منبع اصلی این پست، دوره NLP استنفورد (CS224N) از کانال یوتیوب Stanford Online است. لطفاً برای حفظ حقوق منتشر کننده اصلی، ویدیوهارو از منبع اصلی دنبال کنید. همچنین، در انتهای هر جلسه، به ویدیو مربوط به آن جلسه ارجاع داده شده است.

سعی کردم هرچیزی که از ویدیوها فهمیدم رو به صورت متن در بیارم و در این پلتفورم با بقیه به صورت کاملاً رایگان به اشتراک بذارم. کل ویدیوها 23 تاست که سعی میکنم ماهی حداکثر یک الی دو جلسه رو منتشر کنم. تا جایی که تونستم سعی کردم خوب و کامل بنویسم، اما اگر جایی ایرادی داشت، حتما تو کامنتها بهم بگید تا درستش کنم. لازم به ذکره که برای فهم بهتر مباحث این دوره، دونستن مفاهیم پایهای در یادگیری ماشین، جبر خطی و آمار و احتمال پیشنهاد میشه.
به صورت خیلی کلی، پرونده word2vec رو میبندیم و همچنین با مدل GloVe آشنا میشیم. خلاصه که بعد این جلسه میتونید برید هرچی مقاله و پیپر در مورد word embedding هست بخونید و بفهمید! (ایشالا که همینطور باشه!)

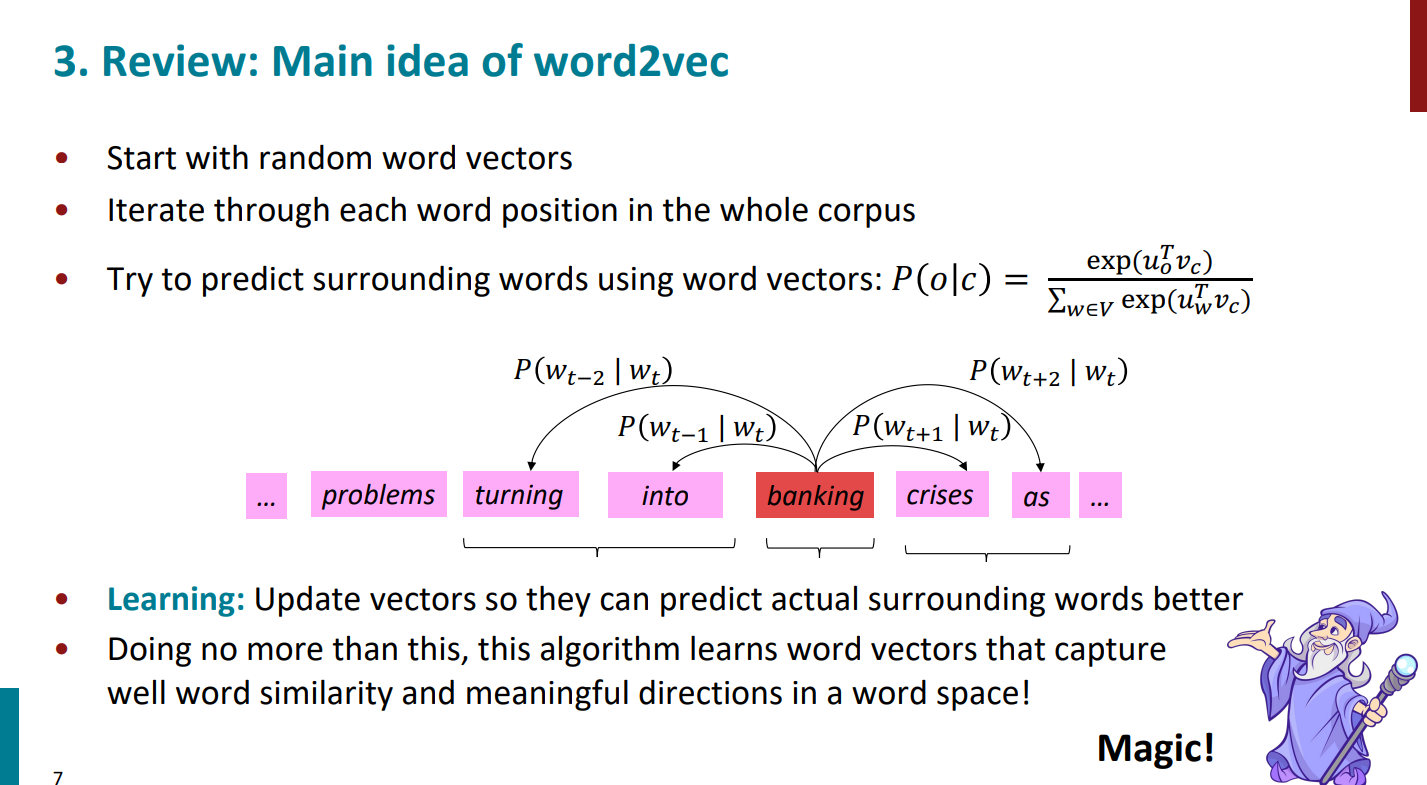
خب برگردیم به word2vec. همونطور که در جلسه قبل دیدیم، اینطور بود که یک پیکره از تعداد خیلی زیادی کلمه داشتیم. برای شروع مقدار رندومی رو واسه بردار کلمات در نظر میگرفتیم. قرار بود احتمال کلمات context رو به طوری که کلمه center رو بهمون داده بودن حساب کنیم. به کمک ضرب داخلی شباهت بین کلمات رو حساب میکردیم و در نهایت تابع softmax بهمون کمک میکرد که این احتمالات رو محاسبه کنیم. هر دفعه بردار کلمات رو با وزنهای جدید آپدیت میکردیم و بهترین جواب وقتی بود که تابع هزینه مقدارش مینیمم بشه.
گفتیم که الگوریتم word2vec شامل دو الگوریتم داخل خودش هست، یکی skip-gram و یکی continuous bag of words (CBOW). در حقیقت word2vec نسخهی یکم پیشرفتهتر مدل bag of word هست، به این دلیل که برای این مدلها و حتی word2vec ترتیب کلمات اهمیتی نداره. درسته که تو word2vec یک فاز یادگیری برای شباهت بین کلمات داریم و تو bag of words نداریم، اما چون تو جفتشون ترتیب کلمات مهم نیستن، پس ذاتاً شبیه هم دیگهن. خلاصه که در مقایسه با الگوریتمهای دیگهی پردازش زبان طبیعی word2vec خیلی ابتدایی داره عمل میکنه.
تو اسلاید زیر به کمک روش PCA خروجی word2vec از 300 بعد به 2 بعد کاهش پیدا کرده. اگه نمیدونید PCA چیه تو این پست میتونید در موردش بخونید. همونطور که مشخصه کلمات شبیه به هم خیلی نزدیک بهم قرار گرفتن. مثلاً سامسونگ و نوکیا کنار هم دیگهن یا یاهو و گوگل هم همینطور. تو مثال زیر چون پیکرهای که word2vec روش train شده قدیمی بوده، کلماتش اینطورن و شامل کلمات جدید نمیشن.

