منبع اصلی این پست، دوره NLP استنفورد (CS224N) از کانال یوتیوب Stanford Online است. لطفاً برای حفظ حقوق منتشر کننده اصلی، ویدیوهارو از منبع اصلی دنبال کنید. همچنین، در انتهای هر جلسه، به ویدیو مربوط به آن جلسه ارجاع داده شده است.

سعی کردم هرچیزی که از ویدیوها فهمیدم رو به صورت متن در بیارم و در این پلتفورم با بقیه به صورت کاملاً رایگان به اشتراک بذارم. کل ویدیوها 23 تاست که سعی میکنم ماهی حداکثر یک الی دو جلسه رو منتشر کنم. تا جایی که تونستم سعی کردم خوب و کامل بنویسم، اما اگر جایی ایرادی داشت، حتما تو کامنتها بهم بگید تا درستش کنم. لازم به ذکره که برای فهم بهتر مباحث این دوره، دونستن مفاهیم پایهای در یادگیری ماشین، جبر خطی و آمار و احتمال پیشنهاد میشه.
به صورت کلی تو این جلسه قراره با زبان آدمیزاد و معنای کلمات، word2vec، مقدمات بهینهسازی و word vector ها آشنا بشیم. تو یک جمله اگه بخوام بگم، قراره ببینیم که چطور معنا و مفهومِ کلماتِ زبان آدمیزاد در قالب بردار با اعداد حقیقی نمایش داده میشه.

اول از همه، قراره یک سری موضوعات و مفاهیم کلیدیِ پردازش زبان طبیعی از جمله word vector ها، شبکههای feed-forward، شبکههای recurrent یا بازگشتی، attention، ترنسفرمرها، مدلهای encoder-decoder، تفسیرپذیری مدلها و ... رو مورد بررسی قرار بدیم. بعد یک شِمای کلی از درک زبان آدمیزاد و چالشهای فهموندن زبان آدمیزاد به کامپیوتر رو بررسی کنیم. در نهایت، ببینیم که این ابزارهای زبان طبیعی که خودمون هم در روزمره ازش استفاده میکنیم مثل ChatGPT و امثالهم چطور ساخته میشن و اگر شد خودمون هم یکی شبیهشو به کمک PyTorch بسازیم!

پدیدهای به اسم زبان و ارتباط بین انسانها حدود یک میلیون سال پیش به وجود اومده؛ که در مقایسه با قدمت حیات روی زمین، تقریباً هیچ به حساب میاد. بعدتر، حدود پنج هزار سال قبل، انسانها خط رو اختراع کردن تا بتونن ارتباطات زبانیشون رو به شکل موندگارتر و به نقاط دورتر منتقل کنن.
زبان انسان از این جهت پیچیدهست که کلمات میتونن در جاهای مختلف استفاده بشن و در کانتکستهای مختلف معانی متفاوتی رو برسونن. از وقتی که مفاهیم هوش مصنوعی و شبکه عصبی معرفی شدن، دانشمندان و محققان سعی کردن یه راهی پیدا کنن تا زبان انسان رو به نحوی به کامپیوتر بفهمونن. از خیلی سال پیش این کارها شروع شده و همچنان ادامه داره.
از اولین ابزارها تو حوزه پردازش زبان طبیعی میشه به گوگل ترنسلیت اشاره کرد. درسته که هیچوقت ترجمههاش بی ایراد و کامل نبودن مخصوصاً برای زبانهایی که کمتر در دنیا رایج هستن، ولی یکی از اولین ابزارها بوده و هنوز هم در حال توسعه دادن و بهتر کردنش هستن.
یکی از مهمترین دستاوردهای بشر تو حوزه پردازش زبان طبیعی مدل GPT-3 بوده که توسط Open AI توسعه داده شده. الان قرار نیست در مورد جزییات این مدلها بدونیم ولی خوبه در این حد بدونیم که کلیات این مدل به چه صورت کار میکنه.
قبلترها، برای هر تسکی باید میومدن یه مدل جدا و یه کلاسیفایر جدا میساختن. مثلاً یه مدل جدا برای تشخیص متنهای اسکم از غیر اسکم، یا یه مدل جدا برای تشخیص محتوای پورن از محتوای غیر پورن. ولی با اومدن مدل GPT-3 دیگه نیازی نبود برای هر تسک یه مدل و کلاسیفایر به صورت جدا جدا تعریف کرد. دلیلش هم این بود که این مدل دانش و آگاهی لازم رو نسبت به زبان، کلمات، ساختار، انواع تسکها و ... داشت. حتی تو نسخههای بعدترِ GPT این مدلها میتونستن تسکهای پیچیدهتری هم انجام بدن. مثلاً بعنوان ورودی عکس بگیرن و بعنوان خروجی برای عکس کپشن بزنن و بفهمن که تو یه عکس چه اتفاقاتی داره میفته.
خلاصه که پردازش زبان طبیعی از ورژن اولیه گوگل ترنسلیت با کلی ایراد و خطا شروع شد، با مدلهای GPT به اوج خودش رسید و هنوز هم در حال پیشرفته و هر روز کلی مدل جدید معرفی میشن که میشه باهاشون کلی کارای خفن و جدید کرد.

