
از کار های رایج توی Supervised Learning حدس زدن مقدار (Regression) و و حدس زدن دسته (Classification) هست. توی مطلب قبلی قیمت خونه های یک محله رو تخمین زدیم. توی این مطلب میخوایم با استفاده از الگوریتم های Classification اعداد رو با استفاده از دیتاست MNIST تشخیص بدیم.
این دیتاست از 70000 عکس تشکیل شده که شامل اعداد نوشته شده توسط دانش آموزان دبیرستانی و کارمندان سازمان سرشماری آمریکا هست. هر عکس با شماره ای که توی عکس هست لیبل گذاری شده. این دیتاست انقدر مطالعه شده که بعضی اوقات بهش میگن "hello world" ِ ماشین لرنینگ! هر وقت افراد یک الگوریتم Classification جدید پیدا میکنن ، اول روی این دیتاست امتحانش میکنن. افراد تازه کار هم کارشون رو با این دیتاست شروع میکنن.
کتابخانه Scikit-Learn توابع زیادی برای دریافت این دیتاست داره. میتونید از کد زیر استفاده کنید:

دیتاست توی مسیر USERNAME/scikit_learn_data قرار میگیره.
دیتاست هایی که توسط Scikit-Learn دانلود میشن معمولا ساختار دیکشنری یکسانی دارن که شامل موارد زیر هستند:
بیاید نگاهی به این آرایه ها بندازیم:
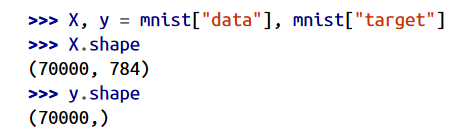
70000 عکس وجود داره که هر عکس 784 تا فیچر داره. این به این بخاطر هست که هر عکس 28 * 28 پیکسل هست و هر فیچر نشون دهنده شدت هر پیکسل هست. مقدار این شدت از 0 (سفید) تا 255 (سیاه) متغیر هست. بیاید به یک عدد از این دیتاست نگاهی بندازیم:

بهش میخوره که 5 باشه. برای اینکه مطمئن بشیم y[0] رو میزنیم که نتیجش میشه 5.
دقت کنید که لیبل بصورت رشته هست. در حالیکه بیشتر الگوریتم های ماشین لرنینگ انتظار عدد دارن پس باید y رو تبدیل به عدد کرد:

خب همینجا باید صبر کنید. همیشه باید یک تست ست بسازیم و اونو بذاریم کنار و هیچ کاری هم باهاش نداشته باشیم. دیتاست MNIST خودش به ترینینگ ست (60000 نمونه اول) و تست ست(10000 نمونه بعدی) تقسیم شده و فقط کافیه کد زیر رو اجرا کنیم:

بیاید فعلا مسئله رو کوچیک کنیم و فرض کنیم که فقط میخوایم یک عدد رو تشخیص بدیم، مثلا عدد 5. به این چیزی که قراره عدد 5 رو تشخیص بده میگن Binary Classifier چون میتونه تفاوت بین دو تا دسته رو بفهمه، 5 ها و غیر 5 ها. بیاید وکتور های لازم برای این الگوریتم Classification رو بسازیم:

حالا بیاید یک Classifier انتخاب کنیم. برای شروع میتونیم از Stochastic Gradient Descent(SGD) استفاده کنیم. یکی از نکات مثبت این الگوریتم این هست که به راحتی میتونه با دیتاست های بزرگ کار کنه.
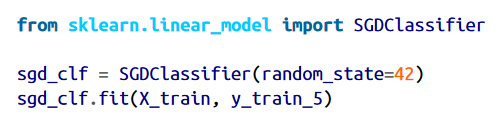
حالا ازش استفاده میکنیم تا عدد 5 رو حدس بزنه:

ارزیابی عملکرد یک Classifier اغلب اوقات سخت تر از Regressor هست بخاطر همین بیشتر این مطلب قراره صرف این کار بشه.
مثل مطلب قبلی، اینجا هم استفاده از CV روش خوبی هست. بیاید از تابع cross_val_score برای ارزیابی مدل SGFClassifier استفاده کنیم.اگه میخواید درمورد این روش بیشتر بدونید به مطلب قبلی مراجعه کنید.

دقت بالای 93 درصد شاید اولش خوب به نظر بیاد ولی زیاد هیجان زده نشید. بیاید به یک Classifier نگاه کنیم که غیر 5 ها رو دسته بندی میکنه:

دقت این مدل برابر هست با :

علت دقت بالای 90 درصد این هست که فقط 10 درصد عکس ها 5 هستند و همیشه داره حدس میزنه که این عکس 5 نیست، بخاطر همین 90 درصد مواقع درست حدس میزنه.
این نشون میده که چرا مقدار دقت همیشه معیار مناسبی برای ارزیابی عملکرد یک Classifier نیست. مخصوصا وقتی که با دیتاست های دارای چولگی سر و کار داریم.
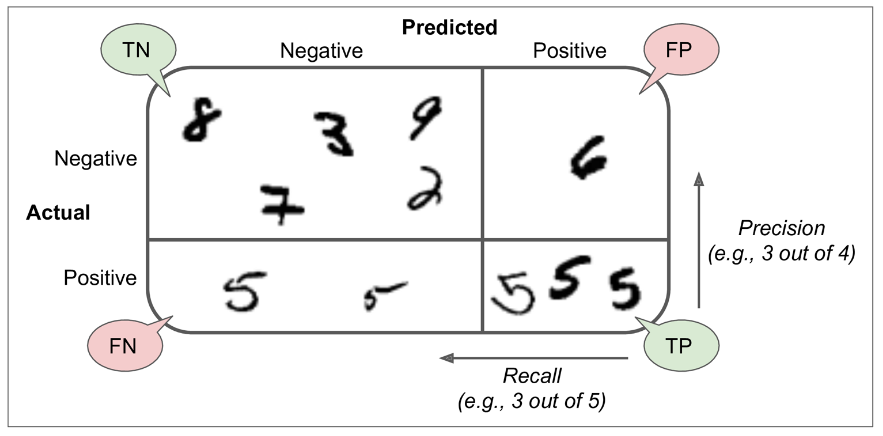
یک راه بهتر ارزیابی مدل استفاده از Confusion Matrix هست. ایده کلی این ماتریس این هست که میاد تعداد دفعاتی رو که نمونه های دسته A ، جزء نمونه های دسته B دسته بندی شدند میشماره. مثلا اگه بخوایم تعداد دفعاتی که مدل، 5 ها رو با 3 ها اشتباه گرفته بدونیم، به ردیف پنجم و ستون سوم این ماتریس مراجعه میکنیم.
برای استفاده از این ماتریس اول باید یک سری حدس ها داشته باشیم که بتونیم اون ها رو با مقادیر واقعی مقایسه کنیم. میتونیم با استفاده از تست ست یک سری حدس ها بزنیم ولی فعلا بذارید دست نخوره باقی بمونه. (یادتون باشه که از تست وقتی استفاده میکنیم که کار پروژه ما تموم شده و آماده لانچ هست).
به جای این کار میتونیم از cross_val_pridict استفاده کنیم:

این تابع درست مثل cross_val_score عمل میکنه منتهی با این تفاوت که بجای امتیاز، حدس هایی که تو هر فولد زده رو برمیگردونه. یعنی به ازای هر نمونه تو ترینینگ ست،یک حدس دریافت میکنیم.
حالا میتونیم با استفاده از تابع confusion_matrix این ماتریس رو ببینیم:

هر ردیف این ماتریس نشون دهندهی یک دسته هست و هر ستون نشون دهندهی دسته حدس زده شده ست.(این اعداد ممکنه برای شما فرق داشته باشن) اولین ردیف این ماتریس نشون دهندهی عکس های غیر 5 هست (دسته منفی): 53057 عدد به درستی بعنوان غیر 5 دسته بندی شدند (منفی های درست) در حالیکه 1522 تا به اشتباه بعنوان 5 دسته بندی شدند (مثبت های غلط). دومین ردیف نشون دهندهی عکس های 5 هست (دسته مثبت): 1325 تا به اشتباه غیر 5 دسته بندی شدند (منفی های غلط) و 4096 تا به درستی 5 دسته بندی شدند (مثبت های درست)
یک Classifier با عملکرد عالی فقط مقادیر مثبت های درست و منفی های درست خواهد داشت و باقی درایه ها صفر خواهند بود.
این ماتریس اطلاعات خوبی به ما میده اما بعضی اوقات شاید یک معیار خلاصه تر لازم داشته باشیم. میتونیم از Precision استفاده کنیم تا ببینیم دقت حدس های درست چقدر بودن:
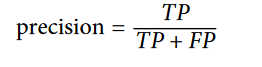
در اینجا TP به معنای True Positive( مثبت های درست) و FP به معنای False Positive(مثبت های غلط) هست.Precision همیشه با یک معیار دیگه به نام Recall استفاده میشه که نام های دیگه اون Sensitivity و True Positive Rate هست. در اینجا FN به معنای False Negative(منفی های غلط) هست.
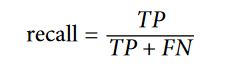
این تصویر Confusion Matrix رو به خوبی نشون میده:
کتابخانه Scikit-Learn توابع زیادی برای محاسبه معیار ها داره:

این اعداد به ما میگن وقتی مدل ادعا میکنه که یک عکس 5 هست، درواقع 72.9 درصد مواقع درست میگه و کلا 75 درصد 5 ها رو میتونه تشخیص بده.
بیشتر اوقات این دو تا معیار رو با هم ترکیب میکنن تا معیاری به نام F1 Score ساخته بشه. این معیار درواقع میانگین هارمونیک Precision و Recall هست. تفاوت این میانگین با میانگین معمولی این هست که میانگین معمولی با همه مقادیر یکسان برخورد میکنه، درحالیکه میانگین هارمونیک وزن بیشتری به مقادیر کم میده. بخاطر همین Classifier موقعی F1 Score بالایی به دست میاره که هر دوی Precision و Recall مقادیر زیادی داشته باشن.
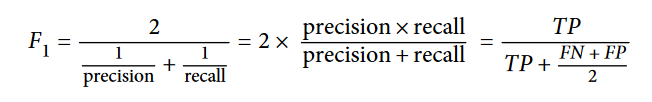
برای محاسبه هم میتونیم از تابع زیر استفاده کنیم:

البته دقت کنید که همیشه نمیخوایم F1 Score بالایی داشته باشیم. بعضی جا ها برای ما فقط مقدار Precision مهم هست و بعضی اوقات هم فقط مقدار Recall. برای مثال فرض کنید یک مدل برای تشخیص ویدئو های مناسب برای کودکان درست کردیم. توی همچین مدلی ترجیح میدیم که ویدئو های زیادی که محتوای خوبی دارن رد بشن (مقدار Recall کم) اما فقط ویدئو هایی که مناسب کودکان هستن رو نگه داره (مقدار Precision بالا). در نقطه مقابل مدلی رو در نظر بگیرید که Recall بالایی داره ولی عوضش هر از گاهی چند تا ویدئو با محتوای نامناسب هم پیشنهاد میده (در چنین مواقعی بهتره افرادی هم باشن تا ویدئو های تایید شده رو دوباره بررسی کنن). مثال دیگه فرض کنید یک مدل درست کردیم برای تشخیص دزد در عکس های دوربین های نظارتی. توی این مدل اگه Precision 30% و Recall 99% باشه مشکلی پیش نمیاد. درسته که نگهبان ها چند تا هشدار اشتباه دریافت میکنن ولی خب عوضش تقریبا همه دزد ها دستگیر میشن.
متاسفانه نمیتونیم هر دوی Precision و Recall رو با هم داشته باشیم. با افزایش Precision مقدار Recall کم میشه و برعکس.
همونطور که گفتیم، نمیتونیم هر دوی Precision و Recall رو با هم داشته باشیم که بهش میگن Precision/Recall Trade-off. برای فهمیدن این عبارت بیاید ببینیم SGDClassifier چطور تصمیم میگیره.
برای هر نمونه، مدل میاد یک امتیاز با استفاده از تابع تصمیم (Decision Function) محاسبه میکنه. اگر اون امتیاز بیشتر از یک آستانه (Threshold) باشه، اون نمونه رو جزء دسته مثبت و در غیر این صورت جزء دسته منفی قرار میده.
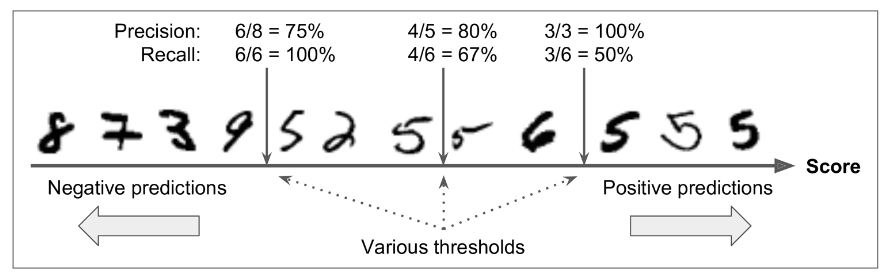
توی تصویر بالا یک سری اعداد رو میبینید که از کمترین امتیاز در سمت چپ به بیشترین امتیاز در سمت راست قرار گرفتن. فرض کنید آستانه تصمیم (Decision Threshold) در وسط قرار گرفته: در این صورت 4 تا مثبت درست (5 های واقعی) در سمت راست آستانه و 1 مثبت غلط خواهیم داشت( 6 به اشتباه 5 در نظر گرفته شده). در نتیجه، با در نظر گرفتن این آستانه، مقدار Precision 80% خواهد بود (4 تا از 5 تا). اما از 6 مورد 5 واقعی، مدل فقط 4 تاش رو میتونه تشخیص بده، پس %Recall 67 هست(4 تا از 6 تا). اگر آستانه رو افزایش بدیم (به سمت راست حرکت بدیم) مثبت های غلط (همون 6) تبدیل میشه به منفی درست و مقدار Precision به 100 افزایش پیدا میکنه. اما یکی از مثبت های درست تبدیل به یک منفی غلط میشه و Recall رو به 50 درصد کاهش میده.
کتابخانه Scikit-Learn اجازه تغییر آستانه رو به طور مستقیم به ما نمیده اما دسترسی به امتیاز های تصمیم گیری رو در اختیار میذاره. میتونیم تابع decision_function رو فراخوانی کنیم که امتیاز یک نمونه رو برگردونه و بعد بر اساس امتیاز هایی که نشون میده، میتونیم آستانه رو تغییر بدیم:

نتیجه کد بالا با تابع predict یکسان هست چون آستانه SGDClassifier برابر صفر هست. حالا آستانه رو افزایش میدیم:

این تایید میکنه که افزایش آستانه Recall رو کاهش میده. عکسی که انتخاب کردیم 5 رو نشون میده و وقتی آستانه 0 هست میتونه تشخیص بده اما وقتی آستانه به 8000 تغییر میکنه نمیتونه تشخیص بده.
چطور میفهمیم که از چه آستانه ای باید استفاده کنیم؟ اول از تابع cross_val_predict استفاده میکنیم تا امتیاز همه نمونه های ترینینگ ست رو به دست بیاریم:

حالا با این امتیاز ها، از precision_recall_curve استفاده میکنیم تا Precision و Recall برای همه آستانه ها محاسبه بشه:

و در نهایت از Matplotlib استفاده میکنیم تا مقادیر اونها رو رسم کنیم:
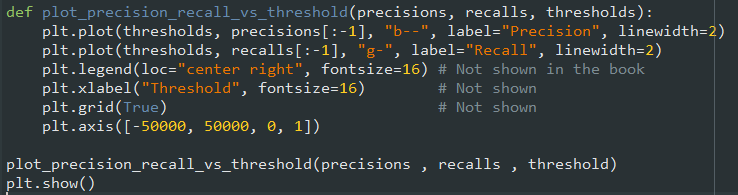
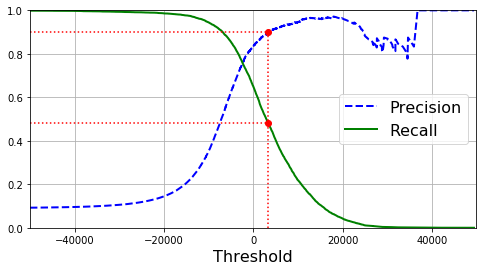
ممکنه براتون سوال پیش بیاد که چرا نمودار Precision بالا پایین بیشتری داره. علتش به این خاطر هست که بعضی اوقات وقتی آستانه رو زیاد میکنیم، Precision کاهش پیدا میکنه.(اگر چه معمولاً افزایش پیدا میکنه) اگر توی شکلی که آستانه رو توضیح میداد، آستانه رو از مرکز فقط به اندازه یک شماره به سمت راست حرکت بدیم، Precision از 4/5 یعنی 80% به 3/4 یعنی 75 درصد کاهش پیدا میکنه. در طرف مقابل، با افزایش آستانه، مقدار Recall فقط میتونه کم بشه. به همین خاطر نمودارش بالا پایین نداره.
یک راه دیگه برای انتخاب مقدار مناسب Precision/Recall اینه که این دو تا رو در برابر هم دیگه رسم کنیم. کد زیر این نمودار رو رسم میکنه:
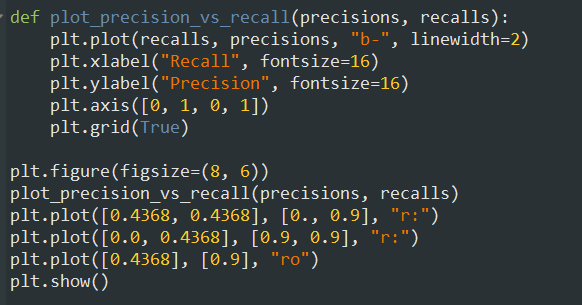
همونطور که میبینید Recall توی 80% شروع به کم شدن میکنه. پس بهتره قبل از اینکه به این عدد برسیم، مثلا دور و بر 60%، مقدار Precision و Recall رو انتخاب کنیم. البته بستگی به پروژه هم داره.
فرض کنید میخوایم به Precision 90% برسیم. یک نگاه به نمودار اول میکنیم و میبینیم که برای این کار، آستانه باید حدود 3400 باشه. اگر بخواید دقیق تر باشید، میتونید کمترین مقدار آستانه رو که به ما حداقل Precision 90% میده با استفاده از دستور زیر بدست بیارید:

برای حدس زدن، میتونید به جای تابع predict، از خط اول کد زیر استفاده کنید.توی خطوط بعد مقادیر Precision و Recall رو چک میکنیم:
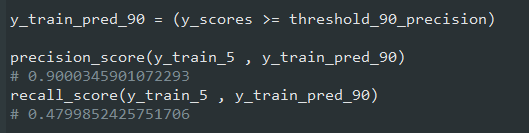
حالا تونستیم یک Classifier با Precision 90% درست کنیم. همونطور که دیدید ساخت همچین چیزی آسون بود: فقط مقدار آستانه رو باید تعیین کنید. اما خب در نظر بگیرید که مدلی که مقدار Precision بالا ولی Recall خیلی پایینی داره، خیلی کاربردی نیست!
اگه کسی بهمون گفت بیا به Precision 99% برسیم، باید بپرسید با چه مقدار Recall؟
منحنی عملیاتی دریافت کننده ( Receiver Operating Characteristic ) یا به اختصار ROC Curve یک ابزار رایج دیگه برای ارزیابی عملکرد Binary Classifier هاست. این نمودار شبیه نمودار Precision/Recall هست، اما به جای اینکه Precision رو در برابر Recall رسم کنه، True Positive Rate (همون Recall) رو در برابر False Positive Rate رسم میکنه. FPR نسبت نمونه های دسته منفی هست که به اشتباه در دسته مثبت قرار گرفتن. مقدار FPR برابر هست با یک منهای نسبت منفی واقعی(True Negative Rate). TNR نسبت نمونه های دسته منفی هست که به درستی در دسته منفی قرار گرفتن. TNR رو گاهی Specificity هم میگن. در این صورت نمودار ROC مقدار Sensitivity(Recall) رو در برابر یک منهای Specificity رسم میکنه.

برای رسم منحنی ROC اول از تابع roc_curve استفاده میکنیم تا TPR و FPR رو برای آستانه های مختلف حساب کنه:

بعد هم از Matplotlib استفاده میکنیم:
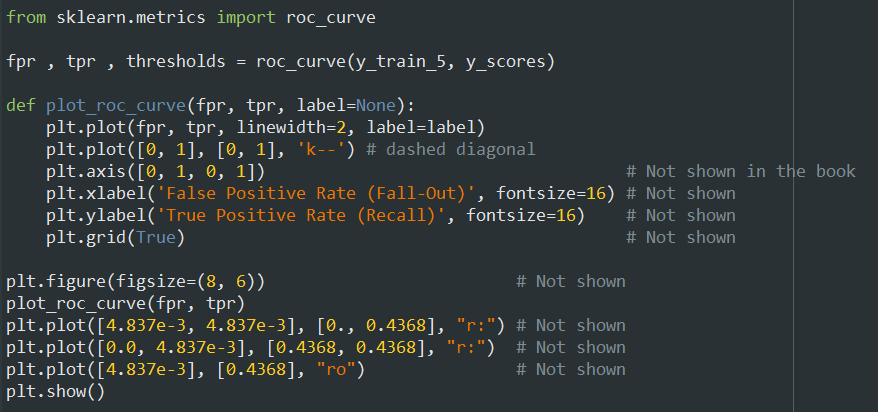
اینجا هم مبادله وجود داره: هرچقدر Recall(TPR) بالاتر باشه، مدل مثبت های غلط(FPR) بیشتری تولید میکنه. یک مدل خوب تا جایی که میشه باید از خط میانی فاصله داشته باشه و به گوشه بالا سمت چپ نزدیک باشه. اگر نمودار یک مدل به گوشه پایین سمت راست نزدیک باشه، یعنی مدل نمونه های دسته اول رو تو دسته دوم و نمونه های دسته دوم رو تو دسته اول قرار میده.
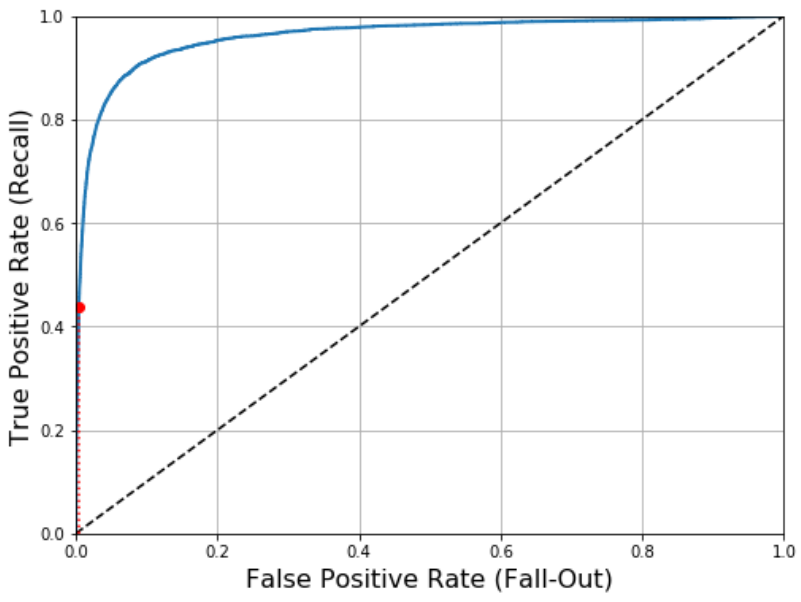
یک راه دیگه برای مقایسه Classifier ها محاسبه مساحت زیر منحنی (Area Under the Curve) یا AUC هست. یک مدل عالی ROC AUC برابر یک و یک مدل کاملا غلط ROC AUC نزدیک به 0.5 خواهد داشت. از Scikit-Learn برای محاسبه ROC AUC استفاده میکنیم:
از اونجایی که منحنی ROC شبیه به منحنی Precision/Recall هست، ممکنه براتون سوال پیش بیاد که از کدومشون باید استفاده کنیم. بر اساس قاعده سرانگشتی، اگر دسته مثبت تعداد کمی دارن یا وقتی مثبت های غلط اهمیت بیشتری برای ما دارن، استفاده از منحنی PR ارجحیت داره. در غیر این صورت از ROC استفاده میکنیم. برای مثال، توی مثال ROC قبل، ممکنه فکر کنید که عملکرد مدل عالیه. اما این به این خاطر هست که تعداد دسته مثبت یعنی 5 ها در برابر دسته منفی یعنی غیر 5 ها، خیلی کمه. در مقابل منحنی PR نشون میده که مدل هنوز جا برای بهتر شدن داره چون هنوز به اندازه کافی به گوشه بالا سمت چپ نزدیک نشده
حالا بیاید یک RandomForestClassifier ترین کنیم و عملکردش رو با SGDClassifier مقایسه کنیم. اول باید امتیاز هر نمونه در ترینینگ ست رو بهدست بیاریم. اما بخاطر متفاوت بودن عملکرد این الگوریتم، تابع decision_function نداره و به جاش باید از predict_proba استفاده کنیم. خروجی این تابع یک آرایه شامل یک ردیف برای هر نمونه و یک ستون برای هر دسته هست و هر کدوم شامل احتمال قرار گرفتن یک نمونه در هر دسته رو نشون میدن.