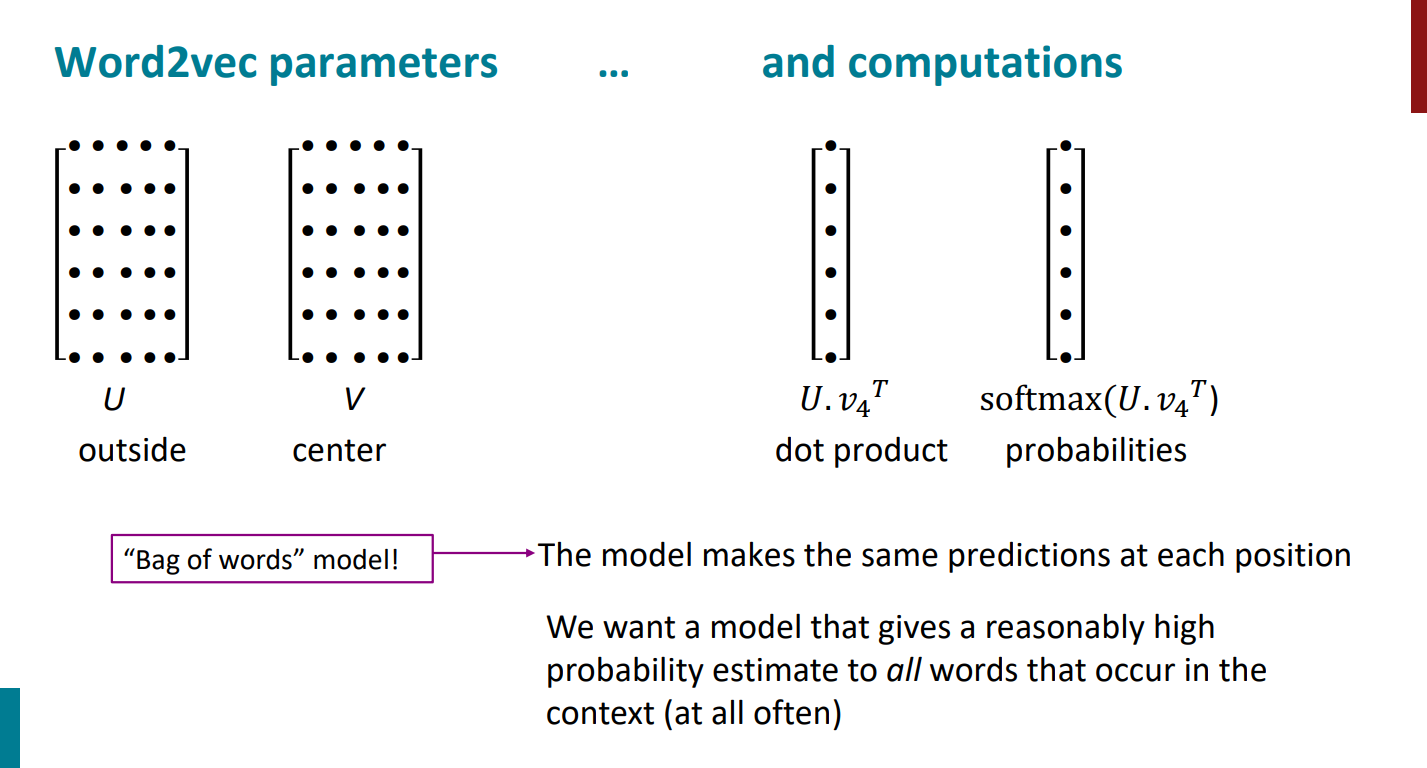
حالا چجوری قراره بردارهای U و V رو به بهترین شکل یاد بگیریم؟ جلسه قبل محاسبات ریاضی و اینکه چطور گرادیان تابع هزینه رو محاسبه کنیم دیدیم. به صورت کلی در مرحله اول یک سری عدد رندوم کوچیک به بردارهای U و V اختصاص میدیم و بعد به کمک الگوریتم گرادیان کاهشی در خلاف جهت گرادیان گام برمیداریم، تا در نهایت به نقطه کمینه تابع هزینه برسیم. مقادیری که در این نقطه برای U و V به دست میان، همون چیزی هست که دنبالش هستیم.

مراحلی که گفتیم تو اسلاید زیر آورده شده. اما این نسخه از الگوریتم گرادیان کاهشی خیلی بیسیک و اولیهست و عملاً هیچکسی از این روش در واقعیت استفاده نمیکنه. چون خیلی طول میکشه تا محاسبات انجام بشه و اصلاً بهینه نیست.

