای پرسوجوی خاص داشته باشند. ReadySet با شفافیت کامل و سازگاری با پرسوجوهای SQL موجود، پیادهسازی را سادهتر میکند. همچنین، بهروزرسانیهای خودکار آن نیاز به تنظیمات TTL یا invalidation دستی را از بین میبرد.
نتیجهگیری
در جستجوی عملکرد بهینه برای برنامههای بکاند، سرعت پایگاه داده یک عامل کلیدی است. روشهای سنتی مانند کشینگ دستی، replicaهای خواندنی و بهینهسازی پرسوجوها، اگرچه مفید هستند، اما با چالشهایی مانند پیچیدگی پیادهسازی، ناسازگاری دادهها و هزینههای بالای زیرساختی همراهاند.
ReadySet با ارائه یک موتور کشینگ SQL شفاف و کارآمد، این مشکلات را برطرف میکند. این ابزار با استفاده از یک گراف دادهای و مدیریت حالت جزئی، نتایج پرسوجوها را بهصورت تدریجی بهروزرسانی میکند و عملکردی تا 100 برابر بهتر، صرفهجویی در هزینهها و سهولت پیادهسازی را ارائه میدهد. برای سازمانهایی که به دنبال بهبود عملکرد پایگاه داده و کاهش هزینهها هستند، ReadySet یک راهحل ایدهآل است.
برای کسب اطلاعات بیشتر، به وبسایت ReadySet مراجعه کنید یا مخزن GitHub آن را بررسی کنید.
منابع
وبسایت رسمی ReadySet
مخزن GitHub ReadySet
پایاننامه دکتری Jon Gjengset
مقاله TechCrunch در مورد ReadySet
مطلبی دیگر از این انتشارات
خلاصه کتاب کار عمیق
مطلبی دیگر از این انتشارات
معرفی Qdrant
بر اساس علایق شما
کوکی، پوکساید و دیگر روشهای تضمینی برای بقا