
خب ما توی قسمت اول داده هامون رو بررسی کردیم و مدل رو درست کردیم. توی این مطلب میخوایم ببینیم چطور میتونیم عملکرد مدل رو افزایش بدیم.
خب بیاید فرض کنیم چند تا مدل مختلف آماده کردیم. حالا باید عملکرد اون ها رو بهتر کنیم. چندتا راه برای انجام این کار وجود داره.
یک راهی که ممکنه بهش فکر کنید این هست که بیایم خودمون هایپرپارامتر ها رو دست کاری کنیم تا ببینیم کدوم یک از اونها عملکرد مدل رو بیشتر میکنن. این کار خسته کننده ای هست و احتمالا ما هم زمان کافی برای انجام این کار نخواهیم داشت.
بجای این کار، میتونیم از GridSearchCV استفاده کنیم تا این کار رو برامون انجام بده. تنها کاری که باید انجام بدیم اینه که مشخص کنیم کدوم هایپرپارامتر ها رو با چه مقادیری دستکاری کنه. بعد از اون، از Cross-Validation استفاده میکنه تا تمام حالات ممکن رو بررسی بکنه. مثلا کد زیر دنبال بهترین هایپرپارامتر ها برای RandomForestRegressor میگرده :
وقتی هیچ ایده ای نداریم که مقدار یک هایپرپارامتر چقدر باید باشه، یک راه ساده اینه که توان های متوالی ده رو امتحان کنیم (یا اگه یک جستجوی دقیق تر میخواید میتونید یک عدد کوچکتر رو امتحان کنید. مثل n_estimators توی مثال ما )
متغیر param_grid به Scikit-Learn میگه که اول تمام 12=3*4 حالت n_estimators و max_features رو که توی دیکشنری اول مشخص شدن، ارزیابی کن. بعد از این، تمام 6=3*2 حالات دیشکنری دوم رو هم امتحان کن. اما این دفعه هایپرپارامتر bootsrap غیر فعال هست. (توی مطالب بعدی مفصل در مورد این هایپرپارامتر ها صحبت میکنیم)
حالا Grid Search تمام 18=12+6 حالت هایپرپارامتر های RandomForestRegressor رو بررسی میکنه و هر مدل رو 5 بار آموزش میده. به عبارت دیگه 90=18*5 بار آموزش میبینه. این کار احتمالا زمان زیادی طول بکشه. بعد از تموم شدن میتونید بهترین حالت رو به این صورت ببینید:

از اونجایی که 8 و 30 بیشترین مقداری هستند که ارزیابی شدن، بهتره که مدل رو با مقادیر بیشتر هم ارزیابی کنیم. شاید عملکرد مدل افزایش پیدا کرد.
همچنین میتونیم بهترین estimator رو هم با این دستور بدست بیاریم:

و امتیاز ها رو با این دستور:
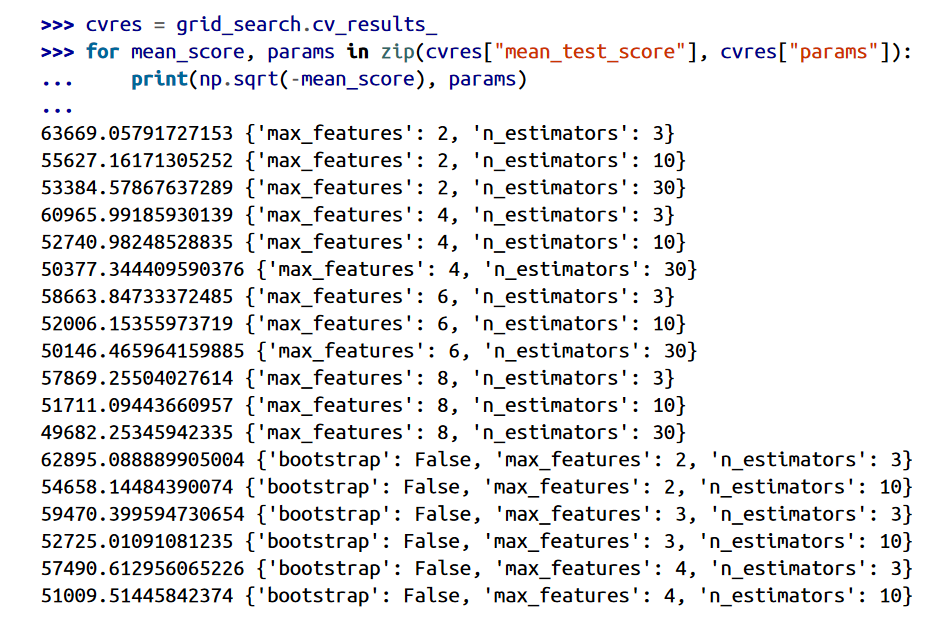
توی این مثال ما بهترین حالت رو با قرار دادن مقدار max_features به 8 و n_estimators به 30 پیدا کردیم. RMSE هم برای این ترکیب 49682 هست که بهتر از امتیازی هست که قبلا دریافت کردیم.