در عوض، از الگوریتم تغییریافته گرادیان کاهشی استفاده میشه که در اسلاید زیر بهش اشاره شده. ایده الگوریتم اینکه به جای اینکه بیایم کل پیکره و کلمات رو در نظر بگیریم، یک سمپلی از کلمات برداریم هر دفعه و محاسبات رو به جای کل کلمات فقط با اون تعداد محدود کلمه پیش ببریم تا سرعت محاسباتمون افزایش پیدا کنه. اگر دوست دارید که جزییات بیشتری در مورد الگوریتم گرادیان کاهشی بدونید و با انواع مختلفش به صورت دقیقتر آشنا بشید، پیشنهاد میکنم نگاهی به این پست بندازید.

از جلسه پیش تا الان چندین بار تکرار کردیم که الگوریتم word2vec قراره دو تا احتمال حساب کنه و به دنبال مقدار ماکسیمم این احتمال باشه:
احتمال اول: اگر کلمه center یا target رو داشته باشیم کدوم کلمات بعنوان context و کلمات همسایه محتملتر خواهند بود؟ (ایده کلی الگوریتم Skip-Gram)
احتمال دوم: اگر کلمات context یا کناری رو داشته باشیم کدوم کلمه با احتمال بیشتری میتونه target باشه؟ (ایده کلی الگوریتم CBOW)
از جلسه پیش تا الان هرچی توضیح دادیم همهش در مورد الگوریتم Skip-Gram بوده. منتها خودِ همین الگوریتم هم دو تا ورژن داره! ورژن اول دقیقاً همون چیزیه که تا اینجا دیدیم، یعنی اومدیم از تابع softmax برای محاسبه تابع هزینه استفاده کردیم. اما این روش در عین سادگی مشکلی که داره اینکه انجام محاسباتش برامون پر هزینهست. برای حل این مشکل اومدن تکنیکی رو معرفی کردن به اسم Negative Sampling که در ادامه میبینیم چطور کار میکنه. صرفاً چون با این روش، تابع هزینه محاسباتش سادهتر انجام میشه بهش اسم جدید دادن با عنوان SGNS (یعنی الگوریتم Skip-Gram با تکنیک Negative Sampling). مقاله اصلی word2vec رو هم ببینید همینجوری بهش اشاره شده.

چرا تابع softmax محاسباتش زیاده؟ از اونجایی که تو اسلاید زیر هم مشخصه، تو مخرج کسر داریم بین تمام کلماتی که داریم ضرب داخلی (شباهت) حساب میکنیم و در نهایت همه رو با هم جمع میزنیم. یعنی اگه 100 هزارتا کلمه داشته باشیم از نظر محاسباتی میشه 100 هزارتا ضرب داخلی! خب این خیلی زیاده.
برای حل این مشکل، الگوریتم Negative Sampling میگه بیا کاری که من میگم رو بکن! به جای اینکه بیای تمام کلمات رو در نظر بگیری، دو گروه از کلمات رو صرفاً در نظر بگیر. گروه اول میشه جفتهای واقعی یا مثبت (هر جفت از کلمه center با کلمات context تو این گروهه، مثلاً کلمه center با یک کلمه کناریش یا کلمه center با دو تا کلمه کناریش، بسته به window ای که در نظر گرفتیم) و گروه دوم میشه جفتهای تصادفی یا منفی یا نویز (هر جفت از کلمه center با کلمات غیر context تو این گروهه).
در نهایت، روی این دو گروه کلمه یک مدل رگرسیون لاجیستیک ساده آموزش بده تا مدل یاد بگیره به گروهِ جفتهای مثبت یا واقعی احتمال بالاتر و به گروه جفتهای منفی یا تصادفی یا نویز احتمال پایینتر تخصیص بده.

از اونجایی که این کورس ماشین لرنینگ نیست و انتظار میره که از قبل با مدلbinary logistic regression آشنایی داشته باشید، اگر به هر دلیلی نمیدونید این مدل چیه و چطوری کار میکنه میتونید نگاهی به این پست بندازید.
برگردیم به Negative Sampling. با این چیزایی که گفتیم، باید تابع objective رو مجدداً بازنویسی کنیم و به صورت زیر در میاد و حواستون باشه این تابع objective عه با تابع هزینه فرق داره و در نهایت میخوایم مقدارش رو ماکسیمم کنیم.
قسمت اول (قبل از بعلاوه) برای گروه مثبته و گفتیم میخوایم شباهت بین کلمه center و کلمات context رو زیاد کنیم (نزدیک کردن کلمات مرتبط). پس اول میایم شباهت بین کلمات رو به کمک ضرب داخلی حساب میکنیم. بعد جواب رو میدیم به تابع سیگموید. تابع سیگموید میاد نتیجه ضرب داخلی رو میبره بین 0 تا 1. چرا؟ چون در نهایت دنبال احتمالیم و برای همین از سیگموید استفاده میکنیم تا یک نرمال سازی انجام بدیم.
قسمت دوم (بعد از بعلاوه) برای گروه منفیه و میخوایم شباهت بین کلمه center و کلمات غیر center رو کمینه کنیم (دور کردن کلمات غیر مرتبط). پس میایم شباهت بین کلمات رو با ضرب داخلی حساب میکنیم، بعد پشتش یه منفی میذاریم. چرا؟ برای اینکه اگه شباهت بین کلمه center و کلمه نویزی که انتخاب شده زیاد بود، مدل رو جریمه کنیم و بفهمه که باید کلمات غیر مشابه به center رو انتخاب کنه. در نهایت، این مقدار رو میدیم به تابع سیگموید تا برامون ببره تو فضای بین 0 تا 1.

حالا میتونیم به جای تابع objective و ماکسیمم کردنش تابع هزینه داشته باشیم و مقدارش رو مینمم کنیم. پس یه منفی پشت چیزی که تا اینجا تعریف کردیم میذاریم و از این به بعد دنبال مینمم کردنش هستیم.

