
مطلبی که قراره بخونید ترجمه چپتر دوم کتاب Hands-on Machine Learning هست که در دو قسمت آماده شده(قسمت دوم) این چپتر جزء قسمت های آغازین کتاب هست و میخواد خواننده رو در شرایط یک دیتا ساینتیست تازه استخدام شده قرار بده. کار هایی که میخوایم توی این مطلب انجام بدیم:
1-توضیحاتی درمورد دیتاست و کاری که میخوایم باهاش انجام بدیم
2-دریافت دیتاست
3- مصورسازی داده ها
4-آماده کردن داده ها برای الگوریتم های ماشین لرنینگ
5-انتخاب یک مدل و ترین کردن اون
6-بهتر کردن عملکرد مدل با انجام تغییرات در هایپرپارامتر
7-ارائه راه حل
8-لانچ،مانیتور و نگهداری از مدل
وقتی میخوایم ماشین لرنینگ یاد بگیریم، بهتره که با داده های واقعی کار بکنیم نه با دیتاست های مصنوعی. توی این مطلبی ما از دیتاست California Housing Prices استفاده کنیم. میخوایم با بررسی داده هایی که از خونه های کالیفرنیا موجوده، قیمت خونه ها رو تخمین بزنیم. این دیتاست برای 1990 هست و خب مطمئناً دیتاست جدیدی نیست ولی خب چیز هایی زیادی میشه ازش یاد گرفت.
همونطور که گفتیم میخوایم از این دیتاست استفاده کنیم تا قیمت خونه های یک منطقه رو حدس بزنیم. این دیتاست شامل معیار هایی از جمله جمعیت، درآمد متوسط و قیمت متوسط یک بلوک در کالیفرنیا. بلوک کوچکترین واحدی هست که سازمان سرشماری آمریکا (US Census Bureau) توی داده هاش ازش استفاده میکنه که جمعیتی بین 600 تا 3000 نفر توش جا میگیرن.
اولین سوالی که از رئیس باید پرسید این هست که هدف از تجارت مون چی هست. مطمئناً هدف این نیست که صرفاً یک مدل ماشین لرنینگ ارائه بدیم. دونستن هدف مهم هست چون باعث میشه مسئله رو بهتر بفهمیم،بدونیم شرکت چه انتظاری از مدل ما داره، الگوریتم مناسب رو انتخاب کنیم،از چه ابزار هایی برای ارزیابی عملکرد مدل مون استفاده کنیم و چقدر وقت و انرژی برای بهتر شدن عملکرد مدل بذاریم.
بعد از پرسیدن این سوال، رئیس به ما پاسخ میده که خروجی این مدل که قیمت حدودی یک بلوک هست، قراره بعنوان ورودی یک مدل ماشین لرنینگ دیگه استفاده بشه. و این مدل به ما کمک خواهد کرد که بفهمیم آیا یک منطقه ارزش سرمایه گذاری رو داره یا نه.
سوال بعدی که میپرسیم این هست که راه حل فعلی این مسئله چی هست. که رئیس به ما جواب میده قیمت هر بلوک توسط متخصصین این زمنیه تخمین شده. این فرایند هزینه زیادی داره و زمان بر هم هست. همچنین تخمین هایی هم که انجام شده زیاد دقیق نیستند و گاهی اوقات 20 درصد با قیمت اصلی فاصله داشتند. بخاطر همین هست که شرکت فکر میکنه بهتره که یک مدل برای تخمین قیمت درست کنند.
با همه این اطلاعات، آماده هستیم که مدل رو درست کنیم. اول باید ببینیم که این مدل باید چه نوعی داشته باشه. Supervised یا Unsupervised یا Reinforcement Learning ؟ آیا باید از الگوریتم های Classification استفاده کنیم یا Regression ؟ تکنیک های Online Learning به دردمون میخورن یا Batch Learning ؟
خب مطمئناً کاری که میخوایم انجام بدیم Supervised Learning هست چون داده هامون از قبل label شدند. میخوایم قیمت رو حدس بزنیم پس با الگوریتم های Regression کار داریم. دقیق تر بخوایم بگیم، چون با چند feature سر و کار داریم، پس Multiple Regression به حساب میاد و چون میخوایم فقط یک عدد رو حدس بزنیم از نوع Univariate Regression هست. داده هایی که باهاشون سر و کار داریم کوچیک هستند و توی حافظه کامپیوتر قرار گرفتن پس Batch Learning کار ما رو راه میندازه.
قدم بعدی این هست که یک معیار اندازه گیری عملکرد انتهاب کنیم. معمولا برای مسائل Root Mean Square Error استفاده میکنن. بسته به موقعیتی که توش هستیم، از توابع دیگه هم میتونیم استفاده کنیم. مثلا اگه تعداد داده های پرت زیاد باشن، میتونیم از Mean Absolute Error استفاده کنیم.
خب وقتشه که دست به کیبورد بشیم! بهتره برای دریافت اطلاعات یک تابع داشته باشیم که این کار رو برامون انجام بده چون اگر داده هامون تغییری بکنن، فقط کافیه این تابع رو فراخوانی کنیم تا دوباره خودش داده های جدید رو دانلود کنه. این کار موقعی که بخوایم برنامه رو توی چند کامپیوتر اجرا کنیم هم مفید خواهد بود.
کد زیر دیتاست رو در مسیر Workspace شما ذخیره میکنه:

حالا از این کد استفاده میکنیم تا دیتاست رو با استفاده از کتابخانه Pandas بخونیم:

بیاید با متد head یه نگاه سریع به داده هامون بندازیم:
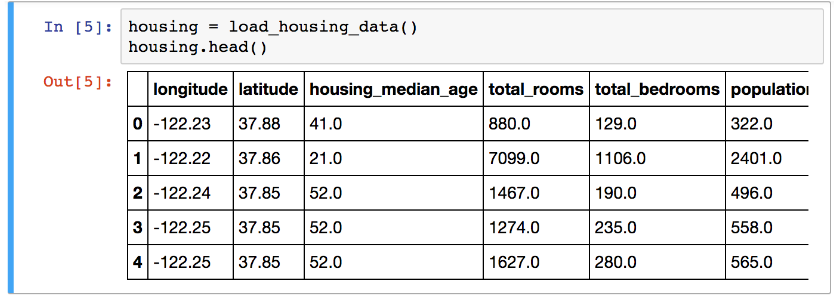
داده های ما از 10 فیچر تشکیل شدن که توی این عکس میتونید 6 تاش رو ببینید.
از متد info استفاده میکنیم تا یه توصیفی از داده هامون رو ببینیم.