طبق تعریف دیکشنری، معنای یک کلمه، یعنی مفهومی (idea) که اون کلمه میخواد بهمون برسونه! ولی این بیشتر از بعد زبان شناسیه و فهموندنش به کامپیوتر کار سختیه.

یک راه حل برای فهموندن کلمات و معناشون به کامپیوتر این بوده که اومدن یک سری دیکشنری تعریف کردن مثل WordNet که توش برای کلمات مترادفها و hypernym ها رو نگهداری میکنه. ترادف که مشخصه چیه. منظور از hypernym کلمهای هست که معناش کلی تره و چندین کلمه دیگه رو در بر میگیره. مثلاً واژه "حیوان" hypernym (فرارده) هست برای کلمات "اسب" و "روباه" و "خرس" که به این کلمات جزئی تر hyponym (زیررده) میگن.

اما ... این روش یک سری ایرادات داره. سه تا از مهمتریناشو در ادامه بهش اشاره میکنیم.
اول اینکه نمیشه بین کلماتِ مترادف تمایز قائل شد. دو کلمهی خوب و خفن میتونن مترادف باشن، ولی ما بعنوان انسان میفهمیم که باهم دیگه فرق دارن، ولی این تفاوت رو نمیشه توی این مدل دیکشنریها مشخص کرد.
دوم اینکه کلماتش محدود و قدیمی هستن و زبان یک چیز داینامیکه و هر روز یک سری کلمات جدید به وجود میان، ولی این مدل دیکشنریها کلمات جدید رو در بر نمیگیرن و نمیشه حتی به روزش هم کرد.
سوم هم اینکه نمیشه با این روش به صورت دقیق تشابه بین کلمات رو محاسبه کرد. در ادامه این مورد رو بیشتر توضیح میدیم.

خب مشکل چیه؟ خیلی قبلتر یکی از تکنیکها برای مدل کردن کلمات از زبان آدمیزاد به زبان کامپیوتر، استفاده از بردارهای one-hot بود. به این صورت که به ازای هر کلمه داخل دیکشنری یک بُعد در نظر میگرفتن، برای تمام بُعدهای دیگه صفر و برای بعدی که متناظر با کلمهای بود که میخواستن یک در نظر میگرفتن. یک روش گسسته کلاسیک صرفاً برای مدل کردن کلمات.
این روش چه ایرادی داره؟ اول از همه سایزش! گفتیم که به ازای هر کلمه یک بُعد در نظر میگرفتن، پس منطقاً نمیشه باهاش تمام کلمات یک زبان رو نمایش داد!

مشکل بعدی اینکه نمیشه باهاش شباهت بین کلمات رو نشون داد. چرا؟ چون با این تکنیک همیشه فقط یکی از ابعاد مقدارش یکه و بقیه صفر، یعنی اینکه تمام بردارها به هم دیگه عمودن! عملاً بین بردارهای عمود هم شباهتی نداریم! پس نمیشه با این روش شباهت بین کلمات رو تعریف کنیم. راه حل چیه؟ بیایم بردارهایی رو تعریف کنیم که شباهت بین کلمات رو خودشون بفهمن و یاد بگیرن!

چجوری این کارو انجام بدیم؟ از distributional semantic استفاده کنیم.به این معنی که بیایم به جای خود کلمه، از کلمات مجاور کلمهای که دنبالش هستیم استفاده کنیم تا معنای کلمه مورد نظر رو در بیاریم. به کلمات مجاور context میگیم و خود کلمه اصلی رو target مینامیم. مثلاً کلمه banking رو که تو اسلاید پایین آورده شده در نظر بگیرید. با توجه به اینکه کلمات context چی هستن، میتونیم بفهمیم که معناش در هر جمله چیه.
همین جا نیازه که دو تا تعریف داشته باشیم از type و token چون در ادامه هی قراره بهشون اشاره کنیم. پس بهتره که بدونیم چی هستن. مثلاً همین کلمه banking رو در نظر بگیرید. تو سه جمله متفاوت با سه معنی مختلف اومده، پس کلمه banking یه جور type به حساب میاد. از طرفی دیگه، هر جمله رو میتونیم به کلمات تشکیل دهندهش تجزیه کنیم، به این کلمات token گفته میشه.