حالا سوال اینکه چطور کلمات نویز رو سمپل برداری کنیم؟ یکی از روشها اینکه بیایم از توزیع یکنواخت استفاده کنیم. یعنی بیایم فراوانی هر کلمه رو بر فراوانی کل کلمات متن حساب کنیم. اما این توزیع به این صورت یه ایرادی داره. اونم اینکه هرچی یک کلمه بیشتر تکرار شده باشه احتمال انتخابش هم بیشتر میشه. مثلاً کلمهای مثل and یا of احتمال انتخاب شدنش بیشتره، چون تعداد دفعات تکرارش بیشتره و از طرفی کمکی هم به یادگیری مدل نمیکنن. چجوری مشکل رو حل کنیم؟ تصویر زیر رو در نظر بگیرید. فرض کنید برای توزیع یکنواخت توانی مثل آلفا در نظر بگیریم (که مقدارش میتونه بین 0 تا 1 باشه). اگه آلفا برابر با 1 باشه همون توزیع یکنواخت عادی رو داریم. اگر آلفا رو 0.75 در نظر بگیریم مشکلی که بهش اشاره کردیم رو میتونیم تا حد خوبی حل کنیم.
تو تصویر زیر یک مثال هم آوردم که صرفاً شهود بهتری ازش داشته باشید. فرض کنید یه متن داریم با دو تا کلمه. یکی از کلمات 99 بار تکرار شده و یکی دیگه فقط یک بار اومده. اگه با آلفای برابر با 1 مقادیر رو حساب کنیم، احتمال انتخاب کلمه پر تکرار 99 صدمه و احتمال انتخاب اون یکی کلمه فقط 1 صدم. حالا اگه بیایم آلفا رو به جای 1 بکنیم 0.75، باعث میشه که احتمال کلمه پر تکرار به 97 صدم کاهش پیدا کنه و از طرفی دیگه احتمال کلمه پر تکرار به 3 صدم افزایش پیدا کنه.
خلاصه که برای سمپل برداشتن کلمات تو الگوریتم word2vec هم چنین کار مشابهی میکنن و به این طریق میتونن احتمال انتخاب کلماتی که کمتر تکرار شدن رو افزایش بدن و احتمال انتخاب کلمات پر تکرار رو کمتر کنن.
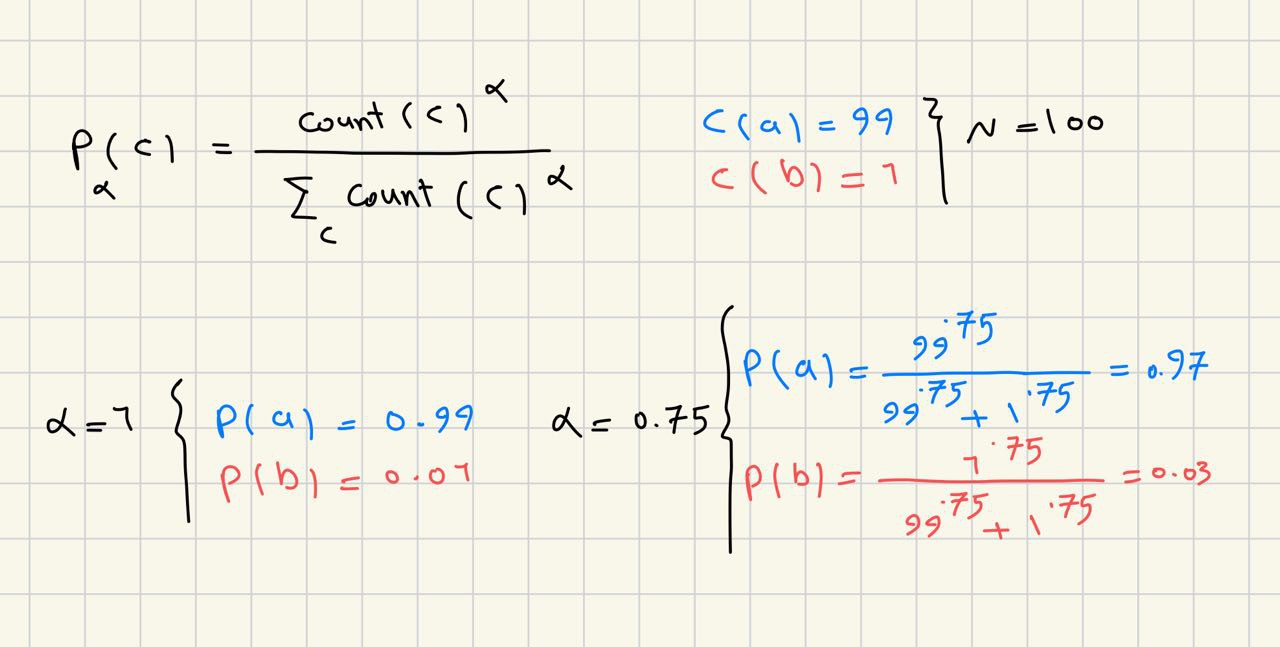
در ادامه قراره ببینیم چه دلایلی باعث شده که اصلاً الگوریتمی مثل word2vec به وجود بیاد و قبل از اون با چه روشهایی کارهای مشابه رو انجام میدادن و روشهای کلاسیک چه ایراداتی داشتن. (به نظرم منطقیتر بود که با روشهای کلاسیک دوره شروع میشد و بعدش میرسید به word2vec ولی خب تصمیم گرفتن که برعکس پیش برن و منم به ترتیب مطالب احترام گذاشتم و جابجا نکردم.)
بریم از شمارش مستقیم کلمات مجاور استفاده کنیم ببینیم چی میشه! برای انجام این کار میتونیم بیایم یک ماتریسی مثل X بسازیم که بهش میگن ماتریس co-occurrence یا هموقوع. برای ساخت این ماتریس هم دو تا روش داریم:
روش اول اینکه به صورت window-based عمل کنیم (یه چیزی شبیه word2vec). یک پنجره مثلاً با طول 1 یا 2 یا 3 یا ... اطراف هر کلمه در نظر بگیریم، هر موقع اون تعداد کلمه رو باهم دیدیم یکی به تعدادش اضافه کنیم. با این روش میتونیم syntactic (شباهت نحوی) و semantic (شباهت معنایی) رو حفظ کنیم.
روش دوم اینکه بیایم ماتریسمونو بر اساس کلمات و document ها بسازیم. این روش بیشتر موضوعات کلی رو در بر میگیره.