فراموش نکنید که میتونیم بعضی از کار هایی رو که توی قسمت آماده سازی داده ها انجام دادیم، بعنوان هایپرپارامتر در نظر بگیریم. برای مثال، Grid Search بصورت خودکار میفهمه که آیا باید یک فیچر اضافه کنیم یا نه (با استفاده از هایپرپارامتر add_bedrooms_per_room و ترنسفورمر CombinedAttributeAdder) همچنین میتونیم ازش برای کار با داده های پرت، داده های ناموجود، انتخاب فیچر و غیره استفاده کرد.
اگه تعداد حالاتی که بررسی میکنیم کم هستن، Grid Search گزینه مناسبیه. ولی وقتی جستجوی هایپرپارامتر ها بزرگ میشه بهتره که از RandomizedSearchCV استفاده کنیم. از این کلاس هم میشه مثل GridSearchCV استفاده کرد اما تفاوت این کلاس در این هست که بجای اینکه تمام حالات رو بررسی بکنه، یک تعداد حالات رندوم رو بررسی میکنه و در هر تکرار، یک مقادیر رندوم رو براشون انتخاب میکنه. این روش دو تا خوبی داره:
یک راه دیگه برای بهتر کردن عملکرد، ترکیب چند مدل هست. این گروه یا Ensemble معمولا بهتر از یک مدل عمل میکنه (مثل Random Forest که از یک Decision Tree بهتر عمل میکنه) بهخصوص موقعی که نوع خطای هر مدل تفاوت داره. بعد ها در مورد این موضوع صحبت خواهیم کرد.
معمولا با بررسی بهترین مدل ها به شهود خوبی از مسئله میرسیم. برای مثال، RandomForestRegressor میتونه ارتباط بین هر فیچر برای یک تخمین درست رو نشون بده:

با استفاده از این کد، میشه نام فیچر هر امتیاز رو هم دید:
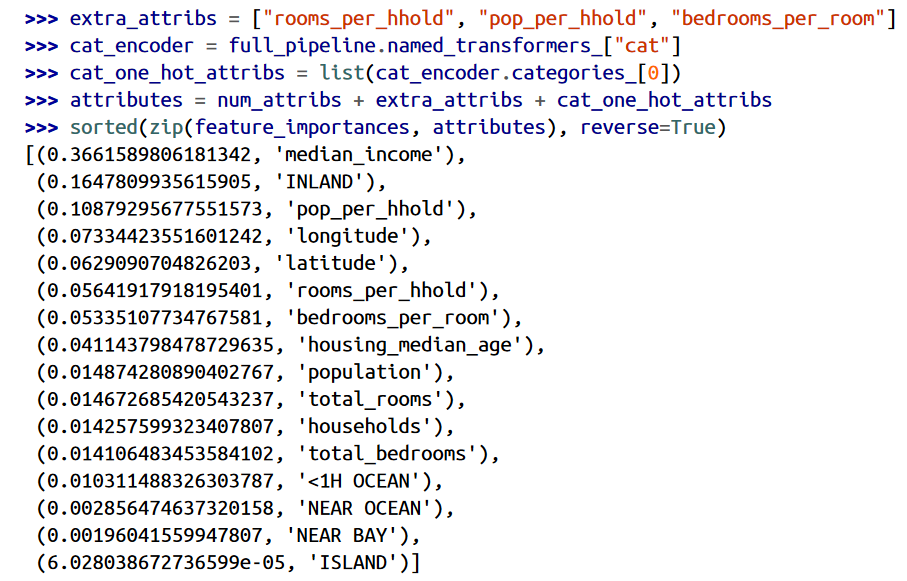
با استفاده از این اطلاعات، شاید بخوایم که بعضی از ویژگی هایی که کمتر بدردمون میخورن رو حذف کنیم(مثل اینکه فقط ocean_proximity واقعا به درد بخور هست. میتونیم بقیه رو حذف کنیم)
همچنین باید به خطا های بخصوصی که سیستم تولید میکنه توجه کنیم و ببینیم چرا این خطا ها رخ میدن و اون ها رو درست کنیم. ( با اضافه یا حذف کردن فیچر، بررسی داده های پرت و...)