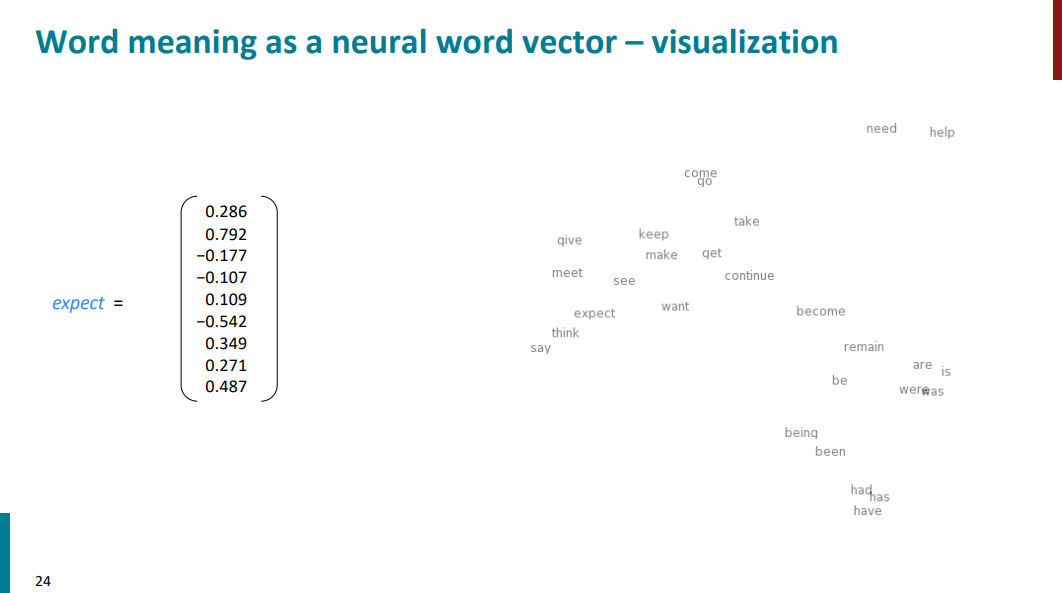
بالاتر دیدیم که برای مدل کردن معنای کلمات در ابتدا اومدن از بردارهای گسسته با محتوای 0 و 1 استفاده کردن و گفتیم که این روش خوبی نیست. در ادامه اومدیم گفتیم ازdistributional semantic استفاده میکنیم که میاد از کلمات context استفاده میکنه تا معنای کلمه target رو مدل کنه. در نهایت قراره به چجور برداری برسیم؟ بردارهایی که به جای گسسته بودن و شامل 0 و 1 بودن، قراره شامل اعداد حقیقی باشن و به نحو بهتری معنای کلمات رو نمایش بدن. به عبارتی دیگه، به جای اینکه معنی هر کلمه فقط در یک بعد قرار بگیره (یک بعد 1 بقیه ابعاد 0)، تو کل ابعاد قراره پخش بشه. تو مثال پایین برداری که برای نشون دادن معنی کلمات اومده فقط 8 بعد داره، در حالیکه، در مثالها و کاربردهای واقعی این بردارها 300 بعد دارن. به این بردارها word embedding هم گفته میشه.