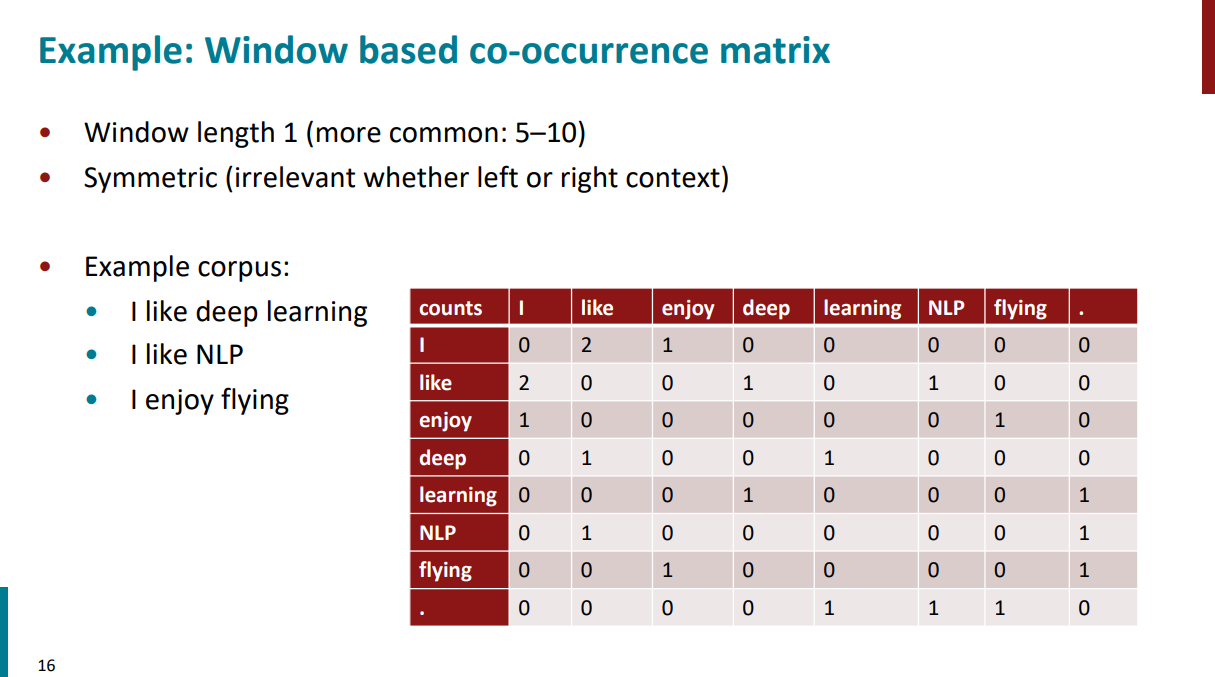
بریم یک مثال از روش اول (window-based) ببینیم. تو مثال زیر طول پنجره 1 در نظر گرفته شده. فرض کنید پیکرهمون شامل 3 تا جملهست:
I like deep learning.
I like NLP.
I enjoy flying.
برای ساخت ماتریس میایم کلمات یونیک پیکره رو در میاریم و تو سطر و ستون میذاریم. بعد باید ماتریس رو با مقادیر مورد نظر پر کنیم:
سطر اول و ستون اول:چند بار تو پیکرهمون کلمه I بعد از I اومده؟ 0 بار.
سطر اول و ستون دوم:چند بار تو پیکرهمون کلمه like بعد از I اومده؟ 2 بار.
سطر اول و ستون سوم:چند بار تو پیکرهمون کلمه enjoy بعد از I اومده؟ 1 بار.
خلاصه به همین ترتیب کل ماتریس رو پر میکنیم.
این روش همونطور که تو مثال هم مشخصه اول اینکه خیلی اسپارسه (مقادیر 0 خیلی زیاد داره) و دوم هم اینکه با بزرگتر شدن پنجره خیلی ابعادش بزرگتر و همینطور اسپارستر میشه.
چطور این ایرادات رو حل کنیم؟ یه روش اینکه بیایم از همون اول سعی کنیم اطلاعات رو تو فضای کوچیکتری ذخیره کنیم (مثل ایدهی word2vec). یه روش دیگه هم اینکه میتونیم بیایم ابعاد ماتریسمون رو با روشهای جبر خطی مثل SVD کمتر کنیم.

در ادامه، قرار نیست وارد جزییات روش SVD بشیم، ولی قراره ایده کلی این روش رو ببینیم که چطور کار میکنه.
فرض کنید یه ماتریس خیلی بزرگ داریم به اسم X. به کمک روش SVD میایم ماتریس X رو میشکنیم به سه تا ماتریس دیگه که دارن در هم ضرب میشن. ماتریس U (برای سطرها) و ماتریس ∑ و ماتریس V (برای ستونها) که وقتی در هم دیگه ضرب میشن به جای ماتریس V، ترانهادهش رو در نظر میگیریم.
ماتریس ∑ یک ماتریس قطریه و ویژگیای که داره اینکه مقادیرش ترتیب دارن. یعنی سطر اول بزرگترین مقدار رو داره، سطر دوم از سطر اول مقدارش کمتره، سطر سوم از سطر دوم مقدارش کمتره و همینطور به ترتیب مقادیرش در هر سطر قرار گرفتن و کمتر از سطر قبلیشون هستن (دایرههای صورتی در اسلاید پایین به همین موضوع اشاره داره).
در نهایت به کمک ماتریس ∑ میفهمیم که اطلاعات مهمِ ماتریس X چطور پراکنده شده و چون ترتیب داره میتونیم تصمیم بگیریم که به جای کل سطرها و ستونها، k سطر و ستون اول و مهم رو برداریم و به این صورت ابعاد ماتریس رو کاهش بدیم در عین حال اطلاعات مهم رو هم حفظ کنیم.