تابع roc_curve میتونه لیبل و امتیاز ها رو دریافت کنه ولی به جای امتیاز میتونیم احتمال هر دسته رو بدیم. توی کد زیر از احتمال دسته مثبت به عنوان امتیاز استفاده کردیم:

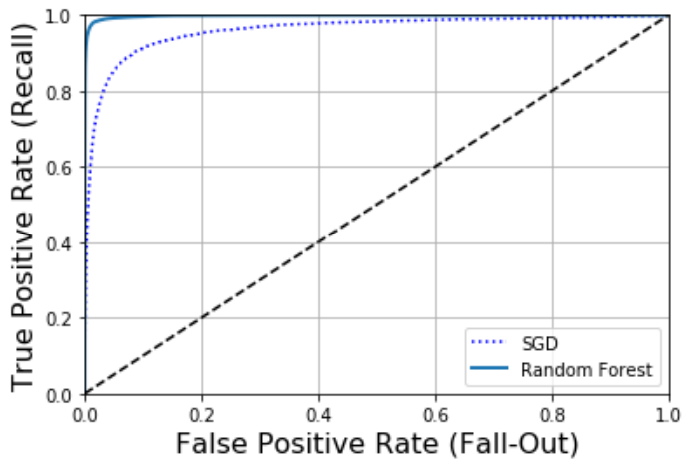
همونطور که میبینید Random Forest بهتر از SGD عمل میکنه و بیشتر به گوشه بالا سمت جپ نزدیک هست:

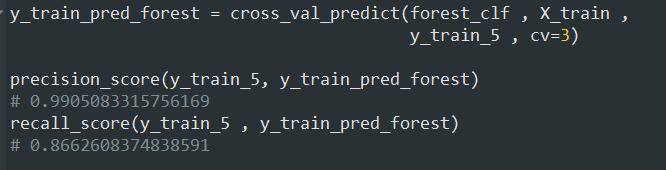
اگر بخوایم Precision و Recall رو هم حساب کنیم، اول باید تابع cross_val_predict رو فراخوانی کنیم تا حدس بزنه و بعد میتونیم اون ها رو محاسبه کنیم:
حالا میدونید که چطور یک Binary Classifier درست کنید. معیار اندازه گیری مناسب رو انتخاب کنید، با استفاده از Cross-Validation ارزیابی کنید، Precision/Recall مناسب پروژه رو انتخاب کنید و از منحنی ROC و ROC AUC استفاده کنید تا مدل های مختلف رو با هم دیگه مقایسه کنید.
حالا بیاید نمونه های دیگه رو هم تشخیص بدیم.
همونطور که دیدید Binary Classifier ها میتونن دو تا دسته رو از هم دیگه تشخیص بدن.Multiclass Classifier یا Multinomial Classifier ها میتونن بیش از دو دسته رو از هم تشخیص بدن.
بعضی الگوریتم ها مثل SGD، Random Forest Classifier و Naive Bayes Classifier میتونن چند دسته رو از هم تشخیص بدن. الگوریتم های دیگه مثل Logistic Regression و Support Vector Machine فقط میتونن دو تا دسته رو از هم تشخیص بدن. البته استراتژی هایی وجود دارن که میتونید با استفاده از اونها طبقه بندی چند دستهای رو با چند تا طبقه بندی دوتایی انجام بدید.
یک راه برای درست کردن یک سیستم که بتونه اعداد 0 تا 9 رو تشخیص بده و در یکی از 10 دسته قرار بده، این هست که بیایم 10 تا Binary Classifier درست کنیم؛ یعنی برای هر عدد، یک Classifier که بتونه اون عدد رو از بقیه تشخیص بده. بعد وقتی میخوایم یک عکس رو طبقه بندی کنیم، از هر Classifier امتیاز اون عکس رو میگیریم و در نهایت دسته ای رو انتخاب میکنیم که Classifier اون بیشترین امتیاز رو داره. به این استراتژی میگن One-Versus-The-Rest(OvR) یا One-Versus-All.
یک استرتژی دیگه این هست که بیایم برای هر جفت عدد یک Classifier درست کنیم. به این صورت که یکی اعداد 0 و 1 رو تشخیص بده، یکی 0 و 2 ، یکی 1 و 2 و الی آخر. به این استراتژی میگن One-Versus-One. اگر N تا دسته داشته باشیم، باید 2/(N *N-1) تا Classifier درست کنیم. برای دیتاست MNIST یعنی 45 تا ! وقتی میخوایم یک عکس رو دسته بندی کنیم، باید اون عکس رو برای تمام Classifier ها بفرستیم. برتری این استراتژی در این هست که هر Classifier فقط لازمه که با قسمتی از ترینینگ ست ترین بشه که باید تشخیص بده.
بعضی الگوریتم ها مثل SVM نمیتونن با دیتاست های بزرگ کار کنن. برای این الگوریتم ها OvO روش مناسبی هست چون ترین کردن تعداد زیادی Classifier روی ترینینگ ست های کوچیک، سریع تر از ترین کردن تعداد کمی Classifier روی ترینینگ ست های بزرگ هست. اگر چه برای بیشتر الگوریتم های Binary استراتژی OvR رو انتخاب میکنیم.
خود Scikit-Learn تشخیص میده که میخواید از یک الگوریتم Binary Classification برای یک کار Multiclass Classification استفاده کنید و بسته به نوع الگوریتم، بصورت خودکار از OvR یا OvO استفاده میکنه. بیاید این رو با SVM Classifier امتحان کنیم:
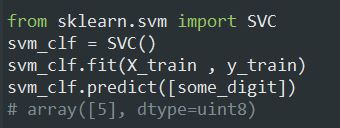
این کد SVC رو با استفاده از دسته هایی که توی y_train هست یعنی اعداد 0 تا 9، روی ترینینگ ست ترین میکنه. بعدش یک حدس درست میزنه. در واقع اتفاقی که پشت این کد میفته این هست که Scikit-Learn از استراتژی OvO استفاده میکنه: 45 تا Binary Classifier ترین میکنه و امتیاز تصمیم گیری هر کدوم رو برای عکس بدست میاره و دسته ای رو انتخاب میکنه که بیشترین امتیاز رو داره.
با فراخوانی تابع decision_function میبینید که ده تا عدد برمیگردونه که این اعداد امتیاز هر دسته برای اون عکس هستند.
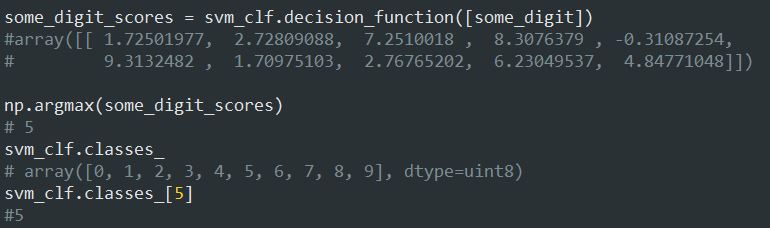
وقتی فرایند ترین یک Classifier تموم میشه، دسته ها رو به ترتیب مقدار توی _classes ذخیره میکنه. توی مثال ما، ایندکس هر دسته برابر هست با خود مقدار اون دسته (ایندکس 5 برابر دسته 5 هست) اما خب این حالت برای همه دیتاست ها رخ نمیده
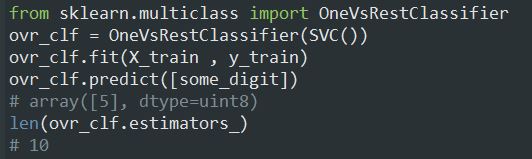
اگر بخوایم Scikit-Learn رو مجبور کنیم که از OvO یا OvR استفاده کنه، باید از کلاس OneVsOneClassifier یا OneVsRestClassifier استفاده کنیم. یک شیء میسازیم و یک Classifier رو به سازنده اون کلاس ارسال میکنیم (اجباری نیست که Binary Classifier باشه)
برای مثال کد زیر یک SVC با استفاده از استراتژی OvR درست میکنه:
ترین کردن یک SGDClassifier یا (RandomForestClassifier) به همین سادگیه. البته دقت کنید که مدل ما نتونست به خوبی 5 رو تشخیص بده و به جاش 3 حدس زده. وقتی تابع decision_function رو فراخوانی میکنیم تا امتیاز هر دسته رو ببینیم، میبینیم که مدل با اعتماد به نفس بالایی داره اشتباه حدس میزنه!