توی دیتاست ما 20640 داده وجود داره که با استاندارد های ماشین لرنینگ، دیتاست کوچیکی محسوب میشه. به این توجه کنید که total_bedrooms 207 ردیف خالی داره که بعدا باید یه فکری به حالشون بکنیم.
همونطور که میبینید همه فیچر های ما عدد هستن به جز ocean_proximity که شیء هست. بخاطر شیء بودنش میتونه هر نوع شی زبان پایتون رو توی خودش ذخیره کنه اما چون داده هامون رو داریم از یک فایل CSV دریافت میکنیم، پس حتما رشته هست.
وقتی به 5 ردیف اول داده هامون نگاه کردیم، توی ستون ocean_proximity رشته های تکراری وجود داشتن پس احتمالا این ستون برای طبقه بندی استفاده میشه. میتونیم با متد value_counts بررسی کنیم:
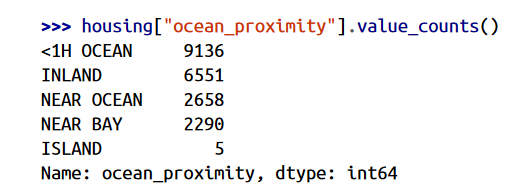
خب مشخص شد که همه داده های ما کلا در 5 طبقه بندی قرار میگیرن.
از متد describe استفاده میکنیم تا یه خلاصه ای از فیچر های عددی مون ببینیم:
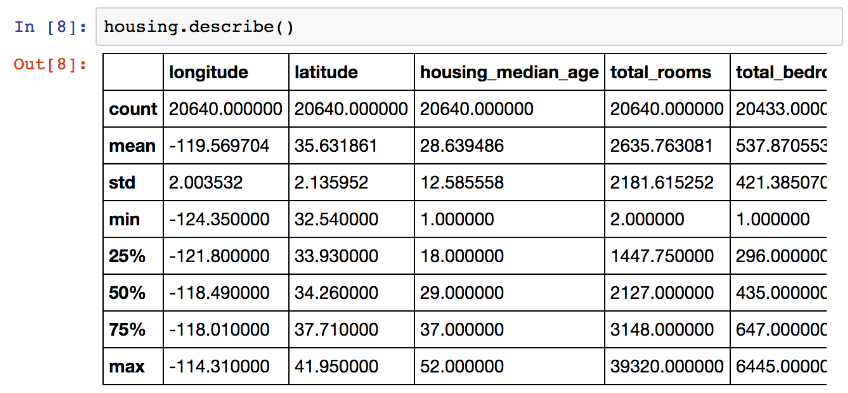
معنی ردیف های count،mean و max مشخص هست. دقت کنید که مقادیر null نادیده گرفته شدن مثلا ردیف count برای total_bedrooms 20433 هست نه 20640. ردیف std انحراف معیار داده ها(Standard Deviation) رو نشون میده به این معنا که چقدر داده های ما پراکنده هستن.
ردیف های 25%،50% و 75% صدک ها رو نشون میدن. صدک ها مقداری رو نشون میدن که اون درصد از داده های ما، زیر اون مقدار هستن. مثلا 25 درصد housing_median_age مقداری کمتر از 18 دارن، 50 درصد زیر 29 و 75 درصد زیر 37 هستن. البته این درصد ها اسم دیگه ای هم دارن. چارک اول برای 25%، میانگین برای 50% و چارک سوم برای 75%
یه راه سریع تر برای فهمیدن دیتاست، رسم هیستوگرام برای هر فیچر هست. هیستوگرام تعداد نمونه ها رو روی محور عمودی و بازه اون نمونه ها رو روی محور افقی نشون میده. برای رسم میتونید تابع hist رو روی تمام دیتاست فراخوانی کنید.

بعد از فراخوانی این تابع، با این شکل روبرو میشید:
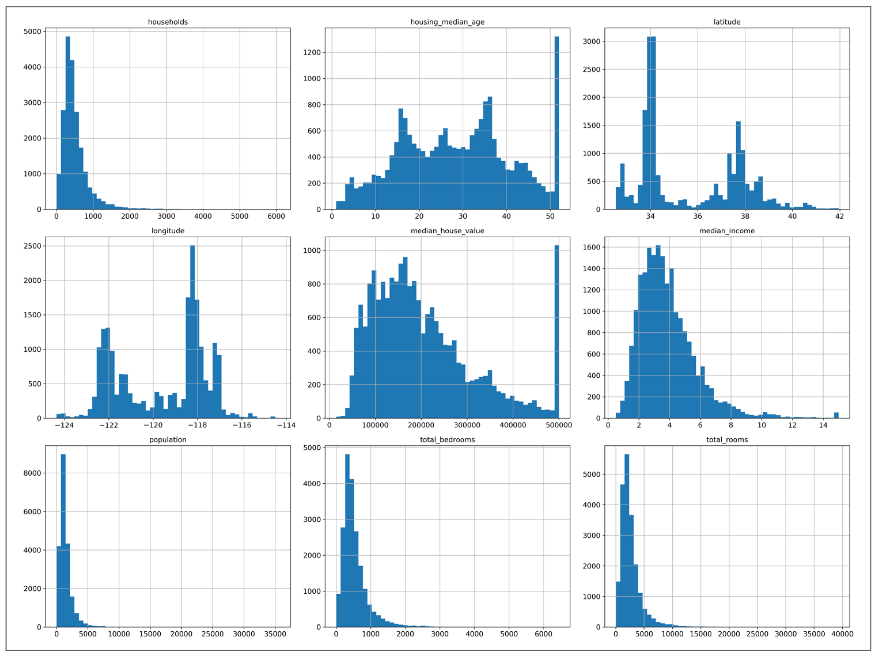
این نمودار ها نکاتی دارن که باید بهشون دقت کنیم:
1- اینطور که از نمودار مربوط به متوسط درآمد پیداست، درآمد ها به دلار بیان نشدن. اینطور که تیم جمع آوری کننده داده گفته، داده ها برای متوسط درآمد بالاتر به 15 و برای متوسط درآمد پایین به 0.5 مقیاس بندی شدن. این اعداد نشون دهنده چند ده هزار دلار هستند یعنی عدد 3 نشون دهنده متوسط درآمد 30000 هست. کار کردن با داده های پیشپردازش شده در ماشین لرنینگ مشکلی نیست اما حتما باید بدونیم که چه تغییراتی در داده ها ایجاد شده.
2- متوسط عمر و قیمت خونه ها هم مقیاس بندی شدن. دقت کنید که خروجی نهایی مدل ما قیمت خونه هست و این مقیاس بندی در قیمت خونه ها ممکنه باعث بشه الگوریتم ما فکر کنه که قیمت ها هیچوقت بیش تر از اون مقدار نمیشن. این مورد رو باید با کسانی که قرار هست از خروجی مدل ما استفاده کنن درمیون بذاریم. اگر گفتن به قیمت های دقیق بالاتر از 500000 دلار هم نیاز دارن، دو گزینه داریم:
2-الف: لیبل های مناسب اون داده ها رو پیدا کنیم
2-ب: اون داده ها رو از ترین و تست ست حذف کنیم.
3- داده هامون هر کدوم توی مقیاس های متفاوتی هستن که در ادامه مطلب بهشون میرسیم.
4-تعداد زیادی از نمودار هامون به سمت راست متوسط پیشروی کردن تا به سمت چپ. این باعث میشه بعضی الگوریتم ها الگو های موجود در داده ها رو سخت تر تشخیص بدن. در ادامه به این مورد میرسیم.
برای ادامه کار، ما باید یه تست ست درست کنیم که بعد از درست شدن اون، هیچوقت نباید سمتش بریم.
ممکنه براتون عجیب به نظر بیاد که چرا این کار رو توی این مرحله داریم انجام میدیم. ما که هنوز چیز زیادی از داده هامون ندیدیم که اصلا بخوایم الگوریتم مورد نظرمون رو انتخاب کنیم! خب این درسته اما مغز ما تو تشخیص الگو تو داده ها عالیه که این ممکنه منجر به بیشبرازش بشه: یعنی اگه به داده های تست نگاه کنیم، ممکنه یه الگوی جالب توشون ببینیم که این باعث بشه ما یه مدل بخصوص ماشین لرنینگ رو انتخاب کنیم. این باعث میشه در آخر که داریم مقدار خطا رو اندازی گیری میکنیم، خیلی خوش بین باشیم و یک مدلی رو منتشر کنیم که اونجور که انتظار میره عمل نکنه. به این کار خطای سلاخی داده یا Data Snooping Bias میگن.
از لحاظ تئوری ساختن یه مجموعه داده برای تست آسون هست: صرفا چندتا داده رو بطور رندوم انتخاب کن و بذار کنار. که این مقدار معمولا 20 درصد از دیتاست هست (یا اگه دیتاست بزرگتر هست میشه کمتر هم برداشت)
برای این کار از توابع موجود در کتابخانه Scikit-Learn استفاده میکنیم. برای اینکه این تابع هر دفعه در هر اجرا، مجموعه های متفاوت رو تولید کنه، random_state رو وارد نکنید. اگر میخواید با هر اجرا ترین و تست ست یکسان داشته باشید، برای random_state یک مقدار وارد کنید. این عدد هر عدد مثبتی میتونه باشه.