بعد از بهتر کردن عملکرد مدل، به مدلی رسیدیم که عملکرد خوبی داره. حالا وقتشه که این مدل رو با تست ست ارزیابی کنیم. این قسمت هیچ چیز خاصی نداره. از full_pipeline استفاده میکنیم تا داده هامون transform بشن (تابع transform رو فراخوانی میکنیم نه fit_transform چون تست ست نباید fit بشه)

اگر خیلی هایپرپارامتر ها رو دستکاری کرده باشیم، ممکنه نتیجه ای که در آخر میگیریم از چیزی که تو cross-validation دیدیم بدتر باشه. علتش هم این هست که مدل رو برای بهتر شدن روی ولیدیشن ست تنظیم کردیم نه داده های نامعلوم.
حالا رسیدیم به مرحله قبل از لانچ پروژه. باید راه حل مون رو ارائه بدیم، همه چیز رو داکیومنت کرده باشیم، مصورسازی خوبی تهیه کرده باشیم و یک ارائه قابل فهم هم آماده کرده باشیم. توی این دیتاست، تخمین مدل ما بهتر از متخصصینی که قیمت خونه ها رو حدس میزنن نیست ولی خب برای شروع خوب هست.
باید مدل رو برای استفاده تو محصول نهایی آماده کرد ( تمیز کردن کد ها، نوشتن داکیومنت و غیره ) بعدش میتونیم مدل رو دیپلوی کنیم.
یک راه این هست که مدل رو با استفاده از joblib ذخیره کنیم، بعد در محیط محصول لودش کنیم و با استفاده از تابع predict ازش استفاده کنیم. برای مثال فرض کنید قرار هست از مدل در یک وبسایت استفاده بشه. کاربر تعدادی اطلاعات وارد میکنه و دکمه "تخمین قیمت" رو فشار میده. این باعث میشه یک query شامل این اطلاعات به سرور و سپس برنامه ارسال بشه و بعد از اون تابع predict مدل فراخوانی خواهد شد.
راه دیگه این هست که مدل رو روی یک سرور اختصاصی داشته باشیم تا اپلیکیشن ما این امکان رو داشته باشه از طریق REST API کوئری بزنه. این راه به روزرسانی مدل به نسخه جدید رو آسون تر میکنه. همچنین امکان گسترش هم راحت تر میشه چون میتونیم دستور هایی که به سرور ارسال میشه رو کنترل کنیم و به راحتی ازش توی سرویس های مختلف استفاده بکنیم. همچنین توی این روش اپلیکیشن ما میتونه به هر زبانی باشه ، نه فقط پایتون.

یک راه پرطرفدار دیگه دیپلوی کردن مدل روی فضای ابری هست مثلا Google Cloud AI Platform. توی این روش کافیه مدل رو با joblib ذخیره کرد و بعد روی Google Cloud Storage آپلودش کرد. بعد به Google Cloud AI Platofrm برید و یک مدل جدید بسازید و فایلی که آپلود کردید رو اینجا بذارید. این روش درخواست های JSON که شامل داده های ورودی هستن رو میگیره و پاسخ های JSON رو که شامل تخمین هستن برمیگردونه.
اما دیپلوی کردن پایان داستان نیست. باید یک سری کد هم برای مانیتور کردن عملکرد لحظه ای مدل و چیز هایی که اون رو از کار میندازن ، بنویسیم. این از کار افتادن عادی هست چون مدل ها بعد از مدتی خاصیت خودشون رو از دست میدن. یکی از دلایل این هست که دنیا در حال تغییر هست و داده فعلی، با داده هایی که ما مدل رو باهاش درست کردیم متفاوت هستن و مدل نمیتونه با داده های امروزی تطابق پیدا کنه.