با این روش معنای کلمات بهتر با اعداد و بردارها تعریف میشه. از اونجایی که مغز انسان درکی از 300 بعد یا حتی 8 بعد نداره، برای اینکه بفهمیم آیا واقعا معنای کلمات به درستی با این روش تعریف میشن یا نه، اومدیم صرفاً از دو بعد استفاده کردیم و چند تا از کلمات مختلف رو که با این روش امبد شده بودن رو تو اسلاید پایین نمایش دادیم. وقتی از 300 بعد فقط دو بعد رو نگه میداریم در واقع درصد خیلی زیادی از اطلاعات رو داریم دور میریزیم، اما با این حال باز هم تا حد خوبی میشه تمایز بین کلمات رو دید. مثلاً تو اسلاید زیر افعال had و has و have تو یک گروه کنار هم قرار گرفتن یا اینکه افعال need و help هم نزدیک هم هستن. این مثال نشون میده که با این روش چطور کامپیوترها میتونن تا حد خیلی خوبی معنای کلمات رو به همون صورتی که انسانها درک میکنن درک کنن.
الگوریتم word2vec سال 2013 توسط Mikolov معرفی شد. شامل دو تا الگوریتم داخل خودش میشه به اسمهای Skip-Gram و CBOW (Continuous Bag of Words). در ادامه جزییات بیشتری رو در موردش خواهیم دید.
در نهایت کاری که word2vec میخواد بکنه همین چیزیه که تا اینجای کار دیدیم. قراره معنای کلمات رو با استفاده از اعداد حقیقی در قالب یک سری بردار نمایش بده. به عبارتی دیگه، قراره معنای کلمات رو با توجه به جملهای که اون کلمه توش اومده یاد بگیره. چجوری؟
به این صورت که اول یک پیکره داریم (منظور از پیکره تعداد زیادی متن و نوشتهست). یک لیست از کلمات داریم و هر کلمه رو با یک بردار نمایش میدیم. به ازای هر کلمه، target (یا center) و context تعریف میکنیم. اگر کلمهای رو بعنوان center در نظر بگیریم، منظور از context کلمات همسایه و کناریش هستن. در ادامه کلمهی target رو با c و کلمات context رو با o نمایش میدیم. کل الگوریتم قراره دو تا احتمال حساب کنه و به دنبال مقدار ماکسیمم این احتمال باشه:
احتمال اول: اگر کلمات context یا کناری رو داشته باشیم کدوم کلمه با احتمال بیشتری میتونه target باشه؟ (ایده کلی الگوریتم CBOW)
احتمال دوم: اگر کلمه center یا target رو داشته باشیم کدوم کلمات بعنوان context و کلمات همسایه محتملتر خواهند بود؟ (ایده کلی الگوریتم Skip-Gram)
در نهایت به ازای هر کلمه دو تا بردار احتمالاتی محاسبه میشه، اولیش اینکه اگر کلمه در نقش target باشه و دومیش هم اینکه اگر کلمه در نقش context باشه.
بریم در ادامه یکی دو تا مثال ببینیم تا مطالب بهتر جا بیفته.

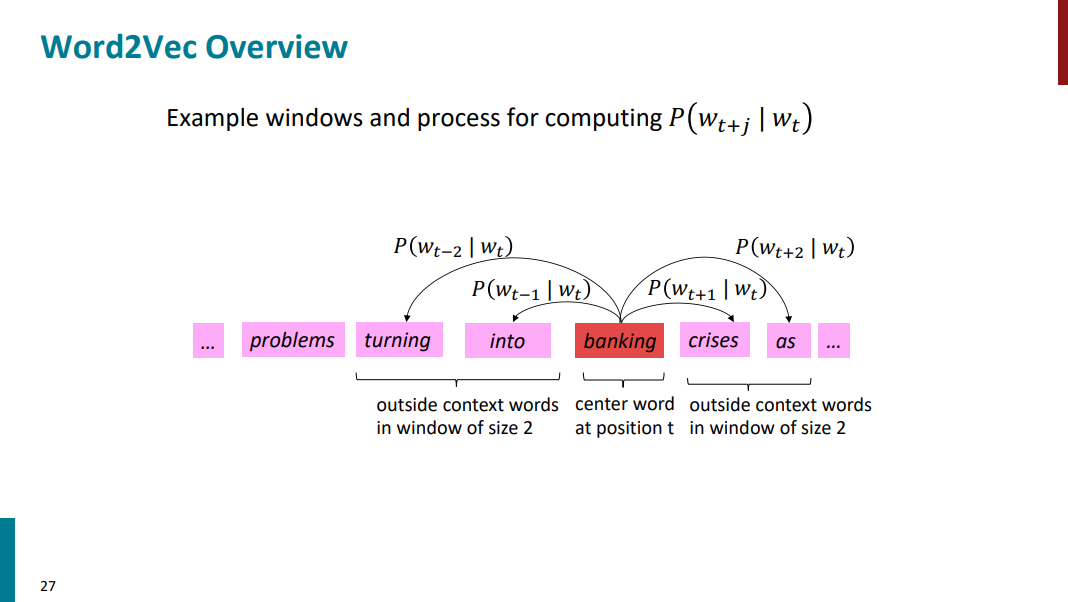
فرض کنید یه متنی داریم مثل اسلاید پایین و کلمه into رو بعنوان center با اندیس t انتخاب کردیم. خود کلمه into رو به صورت w_t نشون میدیم. (منظورمون از اندیس صرفاً شمارهایه که به اون کلمه دادیم، مثلا 0، 1، 2 و ... تا رسیدیم به شمارهی t. وقتی میگیم t-1 یعنی اندیس یک کلمه قبل از کلمه با اندیس t، وقتی میگیم t+1 یعنی اندیس یک کلمه بعد از اون و همینطور برای t-2 و t+2 که یعنی اندیس دو کلمه قبل و اندیس دو کلمه بعد و الی آخر. خود کلمات رو با w نشون میدیم. مثلاً w_t-1 یعنی یک کلمه قبل از w_t و یا w_t+1 یعنی یک کلمه بعد از w_t).
بالاتر گفتیم دو مدل کلمه در نظر میگیریم. یا target / center یا context. تو مثال پایین کلمه into بعنوان target در نظر گرفته شده و کلمات کناریش بعنوان context. حالا یه سوال. چند تا کلمه بعد و قبل از target رو بعنوان context در نظر بگیریم؟ اینجاست که میایم و window تعریف میکنیم برای کلمات کناری که مشخص بشه چقدر دورتر قراره بریم و چند تا کلمه کناری رو قراره در نظر بگیریم. تو مثالی که داریم پنجره یا window برابر با 2 هست. به این معنی که دو تا کلمه بعد و دو تا کلمه قبل از target رو بعنوان context در نظر گرفتیم.
حالا قراره بیایم و به صورت خاص تو این مثال 4 تا احتمال محاسبه کنیم. (چرا 4 تا؟ چون پنجره رو 2 در نظر گرفتیم، 2 تا کلمه قبل و 2 تا کلمه بعد از کلمه target پس میشه 4 تا احتمال!) احتمالاتی که قراره حساب کنیم به شرح زیره:
احتمال P(w_t+1 | w_t): اگر کلمه into رو بعنوان target داشته باشیم، با چه احتمالی کلمه banking بعد از into میاد؟
احتمال P(w_t-1 | w_t): اگر کلمه into رو بعنوان target داشته باشیم، با چه احتمالی کلمه turning قبل از into میاد؟
احتمال P(w_t+2 | w_t): اگر کلمه into رو بعنوان target داشته باشیم، با چه احتمالی کلمه crises دو تا بعد از into میاد؟
احتمال P(w_t-2 | w_t): اگر کلمه into رو بعنوان target داشته باشیم، با چه احتمالی کلمه problems دو تا قبل از into میاد؟