نتیجه متد بالا کاملا رندوم خواهد بود. اگر دیتاست ما بزرگ باشه این مشکلی نیست اما در غیر این صورت ما با خطای نمونه گیری مواجه میشیم. بذارید یه مثال بزنم. فرض کنید از 1000 نفر میخوایم که یه نظرسنجی رو برای ما پر کنن. انتخاب کاملا رندوم این 1000 نفر اشتباه هست چون باید مطمئن باشیم که این 1000 نفر نمونه ای از کل جمعیت ما هستن. برای کشور آمریکا که مردان 51.3 و زنان 48.7 درصد جمعیت رو تشکیل میدن، ما باید 513 مرد و 487 زن رو برای این نظرسنجی انتخاب کنیم. به این کار میگن نمونه گیری طبقه ای (Stratified Sampling). تو این نوع نمونه گیری ما جمعیت رو به زیر گروه هایی به نام طبقه(Strata) تقسیم میکنیم و مطمئن میشیم که تعداد افرادی که در هر طبقه قرار میگیرن، نمونه ای از کل جمعیت ما هستن. اگر برای نظرسنجی مون بخوایم افراد رو کاملا رندوم انتخاب کنیم، به احتمال 12 درصد امکان چولگی داده ها هست. این باعث خطا در نتیجه گیری میشه.
حالا فرض کنیم با متخصص ها صحبت کردیم و اونا بهمون گفتن که متوسط درآمد، فیچر مهمی تو تخمین متوسط قیمت خونه هست. حالا باید مطمئن باشیم که تست ست شامل همه طبقه بندی های درآمد هست.از اونجایی که میانگین درآمد یه متغیر پیوسته هست، باید اول تبدیلش کنیم به نوع داده طبقه بندی . بیاید به نمودار متوسط درآمد نگاه کنیم:بیشتر درآمد ها بین 1.5 تا 6 هستن (در واقع 15000 تا 50000 دلار) اما بعضی از درآمد ها بیشتر از 6 هم هستن. باید توجه کنیم که توی هر طبقه بندی تعداد کافی ای نمونه وجود داشته باشه وگرنه توی ارزش دهی به دسته ها، دچار خطا میشیم.
کدی که در زیر مشاهده میکنید از تابع pd.cut استفاده میکنه تا داده هامون رو توی 5 دسته مختلف که با اعداد 1 تا 5 نامگذاری شدن تقسیم کنه. بازه طبقه بندی دسته 1 ، از 0 تا 1.5 هست (درواقع مقادیر زیر 15000 دلار هستند) ، طبقه بندی دسته 2 ، از 1.5 تا 3 هست و الی آخر:

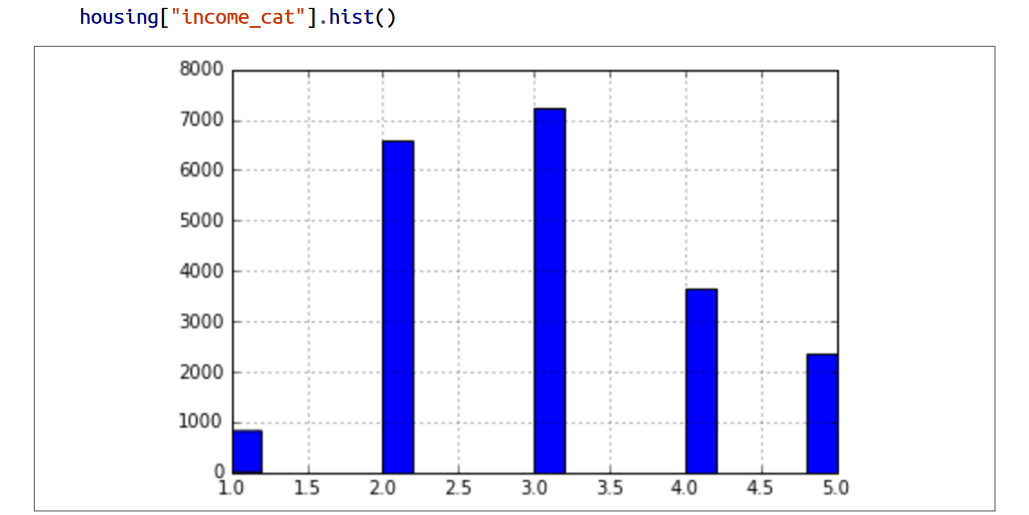
حالا آماده هستیم که نمونه گیری طبقه بندی شده رو انجام بدیم. برای این کار از کتابخانه Scikit-Learn و کلاس StratifiedShuffleSplit استفاده میکنیم:

حالا از داده هامون باید ستون income_cat رو پاک کنیم تا داده ها به حالت اولشون برگردن:

همونطور که دیدید ما زمان زیادی رو صرف درست کردن تست ست کردیم. این قسمت جز یکی از مهم ترین قسمت های یک پروژه ماشین لرنینگ هست که اغلب توش بی توجهی میکنن. کار هایی که اینجا انجام دادیم در ادامه مطلب و در قسمت Cross-Validation به دردمون میخورن.
از اونجایی که توی دیتاست اطلاعات جغرافیایی مثل طول و عرض جغرافیایی وجود داره، بهتره که یه Scatterplot رسم کنیم. مقدار alpha رو برابر 0.1 قرار میدیم تا الگو ها راحت تر دیده بشن.


حالا میخوایم یه Scatterplot رسم کنیم که شعاع دایره های اون بر اساس جمعیت یک ناحیه تغییر بکنه(مقدار s) و رنگ اون دایره هم نشون دهنده قیمت اون منطقه باشه(مقدار c). برای نشون دادن رنگ ها از مجموعه رنگ های دیفالت Jet استفاده میکنیم که برای مقادیر کم از رنگ آبی و مقادیر زیاد از رنگ قرمز استفاده میکنه.