حالا اگه قرار باشه صرفاً کلمات رو بشمریم و یه ماتریس تشکیل بدیم و روی این ماتریس SVD بزنیم خروجی جالبی نخواهیم داشت. برای اینکه یک سری کلمات غیر مهم (مثلاً کلمات ربط) داریم که تعداد تکرارشون بالاست و شمارش خالی کلمات باعث میشه معنای بین کلمات گم بشه.
به همین دلیل بعد از اینکه ماتریس X رو از روی تعداد کلمات ساختیم باید اول یه پیش پردازش روش انجام بدیم، بعد روش SVD بزنیم. چجوری پیش پردازش کنیم؟ مثلاً:
به جای خود فراوانی کلمات از لگاریتم فراوانی کلمات استفاده کنیم.
مقادیر خیلی بزرگ رو محدود کنیم.
کلمات ربط و stopwordها رو حذف کنیم.
به کلمات نزدیک به کلمه مورد نظرمون وزن بیشتری بدیم تا کلمات دورتر.
اگه مقدار منفی داشتیم به صفر تبدیلش کنیم.

خلاصه اگه بعد از این بلاهایی که سر ماتریس X آوردیم، SVD بزنیم یه خروجی شبیه اسلاید زیر خواهیم داشت. کمکم بین بردارهای کلمات، ارتباط معنایی شکل میگیره.
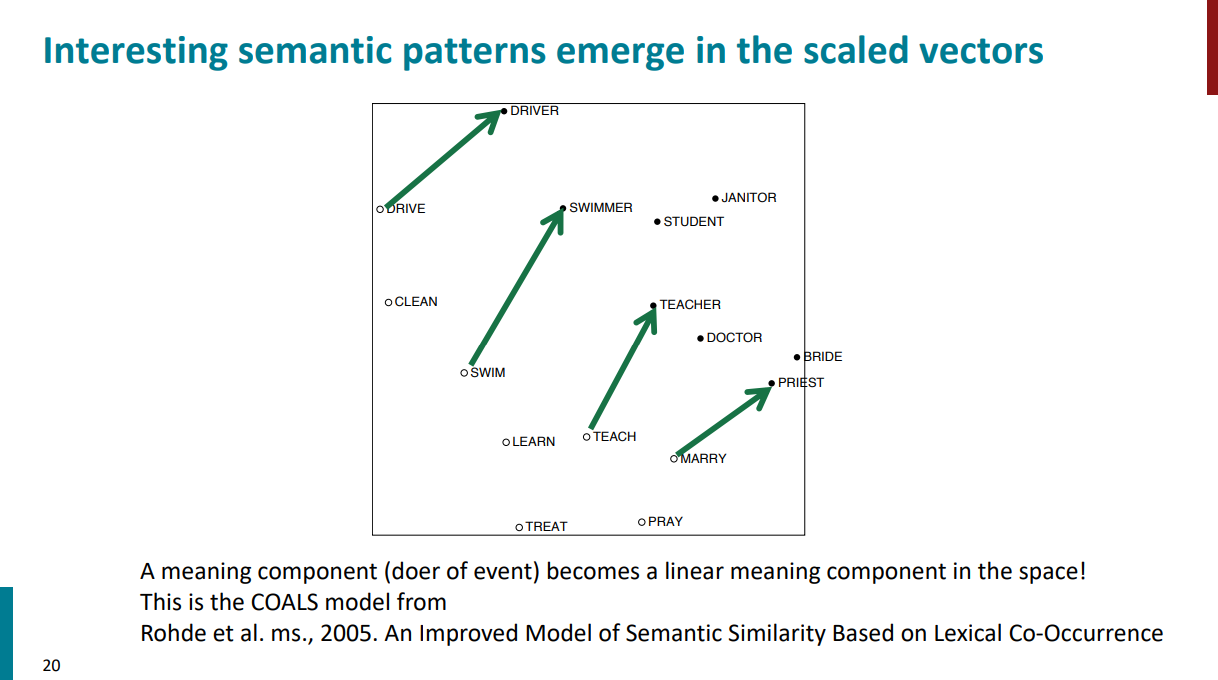
در ادامه قراره با مدل GloVe آشنا بشیم و ببینیم اصلاً چرا چنین مدلی به وجود اومد.
تا اینجا دیدیم که روشهای مبتنی بر شمارش (مشابه همین چیزی که یکم بالاتر دیدیم، اینکه ماتریس co-occurrence تشکیل بدیم و تعداد کلمات رو بشمریم و ...) و روشهای مبتنی بر پیشبینیِ مستقیم (مثل مدل word2vec) برای word embeddingها چطور کار میکنن.
هر کدوم از این روشها یک سری مزایا و معایب دارن. مثلاً روشهای مبتنی بر شمارش چون فقط تعداد کلمات رو میشمرن، فاز training خیلی سریعتری دارن اما فقط برای پیدا کردن شباهت بین کلمات خوبن و دیگه ارتباطات پیچیدهتر رو نمیشه باهاشون تشخیص داد.
از طرفی دیگه در روشهای مبتنی بر پیشبینی مستقیم به جای شمارش کلمات میان از یادگیری مدل برای پیشبینی کلمات استفاده میکنن. به همین دلیل میتونن روابط پیچیدهتر از شباهت بین کلمات رو هم تشخیص بدن اما فاز training براشون میتونه خیلی زمانبرتر باشه.
حالا آیا میتونیم بیایم یه روش جدید بسازیم و نقاط مثبت این دو روش رو ترکیب کنیم و درِش پیاده کنیم؟ بله. میتونیم. بچههای استنفورد سال 2014 این کارو کردن و اسم الگوریتمشون رو هم GloVe گذاشتن.
ایده کلی الگوریتم GloVe به این صورته که میاد از نسبتِ احتمالاتِ co-occurrenceها (بالاتر دیدیم یعنی چی، همین که ترکیباتی که باهم میان رو بشمریم و ...) استفاده میکنه تا ارتباطات معنادار بین کلمات رو تشخیص بده (مثل ارتباط کلمات زن و مرد یا پادشاه و ملکه). جدولی که تو اسلاید پایین اومده رو در نظر بگیرید. از ردیف اول شروع میکنم به توضیح دادن. احتمال اینکه کلمه solid با کلمه ice ارتباط داشته باشه زیاده، در حالیکه احتمال ارتباط کلمه gas با ice کمه. به صورت مشابه، احتمال ارتباط کلمه water با ice بالاست، اما احتمال ارتباط کلمه random با ice کمه (منطقی هم هست، ارتباط یخ با آب و حالت جامد بیشتره تا حالت گاز). ردیف دوم هم به همین صورت مشابه داره تکرار میشه اما به جای ice کلمه steam رو در نظر گرفتیم. تو ردیف سوم هم اومدیم از نسبت احتمالاتی که حساب کردیم استفاده کردیم. هرچی کلمه مد نظر با ice (که تو صورت کسره) ارتباط بیشتری داشته باشه، نسبت احتمالاتی بزرگتره و هرچی با steam (که تو مخرج کسره) ارتباط بیشتری داشته باشه، نسبت احتمالاتی کوچیکتره.