این محاسبات انجام میشه. تو گام بعدی میایم کلمه target رو به banking تغییر میدیم و دوباره احتمالات بالا رو با کلمات context و target جدید محاسبه میکنیم.
حالا سوال پیش میاد که این احتمالات چجوری حساب میشن؟ در ادامه قراره جزییات این محاسبات رو ببینیم!
تا اینجا گفتیم چی؟ گفتیم هر دفعه میایم یک کلمه رو بعنوان target در نظر میگیریم و بعد یک پنجره برای تعداد کلمات context در نظر میگیریم. بعد احتمال کلمات context رو با توجه به اون کلمه target محاسبه میکنیم. در نهایت احتمالاتی که به دست آوردیم رو در هم ضرب میکنیم و میریم سراغ کلمهی بعدی و دوباره همین پروسه رو تکرار میکنیم. تعریف ریاضی این چیزایی که گفتیم میشه likelihood که تو اسلاید پایین آورده شده.
اول کار گفتیم که کل کار الگوریتم word2vec اینکه یاد بگیره. پروسه یادگیری همیشه با یک تابع loss یا cost یا objective یا تابع هزینه همراهه که قراره طی فرایند یادگیری مقدارش رفته رفته هی کمتر و کمتر بشه (به عبارتی دیگه، قراره که مقدار likelihood بیشینه بشه). تابع هزینه تو الگوریتم skip-gram به صورتی که تو اسلاید پایین آورده شده محاسبه میشه.