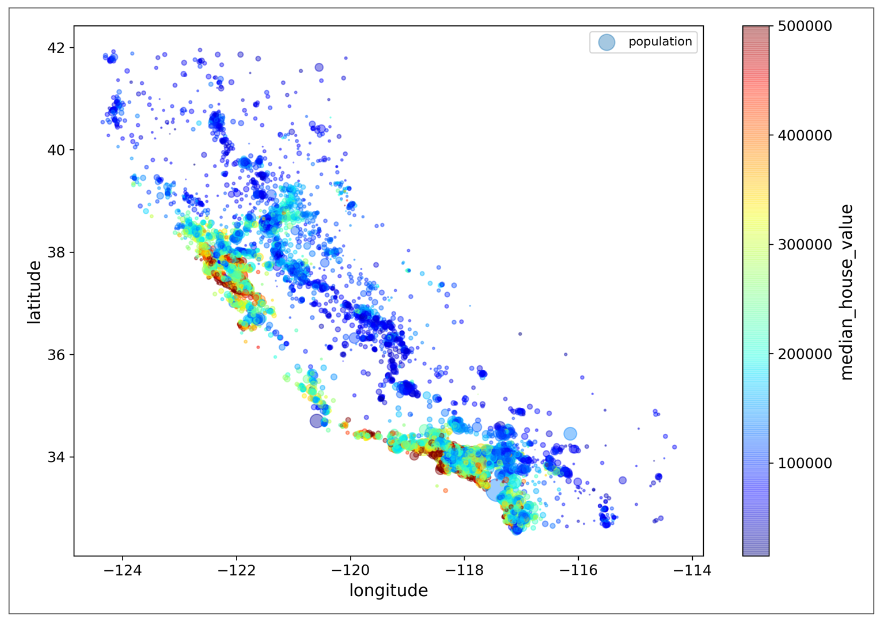
این نمودار نشون میده قیمت خونه ها رابطه زیادی با محل و تراکم جمعیت دارن.
از اونجایی که دیتاست بزرگ نیست میتونیم به راحتی ضریب همبستگی استاندار (Standard Correlation Coefficient ) بین فیچر ها رو با استفاده از متد corr محاسبه کنیم و بعد، از sort_values استفاده کنیم تا مقادیر رو به ترتیب نشون بده:
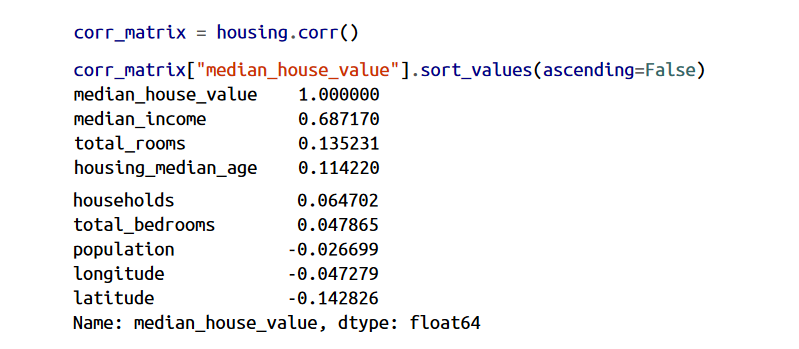
مقادیر ضریب همبستگی از -1 تا 1 هستند. وقتی این عدد نزدیک 1 هست یعنی یه رابطه قوی وجود داره. مثلا متوسط قیمت خونه همراه با متوسط درآمد افزایش پیدا میکنه. وقتی ضریب نزدیک -1 هست یعنی یه رابطه منفی وجود داره.میتونید یه همبستگی منفی رو بین میانگین قیمت خونه ها و عرض جغرافیایی ببینید.(وقتی به سمت شمال میرید قیمت ها میان پایین). ضریب های همبستگی نزدیک به صفر هم به این معنا هستن که هیچ رابطه ای وجود نداره.
در شکل زیر میتونید شکل های مختلف مربوط به ضرایب مختلف رو توی دیتاست های مختلف ببینید.
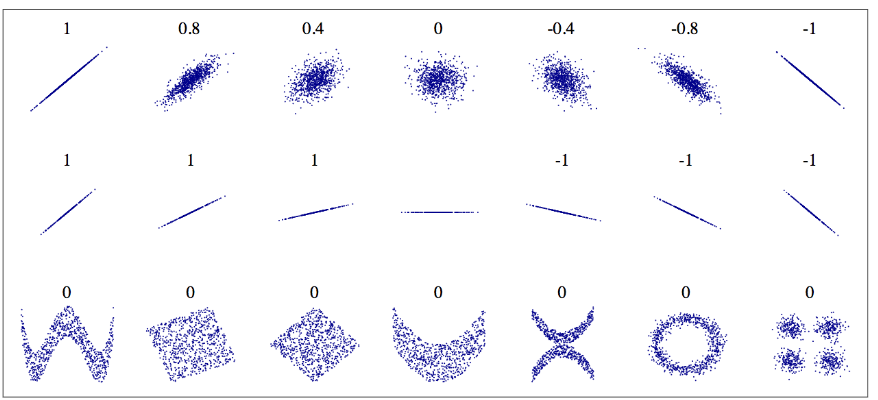
ضریب همبستگی فقط همبستگی خطی رو اندازه گیری میکنه( مثلا اگه x افزایش پیدا کنه y هم بیشتر یا کمتر میشه ) و همبستگی های غیرخطی رو محاسبه نمیکنه (مثلا اگر x نزدیک صفر باشه y افزایش پیدا میکنه). دقت کنید که ردیف آخر شکل بالا ضریب همبستگی صفر هست ولی محور های اونا مستقل نیستن. این ها نشون دهنده رابطه غیر خطی هستن.
توی ردیف دوم هم میتونید ضرایب -1 تا 1 رو ببینید. دقت کنید که این ضریب ربطی به شیب نداره. مثلا قد شما به اینچ رابطه ای با ضریب 1 با قد شما به سانتی متر داره.
راه دیگه برای محاسبه همبستگی بین فیچر ها، استفاده از تابع scatter_matrix کتابخانه Pandas هست. این متد نمودار هر فیچر در برابر فیچر های دیگه رو رسم میکنه. از اونجایی که 11 فیچر داریم، فراخوانی این تابع باعث میشه تا 11 به توان 2 یعنی 121 نمودار مختلف رو برای ما رسم کنه که خب توی یه صفحه جا نمیگیرن. پایین میتونید چندتا از فیچر هایی که بیشترین همبستگی رو با میانگین قیمت خونه داشتن ببینید.
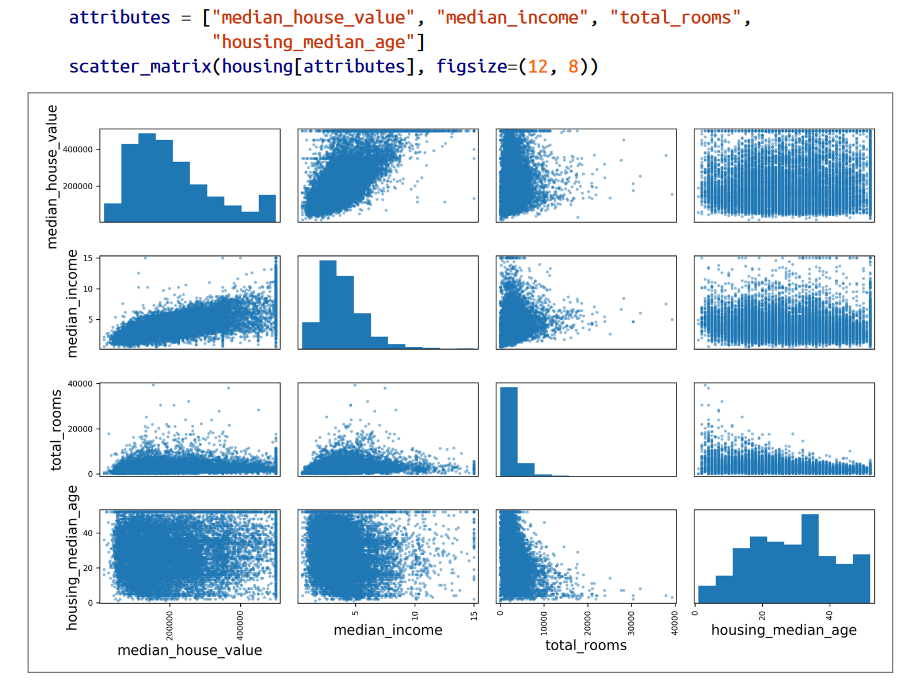
قطر اصلی این شکل فقط شامل خطوط صاف هستن چون هر فیچر دربرابر خودش مقایسه شده که این مقایسه به درد نمیخوره. بخاطر همین Pandas فقط یه هیستوگرام برای اون فیچر رسم کرده.
تاثیرگذار ترین فیچر در تخمین میانگین قیمت خونه، میانگین درآمد هست. پس بیاید زوم کنیم روی نمودار ضریب همبستگی اون:
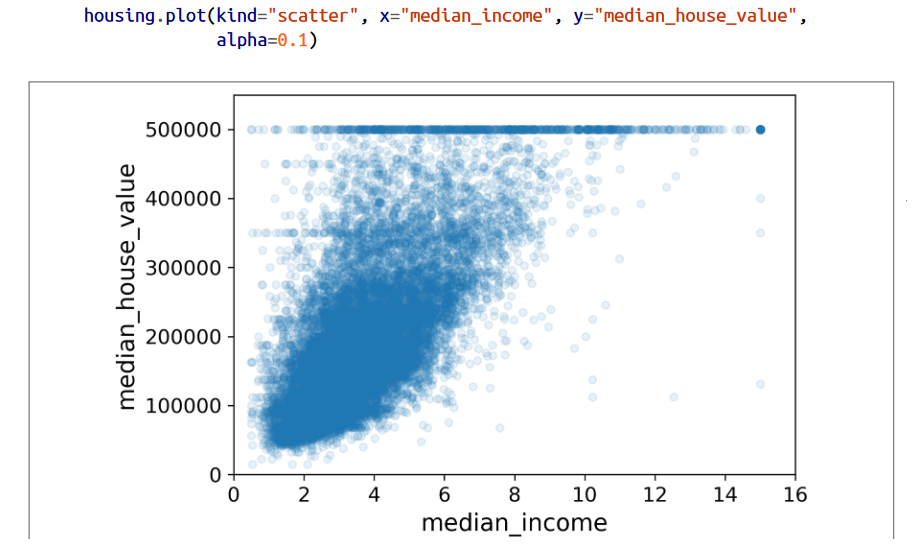