از امتیاز ها مشخصه که مدل توی انتخاب دسته 3 با امتیاز 1823 و دسته 5 با امتیاز 1385- شک میکنه. حالا میخوایم که این مدل رو ارزیابی کنیم که مثل همیشه از cross_val_score استفاده میکنیم:
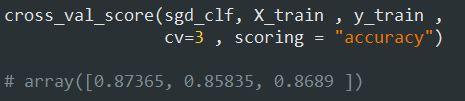
دقت مدل توی تمام تست فولد ها بالای 85% هست. توی مطلب قبلی درباره تغییر مقیاس داده ها صحبت کردیم. اینجا هم میتونیم مقیاس داده های ورودی رو تغییر بدیم تا دقت مدل کمی افزایش پیدا کنه:
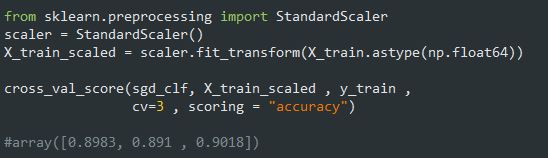
اگر این یک پروژه ماشین لرنینگ واقعی بود، الان باید تنظیماتی رو که توی مرحله آمادهسازی داده انجام دادیم، بررسی میکردیم، مدل های مختلف رو با تغییر هایپرپارامتر ها امتحان میکردیم و تا جایی که میشد روند انجام کار ها رو اتوماتیک میکردیم. ولی اینجا میخوایم فرض کنیم که این کار ها رو انجام دادیم و به یک مدل خوب رسیدیم و حالا دنبال راه هایی هستیم که عملکردش رو افزایش بدیم. یک راه برای انجام این کار آنالیز نوع خطا هایی هست که این مدل تولید میکنه.
اول به Confusion Matrix نگاه میکنیم. باید با استفاده از تابع cross_val_predict حدس بزنیم و بعد تابع confusion_matrix رو فراخوانی کنیم:
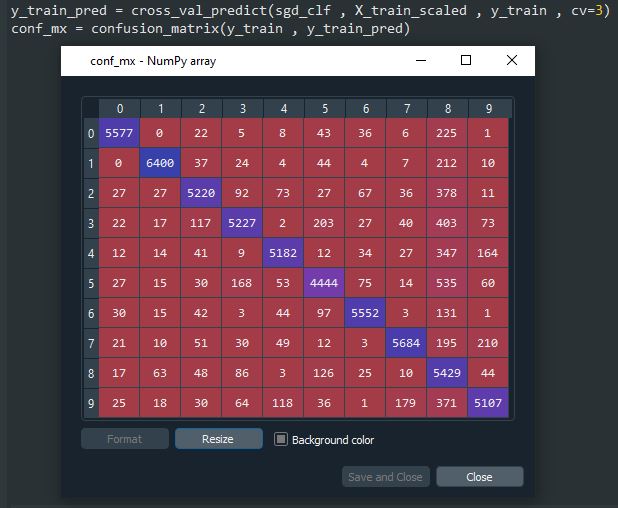
به جای نگاه کردن به این همه عدد، یک راه بهتر وجود داره. اون هم اینکه بیایم این ماتریس رو به یک عکس تبدیل کنیم:
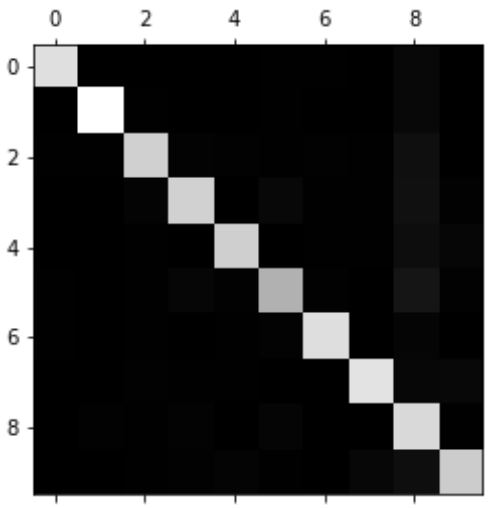
این عکس یک ماتریس خوب رو نشون میده چون بیشتر عکس ها توی قطر اصلی قرار دارن و به این معنی هست که به درستی تشخیص داده شدند. 5 ها به نسبت باقی اعداد تاریک تر هستند؛ این یا به این معناست که تعداد 5 کمی توی دیتاست هست یا به این معناست که مدل روی دسته 5 به خوبی باقی دسته ها عمل نمیکنه. یا شاید هم هر دوی این حدس ها درست باشند.
بیاید خطا ها رو رسم کنیم. به جای بررسی تعداد خطا های یک دسته ، باید نسبت این خطا ها رو با تعداد نمونه های اون دسته بررسی کنیم. با استفاده از دو خط اول این کد، تعداد نمونه های هر دسته رو به دست میاریم. بعد عدد های توی ماتریس رو تقسیم بر تعداد نمونه های هر دسته میکنیم تا نرخ خطا رو بدست بیاریم. در خط بعدی قطر اصلی ماتریس رو با صفر پر میکنیم تا فقط خطا ها نشون داده بشن و بعد نتیجه نهایی رو رسم میکنیم:
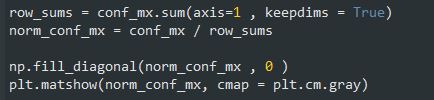
حالا به راحتی میتونیم خطا هایی رو که مدل انجام میده ببینیم. یادتون باشه ردیف ها نشون دهنده دسته های واقعی و ستون ها نشون دهنده دسته هایی که حدس زده شدن، هست. ستون 8 خیلی روشن هست یعنی خیلی از اعداد اشتباهاً بعنوان 8 شناخته میشن. وضعیت ردیف 8 زیاد بد نیست و نشون میده که 8 ها واقعا 8 شناسایی میشن. همونطور که میبینید Confusion Matrix لزوما متقارن نیست. مدل 3 ها و 5 ها رو هم با هم قاطی میکنن (در هر دو جهت)
بررسی Confusion Matrix میتونه به ما تو برطرف کردن مشکلات مدل کمک کنه. اینطور که فهمیدیم، باید یک کاری کنیم تا تعداد 8 های غلط کم بشه. برای مثال میتونیم نمونه های بیشتری از اعدادی که شبیه به 8 هستند اما در واقع 8 نیستند جمع کنیم تا مدل با دیدن اونها متوجه تفاوت بین اونها و 8 واقعی بشه. یا میتونیم فیچر های جدیدی رو اضافه کنیم تا به مدل کمک کنه. مثلا الگوریتمی بنویسیم که تعداد حلقه های بسته رو بشماره. مثلا 8 دو تا حلقه بسته داره، 6 یکی و 5 هیچی. یا میتونیم تصاویر رو پیشپردازش کنیم (با استفاده از Scikit-Image , Pillow یا OpenCV) تا بتونیم پترن هایی رو مثل همین حلقه های بسته تشخیص بدیم.
بررسی خطای هر نمونه هم راه خوبی هست چون میتونیم بفهمیم که چرا مدل یک نمونه رو نمیتونه درست تشخیص بده. البته این راه سخت تر هست و زمان بیشتری هم میبره. بیاید برای مثال دسته 3 و 5 رو رسم کنیم. کتاب برای رسم این دسته ها خودش یک تابع نوشته و توضیح خاصی نداده. میتونید این قسمت از کد رو کپی کنید:
def plot_digits(instances, images_per_row=10, **options):
size = 28
images_per_row = min(len(instances), images_per_row)
images = [instance.reshape(size,size) for instance in instances]
n_rows = (len(instances) - 1) // images_per_row + 1
row_images = []
n_empty = n_rows * images_per_row - len(instances)
images.append(np.zeros((size, size * n_empty)))
for row in range(n_rows):
rimages = images[row * images_per_row : (row + 1) * images_per_row]
row_images.append(np.concatenate(rimages, axis=1))
image = np.concatenate(row_images, axis=0)
plt.imshow(image, cmap = mpl.cm.binary, **options)
plt.axis("off")
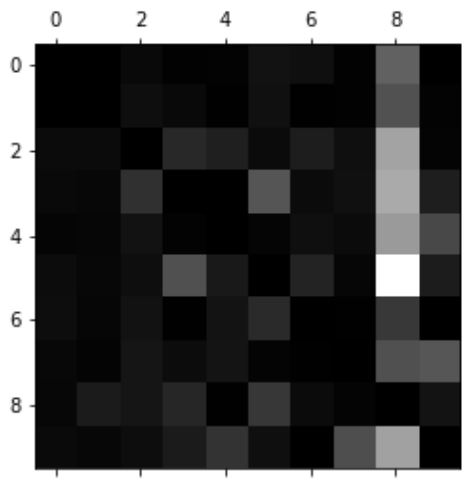
کاری که میخوایم بکنیم این هست که دسته های 3 و 5 رو در دو متغیر ذخیره کنیم. بعد بیایم عکس هایی رو که 3 بودن و 3 هم تشخیص داده شدن، 3 بودن ولی 5 تشخیص داده شدن، 5 بودن ولی 3 تشخیص داده شدن و 5 بودن و 5 هم تشخیص داده شدن رو در متغیر های مربوط به خودشون ذخیره کنیم. بعد از تابعی که بالا گفته شد استفاده میکنیم تا هر کدوم از این عکس ها رو نمایش بدیم:
نتیجه به این صورت هست:

دو بلاک 5*5 در سمت چپ نشون دهنده اعدادی هستند که در دسته 5 قرار گرفتن و دو بلاک سمت راست اعدادی هستند که در دسته 3 قرار گرفتن. بلاک های بالا سمت راست و پایین سمت چپ نمونه هایی هستند که به اشتباه تشخیص داده شدن. بعضی از این نمونه ها واقعا بد نوشته شدند و حتی برای ما هم تشخیصش سخته. اما بیشتر این عکس ها به راحتی قابل تشخیص هستند و فهمیدن اینکه چرا مدل اشتباه میکنه یکمی سخته.
اما یادتون باشه که مغز ما یک سیستم تشخیص الگوی فوق العاده قوی هست و سیستم بینایی ما قبل از اینکه اطلاعات رو به ضمیر خودآگاه ما برسونه، پیشپردازش های پیچیده ای رو انجام میده. پس اینکه حس میکنیم کار آسونی هست به این معنی نیست که واقعا کار آسونی هست
علت این اشتباه ها این هست که ما از یک SGDClassifier ساده استفاده کردیم که یک مدل خطی هست. این مدل تنها کاری که میکنه این هست که به هر پیکسل در هر دسته، یک وزن اختصاص میده و وقتی یک عکس جدید میبینه، وزن همه پیکسل ها رو جمع میکنه و به یک امتیاز برای هر دسته میرسه. از اونجایی که 3 و 5 فقط توی چند پیکسل با هم تفاوت دارن، به راحتی این دو تا دسته رو قاطی میکنه.
تفاوت اصلی بین 3 و 5 در محل قرارگیری خط کوچیکی هست که خط بالا رو به منحنی پایین وصل میکنه. اگر 3 رو به این صورت رسم کنید که اون قسمت اتصال کمی به سمت چپ کشیده شده باشه، ممکنه مدل اون رو 5 در نظر بگیره و بر عکس. به عبارت دیگه، این مدل به جهت و تغییر مکان ها حساس هست. یک راه برای کاهش این اشتباه، این هست که عکس ها رو پیشپردازش کنیم تا مطمئن بشیم که حتما به خوبی در مرکز قرار گرفتن و زیاد به اطراف تغییر جهت ندادن. این کار احتمالا بقیه خطا ها رو هم کم میکنه.
تا به اینجا هر نمونه رو در یک دسته قرار دادیم. بعضی اوقات میخوایم Classifier هر نمونه رو تو چند دسته قرار بده. مثلا یک مدل تشخیص چهره رو در نظر بگیرید: اگر بتونه چند فرد رو در یک تصویر تشخیص بده باید دقیقا چه کاری انجام بده؟ خب باید اسم هر شخصی رو که میشناسه، روی اون شخص تگ کنه. مثلا مدل ترین شده تا چهره های آلیس، باب و چارلی رو تشخیص بده. وقتی این مدل چهره آلیس و چارلی رو میبینه، خروجیش باید [1,0,1] باشه؛ یعنی آلیس بله، باب نه ، چارلی بله. به همچین مدلی که خروجیش چند تگ باینری باشه میگن Multilabel Classification.
فعلا نمیخوایم وارد تشخیص چهره بشیم. با یک مثال ساده تر شروع میکنیم.
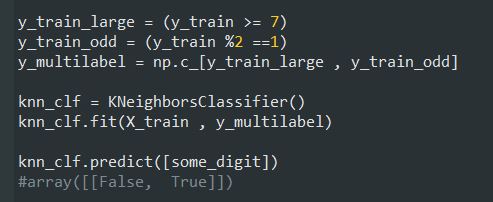
این کد یک آرایه به نام y_multilabel شامل دو لیبل برای هر عکس درست میکنه. اولین لیبل بررسی میکنه که آیا عدد بزرگ هست یا نه (7 و 8 و 9 ) و دومی بررسی میکنه که آیا فرد هست یا نه. خط بعدی یک شیء از کلاس KNeighborsClassifier درست میکنه و بعد اون رو با آرایه ای که گفتیم ترین میکنیم. بعد ازش میخوایم تا عددی که بهش میدیم رو حدس بزنه:
راه های زیادی برای ارزیابی یک Multilabel CLassifier وجود داره و انتخاب هر کدوم از این راه ها بستگی به پروژه داره. یک راه، محاسبه F1 Score (یا هر کدوم از معیار هایی که تو این مطلب گفتیم) برای هر لیبل هست. بعد میانگین F1 Score برای همه لیبل ها رو محاسبه میکنیم:

پیشفرض این تابع این هست که همه لیبل ها به یک اندازه مهم هستند اما خب بعضی اوقات شاید این صادق نباشه. اگر عکس های آلیس بیشتر از باب و چارلی باشن، بهتره که وزن بیشتری به امتیاز مدل در تشخیص عکس های آلیس بدیم. یک راه ساده اینه که به هر لیبل یک وزن برابر با support اون لیبل بدیم. support یعنی تعداد نمونه های اون لیبل. برای این کار باید بنویسیم average=weighted
آخرین نوع دسته بندی multioutput multiclass classification یا multioutput classification نام داره. در واقع نسخه تعمیم یافته multilabel classification هست. در این نوع دسته بندی، هر لیبل میتونه چند دسته باشه یعنی هر لیبل میتونه بیشتر از دو تا مقدار داشته باشه. مثال زیر رو در نظر بگیرید.
یک مدل میخوایم بسازیم که وظیفهاش حذف نویز از تصاویر هست. یک عکس نویزدار رو بعنوان ورودی میگیره و یک عکس بدون نویز رو برمیگردونه. خروجی این مدل یک آرایه از شدت هر پیکسل هست (مثل چیزی که تو دیتاست MNIST دیدیم) توجه کنید که خروجی این مدل چند لیبلی هست (به ازای هر پیکسل یک لیبل) و هر لیبل میتونه مقادیر مختلفی داشته باشه (شدت هر پیکسل بین 0 تا 255 هست)
بعضی اوقات مرز بین Classification و Regression شفاف نیست؛ مثل همین مثال. تخمین شدت یک پیکسل بهش میخوره بیشتر یک کار مربوط به Regression باشه تا Classification. همچنین مدل های Multioutput فقط محدود به Classification نیستند. حتی میشه یک مدل ساخت که خروجیش برای هر نمونه چند لیبل باشه و اون لیبل ها شامل دسته و مقدار باشن
بیاید به تصاویر دیتاست MNIST نویز اضافه کنیم. این کار رو با استفاده از تابع randint در کتابخانه NumPy انجام میدیم:
بیاید به یک عکس تست ست نگاهی بندازیم. سمت چپ همون عکس راست هست اما با نویز هایی که خودمون بهش اضافه کردیم.
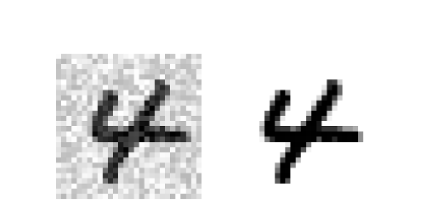
حالا بیاید مدل رو برای پاکسازی این عکس ترین کنیم:

این عکس به اندازه کافی شبیه به عکس اصلی هست.
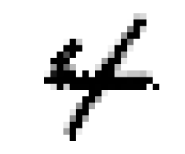
خب اینجا مطلب مربوط به دسته بندی با استفاده از دیتاست MNIST تموم میشه. حالا باید اطلاعات خوبی در مورد معیار های ارزیابی یک مدل Classification، مبادله بین Precision و Recall و Classifier های مختلف داشته باشید.
امیدوارم مفید واقع شده باشه :)