برای اینکه نشون بدن ادعایی که تو اسلاید قبلی کردن به واقعیت نزدیکه، اومدن یک پیکره بزرگ رو در نظر گرفتن، تعداد کلمات رو طبق جدول زیر توش شمردن (مثلاً برای سطر و ستون اول اومدن تعداد ترکیبهایی که ice و solid کنار هم اومدن رو شمردن بدون اهمیت ترتیب) و واقعاً نتیجه نهایی با چیزی که انتظار میرفته، (از نظر بزرگ یا کوچیک بودن عدد یا نزدیک بودن عدد به یک) یکسان بوده.

حالا سوال اینکه چجوری با این روش میتونیم معنای بین کلمات رو به صورت خطی مدل کنیم؟ مثلاً بیایم از کلمه king کلمه man رو حذف کنیم و نتیجه معادل بشه با کلمه queen. نیازه که یک سری رابطه که تو اسلاید زیر اومده رو تعریف کنیم. مثلاً اگر از احتمالی که محاسبه میکنیم log بگیریم مثل این میمونه که انگار اومدیم بین دو تا بردار کلمه ضرب داخلی حساب کردیم. یا اگر از نسبت احتمالات لگاریتم بگیریم مثل این میمونه که اول دو تا بردار کلمه رو از هم کم کنیم و بعد ضرب داخلیشو با بردار کلمه سوم محاسبه کنیم (یا اینجوری هم میشه بهش نگاه کرد، مثلاً یک ویژگی معنایی مشترک رو بین دو کلمه جدا کنیم بعد ببینیم چقدر تو کلمه سوم وجود داره). به کمک این نگاشتها میتونیم یه جورایی فضای آماری و شمارش کلمات رو به فضای برداری مپ کنیم.
یه نگاهی هم به تابع هزینه بندازیم و ببینیم چطور تعریف شده.
اول اینکه یه تابع f داره که روی تعداد هموقوع کلمات (co-occurrenceها) اعمال میشه و در واقع تعیین میکنه هر جفت کلمه چه وزنی توی یادگیری داشته باشه. ایدهش اینه که کلمات خیلی نادر (که معمولاً نویز دارن) یا خیلی پرتکرار (مثل stopwordها) زیاد روی مدل اثر نذارن. در عوض، مدل بیشتر روی هموقوعهای میانه تمرکز کنه، چون معمولاً اطلاعات معنایی بیشتری دارن و برای ساختن embeddingها مهمترن.
خود تابع هزینه هم کل کاری که داره میکنه اینه که اختلاف بین دو تا چیز رو کم میکنه:
اولی پیشبینی مدله. یعنی ضرب داخلی دو تا embedding (دو تا بایاس هم داریم که میتونیم برای سادگی نادیده بگیریم). در واقع همون برداریه که مدل یاد میگیره در نهایت برای هر کلمه بسازه.
دومی هم اطلاعاتیه که از دادهها میگیریم، یعنی log تعداد هموقوع واقعی دو تا کلمه توی متن.
حالا تابع هزینه میاد این دوتا رو با هم مقایسه میکنه. هرچی پیشبینی مدل (یعنی همون ضرب داخلی embeddingها) بیشتر شبیه به log هموقوع واقعی کلمات بشه، خطا کمتر میشه. به عبارتی دیگه، مدل داره یاد میگیره که رابطهی آماری بین کلمات رو طوری توی فضای برداری ذخیره کنه که بشه با یه ضرب داخلی دوباره بهش رسید.

مدل GloVe نتایج قابل قبولی هم داشته. برای مثال بهش گفتن کلمات نزدیک به غورباقه رو بهمون بده و خروجیای که داده اکثراً به خانواده غورباقهها و وزغها ارتباط داشته!