اولین چیزی که توی این نمودار مشخص هست اینه که رابطه بین این دو قوی هست. به راحتی میتونید ببینید که با افزایش متوسط درآمد، قیمت خونه ها هم زیاد میشن و فاصله بین نقطه ها کم هست. دوم اینکه سقف درآمدی که قبلا هم دیدیم، کاملا اینجا خودش رو تو نقطه 500000 دلار نشون میده. البته این نمودار یه سری خط های افقی دیگه رو هم داره نشون میده که زیاد معلوم نیستن. مثلا تو نقطه 450000 و 350000. میتونید برای اینکه الگوریتم خطای کمتری تولید کنه، خونه های توی این بازه رو حذف کنید.
تا اینجای کار فهمیدیم چطور با داده کار کنیم تا به فهم خوبی ازش برسیم. همچنین به داده هایی برخوردیم که شاید بخوایم قبل اینکه توی الگوریتم ازش استفاده کنیم تمیزشون کنیم. فهمیدیم کدوم فیچر ها رابطه قوی تری با قیمت حدس زده ما دارن. همچینن اینکه بعضی هاشون توزیع ناگسترده دارن که شاید بهتر باشه یه تغییراتی توشون ایجاد کنیم.
بهتره قبل از اینکه بخوایم داده ها رو به الگوریتم ماشین لرنینگ بدیم، چندتا از فیچر ها رو با هم ترکیب کنیم. مثلا تعداد اتاق های یک محله به دردمون نمیخورن اگه ندونیم چندتا خونه توی اون محله وجود دارن. چیزی که ما واقعا بهش احتیاج داریم تعداد اتاق های هر خونس. همچنین تعداد اتاق های خواب به تنهایی به دردمون نمیخورن، باید اون رو با تعداد کل اتاق های خونه مقایسه کنیم. تعداد ساکنین هر خونه هم به نظر فیچر جالبی میاد. حالا بیاید این فیچر ها رو ایجاد کنیم و بعد تابع corr رو دوباره فراخوانی کنیم تا ببینیم این فیچر های جدید چه رابطه ای دارن:
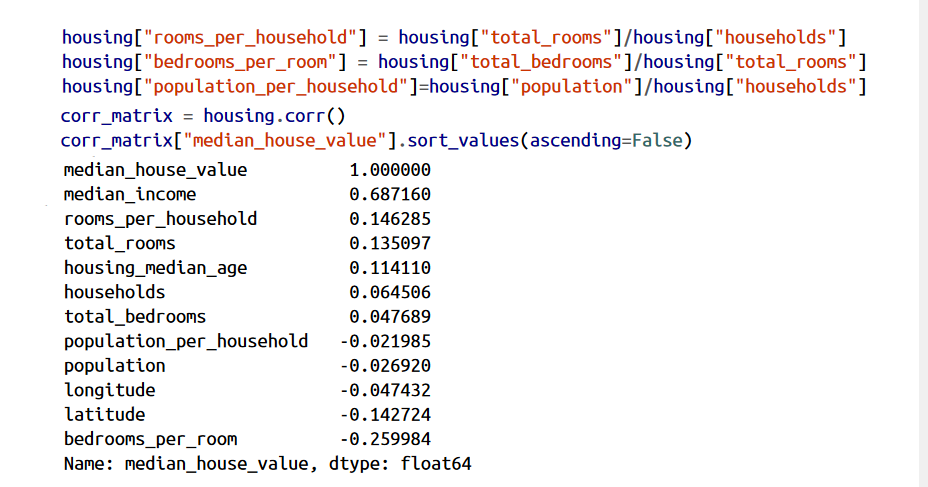
نتیجه ش خوب شد! فیچر جدید bedrooms_per_room ضریب همبستگی بیشتری نسبت به total_bedrooms یا total_rooms با متوسط قیمت خونه داره. اینطور که پیداست خونه هایی که نسبت اتاق خواب به اتاقشون کمه، گرون تر هستن.همچنین وجود اتاق به تعداد ساکنین خونه ضریب بیشتری نسبت به تمام اتاق های یه محله داره. این یعنی هرچقد خونه ها بزرگتر باشن گرون تر هم هستن.
گشت و گذار تو داده هامون حتما نباید تمام و کمال باشه و تمام جزئیات توش باشه. نکته اینجاست که خیلی سریع بتونیم اطلاعات مناسبی از داده ها به دست بیاریم که بتونیم نسخه های اولیه پروژه مون رو ارائه بدیم.این پروسه تکرار شوندست: بعد از اینکه به نسخه اولیه مون رسیدیم ، میتونیم اونو تحلیل کنیم، نقاط ضعف رو کشف کنیم و دوباره یک سری اطلاعات تازه پیدا کنیم.
خب حالا وقتشه که داده هامون رو برای الگوریتم آماده کنیم. اما قبلش بیاید دیتاست رو به حالت اولیه برگردونیم. از اونجایی که میخوایم label ها و predictor ها دست نخوره باقی بمونن، اون ها رو جدا کنیم.