حالا یک سوال! چرا تابع هزینه یهو اینقدر متفاوت از تابع likelihood شد؟ اصلاً چه رابطهای بین تابع likelihood و تابع هزینه یا objective هست؟ مگه ما نگفتیم میخوایم likelihood رو بیشینه کنیم، پس چرا مستقیم نمیایم از خود likelihood برای بیشینه کردن احتمال استفاده کنیم و نیازه که بیایم تابع objective تعریف کنیم و اون رو کمینه کنیم؟
قضیه اینکه تو تابع likelihood ما میایم یه سری احتمال که اعداد بین 0 تا 1 هستن رو هر دفعه در هم ضرب میکنیم. وقتی تعداد این ضربها زیاد و زیادتر بشه، عدد نهایی به 0 میل میکنه! این چیزی نیست که ما دنبالش باشیم! پس میایم چیکار میکنیم؟ به جای اینکه مستقیم از خود likelihood استفاده کنیم و بخوایم اون رو بیشینه کنیم، میایم اول از likelihood لگاریتم میگیریم. پس ضربهارو تبدیل به جمع میکنیم تا مشکل صفر شدن رو حل کنیم. بعد میایم یه منفی پشتش میذاریم. چرا؟ چون تو تسکهای ماشین لرنینگ همیشه دنبال نقطه کمینه هستیم دلیل خاصی نداره! به جای اینکه بخوایم تو تابع likelihood دنبال ماکسیمم بگردیم (بدون منفی)، اسمشو عوض میکنیم میذاریم تابع هزینه، یه منفی پشتش میذاریم و دنبال مینیمم میگردیم.حالا الان تابع هزینه داریم و دنبال این هستیم که تا اونجایی که میتونیم این مقدار منفی و هزینه رو کمینه کنیم.
حالا یک سوال دیگه، اون ضریب 1 بر روی T (تعداد کل کلمات پیکره) که قبل از جمعها اومده چیه؟ چرا اصلاً نیازه که داشته باشیمش؟
در یک کلمه، برای نرمال سازی اومده. فرض کنید نباشه، چه اتفاقی میافته؟ قبول دارید که داریم یک سری احتمال رو باهم جمع میکنیم دیگه؟ هرچی تعداد کلمات متن بیشتر باشه، حاصل این جمعها عدد بزرگتری میشه. این خوب نیست! چجوری این مشکل رو حل کنیم و تابع هزینه رو مستقل از تعداد کلماتِ متن کنیم؟ بیایم بر تعداد کلمات متن تقسیم کنیم و یه جور میانگینگیری و نرمالسازی کنیم. به همین سادگی!
خب، تونستیم از روی تابع likelihood تابع هزینه رو به صورتی که تو اسلاید پایین آورده شده بسازیم و قراره دنبال مقدار کمینه براش باشیم. حالا سوال! چجوری قراره اصلاً این احتمالات (احتمال کلمات context رو وقتی هر دفعه کلمه target رو داریم) رو حساب کنیم که اصلاً بخوایم باهم دیگه جمعشون کنیم؟
خیلی بالاتر گفتیم که تو الگوریتم word2vec هر کلمه دو تا نقش داره، یا target هست یا context. پس دو تا بردار در نظر میگیریم، یکی برای وقتی که کلمات نقش target یا center دارن و یکی هم برای وقتی که کلمات نقش context دارن. در ادامه خواهیم دید که قراره از این دو بردار چه استفادهای بکنیم.

وقتی میگیم بردار، منظورمون چنین چیزیه مثلاً (9 تا کلمه و 1 بعد داشته باشیم):

قراره احتمال حساب کنیم، احتمالِ چی؟ احتمال P(o | c). به این معنی که اگر یک کلمهای مثل c بعنوان target یا center بهمون داده باشن، با چه احتمالی کلمه (یا کلمات o) در مجاورت کلمه c قرار میگیرن؟ (به زبان ساده، کلمه وسطی رو بهمون دادن، قراره بیایم احتمال کلمات همسایه رو حساب کنیم.) قراره بیایم از تابع softmax استفاده کنیم. اگه از قبل آشنایی با مباحث ماشین لرنینگ یا دیپ لرنینگ داشته باشید میدونید softmax چیه، ولی اگر نمیدونید، خیلی چیز عجیب غریبی نیست، کل کاری که میکنه اینکه هر عددی رو تو بازه حقیقی بعنوان ورودی میگیره و میبرتش تو بازهی 0 تا 1.به صورت دقیقتر محاسباتی که انجام میده سه مرحله داره:
اول: میخوایم ببینیم کلمه وسطی c و کلمات مجاور o چقدر بهم شبیه هستن. چجوری این شباهت رو حساب کنیم؟ از ضرب داخلی کمک میگیریم. هر چقدر عدد حاصل به سمت مثبت بینهایت نزدیکتر باشه و بزرگتر باشه یعنی شباهت بیشتره. هر چقدر عدد حاصل کوچیکتر و منفیتر باشه، یعنی شباهت کمتره.
دوم: خروجی مرحله قبل رو بعنوان ورودی میدیم به تابع نمایی. چرا؟ برای اینکه تو مرحله قبلی، هر عددی میتونیم داشته باشیم، حتی اعداد منفی! ولی وقتی میخوایم احتمال حساب کنیم نمیتونیم اعداد منفی داشته باشیم که! پس باید به طریقی همه اعداد مرحله قبل رو مثبت کنیم و اعداد منفی رو از بین ببریم.
سوم: مرحله اول و دوم رو به ازای تمام واژگانی که داریم تکرار میکنیم و حاصل هر مرحله رو جمع میکنیم. یک کسر تعریف میکنیم عدد حاصل از این جمع رو میذاریم تو مخرج. صورت کسر هم میشه خروجی مرحله دوم. چرا نیاز بود این کسر رو تعریف کنیم؟ یه جور نرمال سازیه. به این دلیل که میخوایم عددی که برای هر کلمه حساب میکنیم در نهایت جمع همشون باهم به 1 برسه و بین 0 تا 1 باشه. (قراره در نهایت احتمال حساب کنیم دیگه.)
کل مراحلی که توضیح دادیم به زبان ریاضی تو اسلاید پایین آورده شده.
حالا چرا به این تابع (و محاسباتی که دیدیم) میگن softmax؟ چرا max؟ چون هرچی x_i (ورودی) بزرگتر باشه، احتمالی هم که بهش اختصاص داده میشه (خروجی) بیشتره. چرا soft؟ چون حتی مقادیر خیلی کوچیک هم همچنان یک احتمالی بهشون تخصیص داده میشه و احتمال مقادیر خیلی کوچیک معادل صفر نیست.