معمولاً این ارزیابی توی تسکهای NLP به دو صورت درونی و بیرونی انجام میشه. روش درونی معمولاً سر راستتر، سریعتر و کمهزینه تره، به این صورت که میشه یک سری معیار تعریف کرد و همونهارو اندازه گیری کرد و فهمید آیا مدلمون خوبه یا نه، مثل perplexity. در حالیکه روش بیرونی پیادهسازیش پیچیدهتر و زمانبرتره و با دنیای واقعی سر و کار داریم. مثلاً بیایم از کاربر ورودی واقعی بگیریم و ببینیم آیا خروجی مدلمون قابل قبوله یا نه. در ادامه با جزییات بیشتری از هر دو روش آشنا میشیم.

یکی از روشهای درونی برای ارزیابی مدل اینکه بیایم یک سری analogy یا رابطه بین کلمات تعریف کنیم و ببینیم مدلمون چطور پیشبینی میکنه. مثلاً به مدل بگیم نسبت مرد به زن مثل نسبت پادشاه هست به کدوم کلمه؟ و ببینیم خروجی مدل چه کلمهای خواهد بود و به این طریق بسنجیم که آیا مدل خوبی داریم یا نه.

تو اسلاید زیر بخش کوچیکی از خروجی مدل GloVe به تصویر کشیده شده و میشه به وضوح دید که چطور میشه به صورت خطی (با جمع و تفریق بین word embeddingها) از یک کلمه به کلمه دیگه رسید. مثلاً از کلمه خواهر به برادر رسید یا از کلمه زن به مرد و همینطور برعکس. همینطور میشه analogyهای دیگه هم تعریف کرد. مثلاً چطور از کلمه slow اول به slower و بعد به slowest رسید.

یک روش درونی دیگه اینکه بیایم ببینیم شباهت بین کلمات از نظر مدل چقدر به شباهت کلمات از نظر آدمهای واقعی شبیه هست. برای مثال، دیتاست WordSim353 دیتاستی هست که میزان شباهت بین جفت کلمات مختلف رو از نظر آدما گرد آوری کرده. میشه میزان این شباهت رو با شباهتی که مدل برای جفت کلمات تعیین میکنه مقایسه کرد و دید چقدر به نظر آدمها نزدیکه.

جدول زیر نشون میده مدلهای مختلف روی دیتاستهایی که میزان شباهت بین جفت کلمات رو از نظر آدمها ثبت کردن، چه عملکردی داشتن. یکی از دلایلی که مدل GloVe نسبت به بقیه مدلها تونسته نتایج بهتری بگیره به دیتاستی برمیگرده که موقع آموزش مدل ازش استفاده کردن.

یکی از روشهای بیرونی برای ارزیابی مدل اینکه ببینیم چقدر مدل میتونهName Entity Recognition انجام بده، به این صورت که بتونه اسم آدمها، سازمانها یا مکانها رو تشخیص بده. تو جدول زیر، مقایسهای از مدلهای مختلف روی همین تسک ارائه شده که میشه دید مدل GloVe نتایج بهتری داشته نسبت به بقیه مدلها.

حالا یک سوال، اگر یک کلمه بیشتر از یک معنی داشته باشه سر word embeddingش چی میاد؟ آیا میشه همه معانیشو صرفاً با یک بردار نشون داد یا باید راه حل دیگهای داشته باشیم؟

یکی از کلمات با چندین معنی مختلف کلمه pike عه. یک لیست از معانی مختلفی که داره تو اسلاید زیر آورده شده.

یکی از راهحلهایی که چندین سال قبل ارائه شد ولی خیلی پرکتیکال نبود این بود که بیان برای هر کلمه به جای یک وکتور، به ازای تعداد معانیای که داره وکتور در نظر بگیرن و بعد مدل رو آموزش بدن به صورتی که بتونه تمامی معانی هر کلمه رو ببینه. مثلاً کلمه bank که با رنگ سبز تو اسلاید زیر مشخص شده دو بار اومده. bank1 به معنی بانک کنار کلماتی مثل مالی و تراکنش آورده شده و bank2 به معنی کنارهی رود و دریا کنار کلماتی مثل مرز و جهت آورده شده.
منتها این روش دو تا ایراد داره. اول اینکه چون به ازای هر کلمه داریم چند تا بردار در نظر میگیریم کار خیلی پیچیدهتر میشه. دو هم اینکه چون داره به صورت دیکشنریوار به هر کلمه و معنیش نگاه میکنه انعطاف نداره. ما دنبال روشی هستیم که اول اینکه پیچیدگی کمتری داشته باشه و دو اینکه بتونه انعطافپذیرتر باشه.

در عوض، اومدن گفتن ما بیایم تعداد بردارها برای هر کلمه رو همون یک در نظر بگیریم (هر کلمه یک بردار معنایی) ولی اگه کلمهای هست که چند تا معنی داره، بیایم میانگین وزندار از معانی مختلف همون کلمه رو براش در نظر بگیریم. ممکنه به نظر برسه که این کار باعث گیج شدن مدل بشه، اما حقیقت اینکه مدل میتونه از روی این میانگینهای وزندار و ترکیب خطی معانی مختلف رو جدا کنه. مثلاً یکی از معانی کلمه pike به یه گونهای از ماهیها اشاره میکنه. مدل وقتی میاد بردار کلمه pike رو (هرچند که میانگین وزنی از چند معنی رو داره) با بردار کلمه fish مقایسه میکنه خودش متوجه شباهت معنایی بین این دو کلمه میشه.

پرونده word2vec رو بستیم و با مدل SVD و GloVe آشنا شدیم و دیدیم که چرا اصلاً نیاز بود تا این الگوریتمها به وجود بیان و روشهای کلاسیک و قدیمی چه ایراداتی داشتن. با روشهای ارزیابی مدلهای متنی آشنا شدیم و دیدیم که چطور اومدن چالش چند معنی بودن کلمات رو حل کردن.
اگر جایی ایراد یا مشکلی بود، حتماً بهم بگید تا تصحیح کنم. اگر هم پست رو دوست داشتید و محتواش به دردتون خورد، میتونید یه قهوه مهمونم کنید!