بیشتر الگوریتم های ماشین لرنینگ نمیتونن با فیچر های ناموجود کار کنن. بخاطر همین ما باید این مشکل رو رفع کنیم. قبلا دیدیم که total_bedrooms چندتا نمونه خالی داشت. سه تا گزینه داریم:
1- این نمونه ها رو حذف کنیم
2-کل اون فیچر رو حذف کنیم
3- اونها رو با مقادیری مثل صفر، میانگین و میانه پر کنیم
این سه گزینه رو توی خطوط زیر میتونید ببینید:

اگر گزینه 3 رو انتخاب کنیم، باید میانه رو با استفاده از ترینینگ ست حساب کنیم.فراموش نکنید که این مقدار رو باید ذخیره کنید چون بعدا برای پر کردن داده های ناموجود تست ست و داده های ناموجود بعد از لانچ مدل لازممون میشه.
کتابخانه Scikit-Learn یک کلاس به نام SimpleImputer برای انجام این کار داره.برای انجام این کار اول باید یه Instance از این کلاس بسازیم و مشخص کنیم که میخوایم باهاش میانه رو حساب کنیم:

از اونجایی که میانه یه عددی هست، باید فیچر ocean_proximity رو از دیتاست حذف کنیم چون شامل رشته هست:

حالا میتونیم imputer رو روی ترینینگ ست فیت کنیم:

حالا میانه همه فیچر ها محاسبه شدن و توی imputer ذخیره شدن. برای دسترسی به اونها باید از imputer.statistics_ استفاده کنیم. ممکنه براتون سوال پیش بیاد که ما میدونستیم فقط total_bedrooms شامل نمونه های ناموجود هست، پس چرا میانه ی همه فیچر ها رو حساب کردیم؟ علت این کار این هست که ما نمیدونیم بعد از لانچ مدل، همه داده ها موجود خواهند بود یا نه. در نتیجه این عدد رو ذخیره میکنیم تا در صورت ناموجود بودن داده در آینده، ازش استفاده کنیم.
حالا از این imputer استفاده میکنیم تا داده هامون رو ترنسفورم کنیم:

خروجی این خط یه آرایه NumPy میشه که اگه بخوایم میتونیم تبدیل به دیتافریم کنیم:

همه شی های این کلاس یک سری اینترفیس مشترک دارن:
یک. Estimators: هر شی که یک سری پارامتر ها رو تو یک دیتاست محاسبه کنه، یک Estimator به حساب میاد. مثلا imputer یک Estimator هست. این عمل محاسبه توسط یک تابع به نام fit انجام میشه و فقط یک سری داده رو بعنوان پارامتر میگیره مثلا یه ستون یا یه دیتاست(البته برای الگوریتم های Supervised Learning دوتا پارامتر میگیره) هر پارامتر دیگه ای مثل strategy که مقدارش رو خودمون تعیین میکنیم هایپرپارامتر نام داره و باید بعنوان instance variable توسط سازنده تعیین بشن.
دو. Transformers: بعضی Estimator ها مثل Imputer میتونن تغییراتی توی دیتاست ایجاد کنن که به اونها Transoformer میگیم. این تغییر با فراخوانی تابع transform و وارد کردن ستون یا دیتاست بعنوان پارامتر انجام میشه. همه ترنسفورمر ها یک تابع دیگه به نام fit_transform دارن که کار fit و transofrm رو یک جا انجام میدن( بعضی اوقات انجام محاسبات با این تابع سریع تر هست )
سه. Predictors: بعضی Estimator ها میتونن وقتی یک دیتاست بهشون میدیم یک سری چیز ها رو حدس بزنن که به اونها میگیم Predictors. مثلا مدل LinearRegression یه Predictor هست. Predictor ها تابعی به نام predict دارن که یک دیتاست جدید رو میگیرن و یک دیتاست رو که شامل حدسی هست که زدن، برمیگردونن. همچنین یک متد به نام score دارن که کیفیت یک حدس رو محاسبه میکنن.
چهار.Inspection: همه هایپرپارامتر های یک Estimator از طریق شی ای که ساختیم قابل دسترس هست مثلا imputer.strategy و تمام پارامتر هایی که Estimator محاسبه کرده از طریق پسوند _ قابل دسترسی هست مثل imputer.statistics_
تا اینجا ما فقط با فیچر های عددی کار کردیم. حالا میخوایم با فیچر های رشته ای هم کار کنیم.ocean_proximtiy تنها فیچر با این فیچر هست. اگر به چند نمونه از این ستون نگاه کنیم، متوجه میشیم تعداد کمی متغیر وجود دارن. این یعنی فیچر طبقه بندی هست. بیشتر الگوریتم های ماشین لرنینگ با عدد ها بهتر کار میکنن پس بیاید این رشته ها رو به عدد تبدیل کنیم. برای این کار از کلاس OrdinalEncoder کتابخانه Scikit-Learn استفاده میکنیم.


یک مشکلی که این راه داره اینه که الگوریتم های ماشین لرنینگ تصور میکنن این اعداد دارای ارزش خاصی هستن.اگر از این اعداد برای طبقه بندی ترتیبی مثل بد متوسط خوب استفاده میکردیم مشکلی نبود ولی خب اینجا اعداد ocean_proximity ارزش خاصی ندارن.
برای حل این مشکل ما یک دوتایی رو به هر طبقه بندی نسبت میدیم: 1 برای وقتی که یک نمونه جز یک طبقه بندی هست و صفر برای وقتی که نیست. به این روش میگن One-Hot Encoding چون فقط یک فیچر قراره 1 بشه (داغ) و باقی قراره 0 بشن(سرد). بعضی جاها روش Dummy هم بهش میگن.

دقت کنید که خروجی به صورت ماتریس SciPy هست و نه آرایه NumPy. این موقعی به درد میخوره که چندین هزار طبقه بندی داریم چون بعد از استفاده از One Hot Encoding یک ماتریس با هزاران ستون خواهیم داشت که به جز یک 1 در هر ردیف، باقی صفر هست. اینکه بخوایم برای ذخیره کردن این همه صفر مقدار زیادی از حافظه رو اشغال کنیم درست نیست پس بجاش از یک ماتریس اسپارس استفاده میکنیم که فقط محل ذخیره عناصر غیر صفر رو ذخیره میکنه. میتونید ازش مثل یک آرایه دو بعدی استفاده کنید اما اگه خیلی دوست دارید که تبدیل به آرایه NumPy بشه، میتونید متد toarray رو روی انن ماتریس فراخوانی کنید.
اگرچه که Scikit-Learn ترنسفورمر های به درد بخوری داره اما بعضی اوقات برای انجام بعضی عملیات پاکسازی یا اضافه کردن فیچر ها، باید خودمون یک ترنسفورمر بسازیم. از اونجایی که Scikit-Learn متکی بر Duck Typing هست و از ارث بری پشتیبانی نمیکنه، تنها کاری که باید بکنیم این هست که یک کلاس بسازیم و سه تا متد fit ، transform و fit_transform رو توش جا بدیم.