گفتیم که برای هر کلمه دو تا وکتور در نظر میگیریم. به صورت دقیقتر، کل این دو تا وکتور با تتا نمایش داده میشن و ابعاد تتا برابره با 2 (چون دو تا وکتور داریم برای هر کلمه) در d در V. منظور از d ابعادی هست که داریم و منظور از V تعداد کلماتی که در نظر گرفتیم. هدف این بود که بیایم بهترین مقدار این پارامتر تتا رو حساب کنیم به صورتی که تابع هزینه کمینه بشه. به زبان ریاضی برای پیدا کردن مینمم تابع هزینه باید بیایم از گرادیان کاهشی استفاده کنیم. اینکه گرادیان کاهشی چیه و چه جزییاتی داره تو این پست بهش پرداخته شده. در ادامه خواهیم دید که چطور از مشتق زنجیرهای استفاده میکنیم تا بتونیم گرادیان رو حساب کنیم.
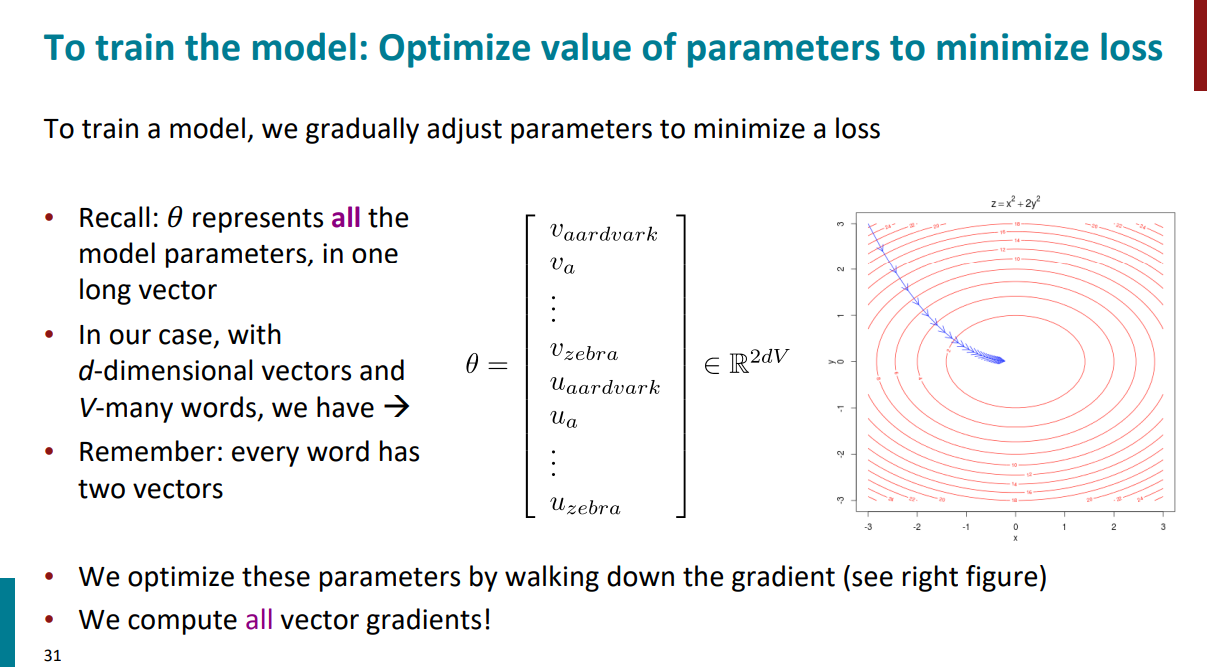
به صورت خیلی کلی، گرادیان یک تابع یعنی بیایم از تمام پارامترهای اون تابع نسبت به متغیر خودشون مشتق بگیریم (یعنی هر پارامتر تابع رو جداگانه در نظر میگیریم و نسبت به همون پارامتر مشتق میگیریم، نه نسبت به یک متغیر ثابت برای همه) و همهی این مشتقها رو کنار هم در قالب یک بردار داشته باشیم. حالا ما قراره چیکار کنیم؟ قراره بیایم از تابع هزینه (که بالاتر تعریف کردیم) نسبت به تتا (دو برداری که برای کلمات در نظر گرفتیم) مشتق بگیریم و ببینیم که چطور میشه!
در ادامه قراره یکم جزییات ریاضی ببینیم!
از ابتدای این جلسه یک تابع likelihood داشتیم که قرار بود ببینیم به ازای کدوم مقادیر تتا بیشینه میشه! با جزییاتی که قبلاً مفصلاً توضیح دادیم، اومدیم از روی likelihood تابع هزینه رو ساختیم و قرار بود ببینیم که به ازای کدوم مقادیر تتا کمینه میشه! بعد تر هم دیدیم که چطور قراره به کمک تابع softmax احتمالی که دنبالش هستیم رو حساب کنیم. ترجمه ریاضی همه چیزایی که تا اینجا گفتیم تو عکس پایین اومده:

گفتیم که قراره بیایم از تابع هزینه نسبت به پارامتر تتا مشتق بگیریم. پارامتر تتا خودش حاوی دو بردار U و V است. پس یعنی باید بیایم یک بار از تابع هزینه نسبت به بردار V مشتق بگیریم و یک بار از تابع هزینه نسبت به بردار U مشتق بگیریم و در نهایت همهی این مشتقها رو در قالب یک بردار کنار هم داشته باشیم.
اول از همه بریم جزییات مربوط به مشتق گرفتن از تابع هزینه نسبت به بردار V رو بررسی کنیم. تو تصویر زیر جزییات محاسبات در هر مرحله آورده شده. تو تصویر زیر میبینیم که چطور مشتق صورت کسر محاسبه میشه.

برای مشتق گرفتن از مخرج کسر (عبارت b تصویر بالا)، باید بیایم از قوانین مشتق زنجیرهای استفاده کنیم. فرض کنید دو تا تابع f و g رو داریم (تابع g داخل تابع f) و قراره که از تابع f(g(v_c)) نسبت به v_c مشتق بگیریم. تابع f تابع لگاریتمه و تابع g بعد از کمی تغییر، همون تابع softmax عه که بالاتر باهاش آشنا شدیم. جزییات محاسبات در هر مرحله تو تصویر زیر آورده شده. در نهایت، داریم از مقدار واقعی (observed) مقدار expected (پیش بینی مدل) رو کم میکنیم و دنبال این هستیم که این اختلاف رو کمتر و کمتر کنیم. به عبارتی دیگه، مقدار پیش بینی مدل رو به مقادیر واقعی نزدیک کنیم.

تا اینجا اومدیم مشتق تابع هزینه رو نسبت بهcenter vector محاسبه کردیم. همچنین نیاز داریم که از تابع هزینه نسبت به context vector هم مشتق بگیریم تا بتونیم تابع هزینه رو در نهایت نسبت به پارامتر تتا کمینه کنیم. از اونجایی که محاسباتش خیلی شبیه چیزهایی هست که تا اینجا دیدیم از آوردنش صرف نظر شده و میتونید خودتون هم محاسبه کنید. (این مورد رو بعنوان یادداشت اضافه انجام میدم و تو کانال تلگرامم به اشتراک میذارم.)
یکی از کتابخونههای پردازش زبان طبیعی تو پایتون که الگوریتم word2vec رو پیادهسازی کرده، اسمش Gensim عه. میشه باهاش کارهای جالبی کرد. مثلاً شباهت بین کلمات مختلف رو محاسبه کرد یا حتی outlier بین یه گروه کلمه رو پیدا کرد. (مثلاً بین کلمات آتش، آب، زمین، دریا، هوا و ماشین، کلمه ماشین outlier به حساب میاد.) یا حتی میشه ازش برای word analogy یا قیاس بین کلمات استفاده کرد. برای مثال کلمه queen معادل هست با اینکه بیایم از کلمه king کلمه man رو حذف کنیم و بهش کلمه woman رو اضافه کنیم. خلاصه از اونجایی که برای هر کلمه embedding داریم، میتونیم با یک سری عملیات جمع و تفریق بین کلمات کارای جالبی بکنیم و به جوابهای درستی هم برسیم!

دیدیم که زبان انسان چطور میتونه پیچیده باشه و چقدر پیچیدهتر میشه وقتی که میخوایم زبان و معانیای رو که خودمون ازش درک انسانی داریم به کامپیوتر بفهمونیم. با الگوریتم word2vec آشنا شدیم و دیدیم که به صورت کلی چطور کار میکنه. البته این الگوریتم جزییات دیگهای هم داره که در جلسات آینده قراره بهش پرداخته بشه.
اگر جایی ایراد یا مشکلی بود، حتماً بهم بگید تا تصحیح کنم. اگر هم پست رو دوست داشتید و محتواش به دردتون خورد، میتونید یه قهوه مهمونم کنید!