حتی مدل هایی که برای تشخیص تصاویر گربه و سگ استفاده میشن هم باید بعد یک مدت با داده های جدید آموزش ببینن. نه بخاطر اینکه گربه ها و سگ ها تغییر میکنن بلکه بخاطر اینکه دوربین ها، فرمت، نور، شارپنس و اندازه تصاویر هر روز تغییر میکنن. یا شاید انسان ها الان دوست دارن که گربه و سگ رو لباس بپوشونن ولی موقعی که شما مدل رو درست کردید همچین چیزی رایج نبود.
پس احتیاج هست که عملکرد مدل رو مانیتور کنیم. اما چطور؟ خب بستگی داره. بعضی اوقات میتونیم از کم شدن آمار متوجه بشیم. مثلا فرض کنیم مدل ما توی یک سیستم پیشنهاد گر استفاده میشه که یک سری محصول رو به خریدار پیشنهاد میده. میتونیم تعداد محصولات پیشنهاد شده ای که مردم طی یک روز میخرن رو مانیتور کنیم. اگر این تعداد نسبت به کالا هایی که پیشنهاد میشن کم بود، پس احتمالا مدل ما مشکل پیدا کرده. حالا این مشکل میتونه بخاطر خراب بودن دیتا پایپلاین باشه یا بخاطر این باشه که مدل باید با داده های جدید آموزش ببینه.
البته این امکان همیشه وجود نداره که بتونیم عملکرد رو بدون تحلیل انسان بررسی کنیم. مثلا فرض کنیم یک مدل طبقه بندی عکس داریم و ازش برای تشخیص عیب های محصولات در خط تولید استفاده میکنیم. اگه عملکرد مدل پایین بیاد، چطور میتونیم قبل اینکه هزاران محصول معیوب دست مشتری برسه، یک هشدار دریافت کنیم؟ یک راه اینه که برای یک سری افراد امتیاز دهنده، تعدادی عکس رندوم از تصاویری که مدل طبقه بندی کرده بفرستیم. حالا بسته به نوع فعالیت، این افراد میتونن متخصص باشن یا افراد عادی. حتی بعضی اوقات این افراد میتونن خود کاربر هم باشه.
در هر حال، باید یک سیستم مانیتورینگ وجود داشته باشه و یک روند تعریف شده باشه که در صورتی که با خطا مواجه شدیم چیکار کنیم و چطوری از این خطا ها جلوگیری کنیم. متاسفانه این کار خیلی سختی هست. حتی سخت تر از ساختن خود مدل.
اگر داده ها همینطور به تغییر کردن ادامه بدن، باید دیتاست و مدل هم تغییر بکنن. ما تا جایی که بتونیم باید این روند رو اتوماتیک کنیم. در زیر میتونید چند تا از مواردی که میشه اتوماتیک کرد میبینید:
همچنین باید حواستون باشه که کیفیت داده های ورودی رو هم بررسی کنید. بعضی اوقات عملکرد بد مدل بخاطر داده های بدی هست که بعنوان ورودی داده میشن ولی خب خیلی طول میکشه تا بخاطر این داده های ورودی عملکرد مدل ضعیف بشه و یک هشدار دریافت کنیم. اگر داده های ورودی رو مانیتور میکنیم، میتونیم تعیین کنیم که هر وقت توی داده ها فیچر ناموجود داشتیم، یا میانگین و SD داده ها با داده های ترینینگ ست خیلی تفاوت داشتن، یک هشدار بهمون بده.
و در آخر حواستون باشه که از هر مدل یک بکاپ داشته باشید تا هر وقت به مشکل برخوردیم بتونیم به مدل قبلی برگردیم. این کار باعث میشه تا بتونیم به راحتی ورژن های مختلف مدل رو با همدیگه مقایسه کنیم. از دیتاست های مختلف هم بکاپ داشته باشیم تا اگه دیتاست جدید مشکلی داشت بتونیم به نسخه قبلی برگردیم. همچنین میتونیم عملکرد مدل رو با دیتاست های مختلف بسنجیم.
همونطور که میبینید یک مدل ماشین لرنینگ زیر ساخت های زیادی داره. پس اگه اولین مدل هاتون زمان و انرژی زیادی ازتون گرفت زیاد متعجب نشید. در نهایت وقتی همه این ساختار ها با هم هماهنگ شدن، میتونیم راحت تر و سریع تر به محصول نهایی برسیم.