توی این مثال ترنسفورمر فقط یک هایپرپارامتر با نام add_bedrooms_per_room داره که دیفالتش True هست. این هایپرپارامتر به ما اجازه میده بفهمیم آیا عملکرد مدل با اضافه کردن این فیچر بهتر شده یا نه. و به طور کلی، میتونیم برای هر کاری که در مرحله آماده سازی داده انجام میدیم، یک هایپرپارامتر مشخص کنیم و با استفاده از اون بفهمیم آیا عملکرد مدل با انجام اون مرحله بهتر شده یا نه.
یکی از مهم ترین تغییراتی که باید روی داده هامون اعمال کنیم، Feature Scaling هست. به جز چند تا الگوریتم، باقی الگوریتم ها با اعدادی که تو مقیاس های مختلف هستن عملکرد خوبی نشون نمیدن.
توی این دیتاست ما این مورد صادق هست. تعداد همه اتاق ها، بین 6 تا 39320 عدد هست در حالیکه میانگین درآمد بین 0 تا 15 هست. دقت کنید لازم نیست مقیاس target value رو تغییر بدیم.
دو تا از راه های عمومی برای تغییر مقایس، min-max scaling و standardization نام دارن.
راحت ترین راه min-max scaling یا همون normalization هست. توی این روش همه اعداد طوری تغییر میکنن که بین 0 تا 1 باشن. برای انجام این کار از فرمول زیر استفاده میکنیم:
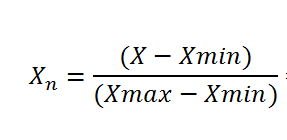
برای انجام این کار از ترنسفورمر MinMaxScaler که توی کتابخانه Scikit-Learn هست استفاده میکنیم. اگر نمیخوایم بازه اعداد بین 0 تا 1 باشن، میتونیم با استفاده از هایپرپارامتر feature_range بازه رو تغییر بدیم.
اما Standardization فرق داره که میتونید فرمولش رو ببینید:
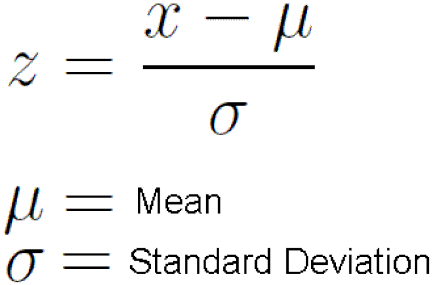
بر خلاف روش اول که همه اعداد بین 0 و 1 هستن، این روش خودش رو محدود به بازه ای نمیکنه. این مورد برای استفاده از الگوریتم هایی مثل شبکه های عصبی که داده ها باید بین 0 و 1 باشن مشکل ایجاد میکنه.
اما نکته قابل توجه در این روش اینه که داده های پرت زیاد روش تاثیری ندارن. مثلا فرض کنید متوسط درآمد به اشتباه 100 وارد شده. استفاده از روش اول باعث میشه همه اعداد ما از 0 تا 15 به 0 تا 0.15 تغییر بکنن در حالی که توی روش دوم این اتفاق نمیفته.
برای استفاده از Standardization میتونید از ترنسفورمر StandardScaler استفاده کنید.
تو همه ترنسفورمر ها، این نکته مهمه که همه محاسبات با ترینینگ ست انجام بشه، نه با کل دیتاست و نه با تست ست. فقط در این صورت هست که میتونید از این ترنسفورمر ها روی تست ست و داده های جدید استفاده کنید
قبل از اینکه وارد این بخش بشیم،اول ببینیم پایپلاین به چه معناست.
به یک سری از مراحل پردازش داده پایپلاین میگن. از اونجایی که توی پروژه های ماشین لرنینگ مراحل زیادی رو برای تغییر در داده ها طی میکنیم، پایپلاین ها خیلی به کارمون میان. همه اجزای پایپلاین به طور همزان اجرا میشن، به این صورت که هر جز یک سری داده رو دریافت میکنه و یک خروجی رو تحویل جز بعدی میده. بعد این جز با استفاده از این خروجی، یک خروجی دیگه تحویل میده. این تیکه تیکه بودن یک فعالیت، باعث میشه ما و دیگر افراد تیم بهتر بتونیم یک سیستم بزرگ رو درک کنیم. به این شکل هر یک از افراد میتونن روی یه قسمت تمرکز کنن. یک خوبی دیگه این کار این هست که اگر هر جزئی به مشکل بخوره، اجزای دیگه تا یک مدتی میتونن با آخرین خروجی اون جز خراب به کارشون ادامه بدن. البته نکته منفی اینجاست که اگر به خوبی سیستم رو مانیتور نکنیم، ممکنه تا یه مدت طولانی ای اصلا متوجه نشیم که یکی از اجزا خراب شدن!
خوشبختانه Scikit-Learn کلاس Pipeline داره که به راحتی میتونیم برای انجام کار هایی که گفتیم ازش استفاده کنیم. میتونید یه پایپلاین کوچیک رو برای داده های عددی ببینید:

سازنده این کلاس تعدادی اسم و estimator رو به صورت دوتایی میگیره که ترتیب اجرا رو نشون میدن. این اسامی میتونن هرچیزی باشن (فقط نباید تکراری باشن و __ هم نداشته باشن) این اسامی بعدا توی تنظیم هایپرپارامتر ها به دردمون میخورن.توجه کنید که آخرین چیزی که توی سازنده قرار میگیره باید ترنسفورمر بشه.
وقتی تابع fit توی پایپلاین رو فراخوانی میکنیم، بصورت پی در پی fit_transform هم توی تمام ترنسفورمر ها فراخوانی میشه. این باعث میشه خروجی هر فراخوان بعنوان پارامتر فراخوان بعدی استفاده بشه تا موقعی که به estimator آخر برسیم که اون فقط fit رو فراخوانی میکنه.
توی مثال ما، estimator آخر StandardScaler هست که ترنسفورمر هست پس پایپلاین یه متد transform و fit_transform داره که تمام تغییرات روی داده رو پی در پی اجرا میکنه.
تا به اینجای کار ما ستون های طبقه بندی رو جدا و ستون های عددی رو جدا بررسی کردیم. راحت تره که یه ترنسفورمر داشته باشیم که بتونه از پس همه ستون ها بربیاد و ترنسفورمر مناسب رو برای هر ستون به کار ببره.توی نسخه 0.20 Scikit-Learn برای انجام این کار میتونیم از ColumnTransformer استفاده کنیم که به راحتی با دیتافریم های کتابخانه Pandas کار میکنه.

اول کلاس رو ایمپورت کردیم، بعد یه لیست از اسم ستون های عددی و یه لیست از ستون های طبقه بندی تهیه کردیم و بعد ColumnTransformer رو درست کردیم. سازنده به لیستی از tuple ها احتیاج داره که هر tuple حاوی یک اسم، یک ترنسفورمر و یه لیست از نام یا شماره ستون هایی هست که ترنسفورمر باید روشون اعمال بشه. توی مثال مشخص کردیم که ستون های عددی باید با استفاده از num_pipeline پر بشن و ستون های طبقه بندی بوسیله OneHotEncoder. در نهایت این ColumnTransformer رو به کل دیتاست اعمال میکنیم. این کار باعث میشه که هر transformer به ستون مناسب اعمال بشه .
توجه کنید که OneHotEncoder یک Sparse Matrix برمیگردونه در حالیکه خروجی num_pipeline یک Dense Matrix هست. در مواقع این چنینی که چند نوع ماتریس داریم، ColumnTransformer چگالی ماتریس نهایی رو محاسبه میکنه (یعنی نسبت داده های ناموجود) و اگه اون چگالی کمتر از یه عددی باشه یه Sparse Matrix برمیگردونه.( به اون عدد میگن sparse_threshold که مقدار دیفالتش 0.3 هست) توی مثال ما Dense Matrix برمیگردونه.
اگر میخوایم یک ستون رو حذف کنیم میتونیم از drop استفاده کنیم یا اگر میخوایم دست نخوره باقی بمونه میتونیم مشخص کنیم که passthroguh بشه. بصورت دیفالت، اگر ستون هایی باشن که ما مشخص نکرده باشیم چه تغییراتی روشون اعمال بشه، اون ستون ها حذف میشن. میتونیم برای جلوگیری از این کار هایپرپارامتر remainder رو به یک ترنسفورمر تغییر بدیم یا اون رو برابر passthroguh بذاریم تا دست نخوره باقی بمونن.
اینم از این! حالا ما یه پایپلاین داریم که کل داده ها رو میگیره و تغییرات مناسب رو روی هر ستون اجرا میکنه.
و بالاخره! تا اینجای کار ما مسئله رو با مصورسازی بررسی کردیم و یک سری عملیات روی داده ها انجام دادیم.
بیاید با ترین یک مدل Linear Regression یا همون رگرسیون خطی شروع کنیم.

تمام! حالا یه مدل رگرسیون خطی داریم. بیاید با استفاده از چندتا از داده های ترینینگ امتحانش کنیم.
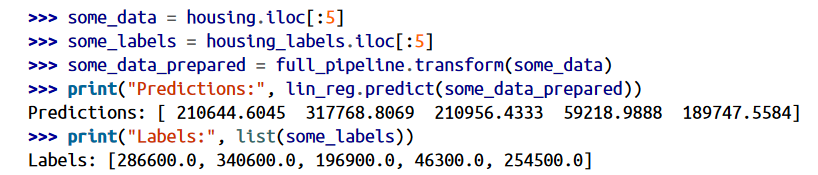
اگرچه دقتش بالا نیست ولی خب کار میکنه. بیاید RMSE این مدل رو محاسبه کنیم. این کار رو با استفاده از تابع mean_squarred_error انجام میدیم:

نتیجه ای که گرفتیم از هیچی بهتره ولی خب نتیجه خوبی نیست. بیشتر قیمت خونه ها بین 120000 تا 265000 دلار هست و مدل ما با 68628 دلار خطا تخمین میزنه. این یه مثال از کمبرازش یا Underfitting بودن مدل هست. وقتی این اتفاق میفته به این معنی هست که فیچر های ما به اندازه کافی اطلاعات مناسبی رو در اختیار نمیذارن و با استفاده از اونها نمیشه تخمین خوبی انجام داد. برای برطرف کردن این مشکل میتونیم یه مدل قوی تر انتخاب کنیم، فیچر های بهتری رو در اختیار مدل قرار بدیم یا محدودیت های مدل رو برطرف کنیم. مدل ما Regularize نشده، پس گزینه سوم رد میشه. میتونیم چندتا فیچر جدید اضافه کنیم(مثلا لگاریتم جمعیت). اما قبل از این کار ها، بیاید یه مدل پیچیده تر رو امتحان کنیم.
بیاید از DecisionTreeRegressor استفاده کنیم. این مدل قوی ای بهحساب میاد و توانایی کشف روابط غیرخطی رو در داده داره:

میزان خطا صفر؟! یعنی ما یه مدل عالی بدون خطا درست کردیم؟! یقینا نه. این مدل دچار بیشبرازش یا Overfitting شده. همونطور که قبلا گفتیم، تا موقعی که از نهایی شدن مدل مطمئن نشدیم، نباید سمت تست ست بریم. پس باید از قسمتی از ترینینگ ست استفاده کنیم تا مدل رو آموزش بدیم و از قسمتی از اون برای اعتبارسنجی مدل یا Model Validation استفاده کنیم.
یک راه برای ارزیابی مدل Decision Tree استفاده از تابع train_test_split هست تا ترینینگ ست رو به ترینینگ ست های کوچکتر و یک ولیدیشن ست تقسیم کنیم. بعد از این کار مدل رو با ترینینگ ست های کوچکتر آموزش بدیم و با ولیدیشن ست ارزیابی کنیم.
یک راه خوب برای انجام این کار، استفاده از K-fold cross-validation هست. کدی که در ادامه میبینید ترینینگ ست رو بصورت رندوم به 10 زیرمجموعه متقاوت به نام fold تقسیم میکنه. بعد مدل Decision Tree رو ده بار ترین و ده بار ارزیابی میکنه. برای هر ارزیابی یک مجموعه متفاوت رو انتخاب میکنه و با 9 مجموعه دیگه روند آموزش رو انجام میده.نتیجه یک آرایه هست که 10 امتیاز مختلف توش ذخیره شده.

کلاس Cross Validation در Scikit-Learn برای محاسبه مقدار خطا از یک تابع مطلوبیت(Utility Function) استفاده میکنه که در اون نتیجه هرچقدر بیشتر باشه بهتره. نقطه مقابل این تابع، تابع هزینه(Cost Function) هست که توی اون نتیجه هرچقدر کمتر باشه بهتره. بخاطر همین هست که تابع ما کاملا مخالف MSE هست و قبل از انجام محاسبه، باید مقدار scores- رو وارد کنیم.
حالا بیاید به نتیجه نگاه کنیم:

همونطور که میبینید نتیجه کار کاملا با قبلی فرق میکنه. حتی این مدل بدتر از مدل رگرسیون خطی عمل میکنه! دقت کنید که Cross-Validation نه تنها عملکرد رو تخمین میزنه بلکه حتی دقت این عملکرد رو هم نشون میده(Standard Deviation). مدل Decision Tree امتیازی نزدیک 71407 با اختلاف 2,439± داره. توجه کنید اگه فقط از یک ولیدیشن ست استفاده میکردیم نمیتونستیم این اطلاعات رو بدست بیاریم.
حالا بیاید همین امتیاز ها رو برای مدل رگرسیون خطی هم محاسبه کنیم:

بله اینطور که پیداست مدل Decision Tree اورفیت شده و بخاطر همین عملکردش از رگرسیون خطی هم بدتره.
حالا بیاید از یک مدل دیگه به نام RandomForestRegressor استفاده کنیم. این مدل تعداد زیادی از Decision Tree ها رو با مجموعه های رندومی آموزش میده و عملکرد اونها رو تخمین میزنه. به این کار که ما میایم یک مدل رو با استفاده از مدل های دیگه درست میکنیم میگن Ensemple Learning و بیشتر اوقات راه خوبی هست تا الگوریتم های ماشین لرنینگ رو یک قدم جلوتر ببریم.
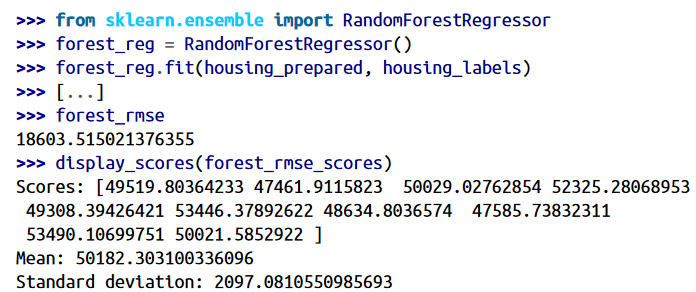
خب حالا نتیجه بهتر شد! اما دقت کنید که امتیاز روی ترنینگ ست همچنان پایین تر از ولیدیشن ست هست و این به معنای اینه که مدل ما هنوز هم دچار اورفیتینگ هست. برای برطرف کردن این مشکل میتونیم مدل رو ساده تر کنیم، با استفاده از Regularization محدود ترش کنیم و یا ترینینگ دیتا رو بیشتر کنیم.
ما باید هر مدل رو ذخیره کنیم تا بعدا بتونیم به راحتی بهشون دست پیدا کنیم. یادتون باشه که هایپرپارامتر ها، پارامتر ها و امتیاز های Cross-validation رو هم ذخیره کنید. این کار بهمون اجازه میده تا به راحتی امتیاز هر مدل و خطا های اون رو بررسی کنیم. برای این کار میتونیم از pickle که توی کتابخانه Scikit-Learn هست و یا از کتابخانه joblib استفاده کنیم. مورد دوم برای ذخیره آرایه های NumPy راحت تره.

خب این از قسمت اول مطلب. در قسمت بعد میخوایم عملکرد مدل رو افزایش بدیم.