

مهندس نرم افزار در دیتاک
چطور دیتاک محتوای کپی را تشخیص میدهد؟

این روزها کلی از محتواهای شبکههای اجتماعی از جاهای دیگه برداشته میشن. بعضیها فقط ایده رو میگیرن و بازنویسی میکنن، بعضیها هم تقریباً همون متن رو با یه سری تغییر ریز—مثل عوضکردن تیتر، جابهجا کردن چند جمله یا دستکاری هشتگها—منتشر میکنن. ظاهرش فرق میکنه، ولی عملاً همون محتواست.
مشکل چیه؟
کاربر هی یه چیز رو چندبار میبینه و گیج میشه. از اونطرف، برای کسی که میخواد فضای شبکهها رو تحلیل کنه، مهمه بدونه یه پیام واقعاً چقدر و کجاها پخش شده.
تو سوشال لیسنینگ همین تشخیص نسخههای شبیهبههم یه دردسر جدیه. باید بفهمیم پشت این تغییرهای کوچیک، آیا اصل متن یکیه یا نه. تیم فنی دیتاک یه روش دقیق برای تشخیص این شباهتها ساخته تا هم کاربر پایش تکراریها رو نخونه، هم کاربر تحلیل دید کاملتری از انتشار محتوا داشته باشه.
تو ادامه مقاله، سمت فنی موضوع رو باز میکنیم و میگیم این کار چطور انجام میشه.
۱) تعریف مسئله و چالش مقیاس
اجازه بدید قبل از ورود به بخش فنی چند نکته را مرور کنیم. تشخیص محتوای کپی (near-duplicate) روشهای مختلفی دارد؛ از مدلهای سنگین که معنای متن را هم تحلیل میکنند تا روشهای سبکتر که فقط شباهت ظاهری را میسنجند. در این مقاله روی دسته دوم تمرکز میکنیم، بنابراین اگر دو محتوا از نظر معنا شبیه باشند اما ظاهر متفاوتی داشته باشند، این روش آنها را یکسان تشخیص نمیدهد.
چالش بعدی مقیاس است. دیتاک روزانه ۵ تا ۱۰ میلیون محتوا جمعآوری میکند و مقایسه خطی میان این حجم سند عملاً غیرقابلاستفاده است. بهجای الگوریتمی با پیچیدگی O(n)، باید سراغ راهی برویم که هزینه را به سمت O(C) ببرد.
پرانتز باز
در تئوری O(C) را همان O(1) حساب میکنیم، اما در عمل همیشه اینطور نیست. ثابتبودن نسبت به n کافی نیست؛ خودِ مقدار C تعیین میکند الگوریتم قابلاستفاده هست یا نه. گاهی حتی یک O(C) هم ناکارآمد است و باید راهحل کمهزینهتری پیدا کرد.
پرانتز بسته
۲) راهحل دیتاک: Locality-Sensitive Hashing (LSH)
اینجاست که Locality-Sensitive Hashing (LSH) وارد بازی میشود. LSH راهی هوشمند و سریع برای پیدا کردن نزدیکترین همسایههاست، بدون اینکه لازم باشد همه اسناد را خطبهخط بررسی کنیم. این روش با فرستادن محتواهای شبیه به هم داخل باکتهای هش مشترک، زمان جستوجو را بهشدت کم میکند و در عین حال دقت مناسبی هم حفظ میشود.
روش LSH عملاً برای حل مسئلهی Approximate Nearest Neighbor ساخته شده؛ مسئلهای که در فضاهای با ابعاد زیاد همیشه دردسرساز بوده. هرچقدر تعداد ویژگیها یا ابعاد داده بالا میرود، پیدا کردن نزدیکترین همسایهها بهصورت دقیق بسیار کند و پرهزینه میشود. روشهای معمول باید همه آیتمها را بررسی کنند و همین باعث میشود با افزایش n، زمان بهشدت بالا برود.
روش LSH راهی متفاوت میرود: بهجای مقایسه تکبهتک، از مجموعهای از توابع هش استفاده میکند که عمداً برای حفظ شباهت طراحی شدهاند. یعنی اگر دو آیتم واقعاً به هم شبیه باشند، احتمال خیلی بالایی دارد که خروجی هش آنها هم یکسان یا نزدیک به هم باشد. این دقیقاً همان چیزی است که LSH را از هشهای رمزنگاری مثل SHA-256 یا MD5 جدا میکند؛ هشهای رمزنگاری هدفشان پخشکردن کامل اطلاعات و ایجاد خروجی کاملاً غیرقابلپیشبینی است، درحالیکه LSH میخواهد شباهت را باقی نگه دارد.
توی این مقاله میتونید جزئیات LSH و الگوریتم های Hashing رو بخونید
نتیجه چیست؟
بهجای اینکه بین میلیونها سند بگردیم، کافی است فقط آیتمهایی را بررسی کنیم که در همان باکتهای هش قرار گرفتهاند. این یعنی حجم جستوجو از حالت خطی خارج میشود و به محدودهای نزدیک به زیرخطی یا sub-linear میرسد؛ دقیقاً همان چیزی که برای مقیاس دیتاک لازم داریم.

۳) ساختار ذخیرهسازی و جریان داده
برای اینکه LSH درست کار کند، باید جایی داشته باشیم که باکتها، هش هر داکیومنت، و متادیتاهایی مثل شناسه و زمان انتشار را نگه دارد. مناسبترین ابزار برای این کار Redis است؛ هم سرعت بالایی دارد و هم ساختار دادههایش دقیقاً با نیاز ما جور است.
وقتی محتوا بهصورت استریم وارد سیستم میشود، با یک الگوریتم Hashing آن را به یک بردار هش تبدیل میکنیم و این هش را داخل ردیس ذخیره میکنیم. اگر در همین مرحله مشخص شود که داکیومنت نسخهی مشابه یا تکراری دارد، آن را بهعنوان کپی علامت میزنیم و نسخهی نهایی را برای نگهداری بلندمدت وارد Elasticsearch میکنیم.
مدت زمانی که هش هر داکیومنت در ردیس میماند، به پلتفرمی بستگی دارد که محتوا در آن منتشر شده. برخی پلتفرمها سرعت انتشار بالایی دارند و محتوای مشابه خیلی زود ظاهر میشود؛ برخی دیگر چرخهی کندتری دارند و باید هشها را مدت بیشتری نگه داشت. این بازه تعیین میکند یک داکیومنت تا چه زمانی در فهرست کاندیداهای تشخیص کپی باقی بماند.
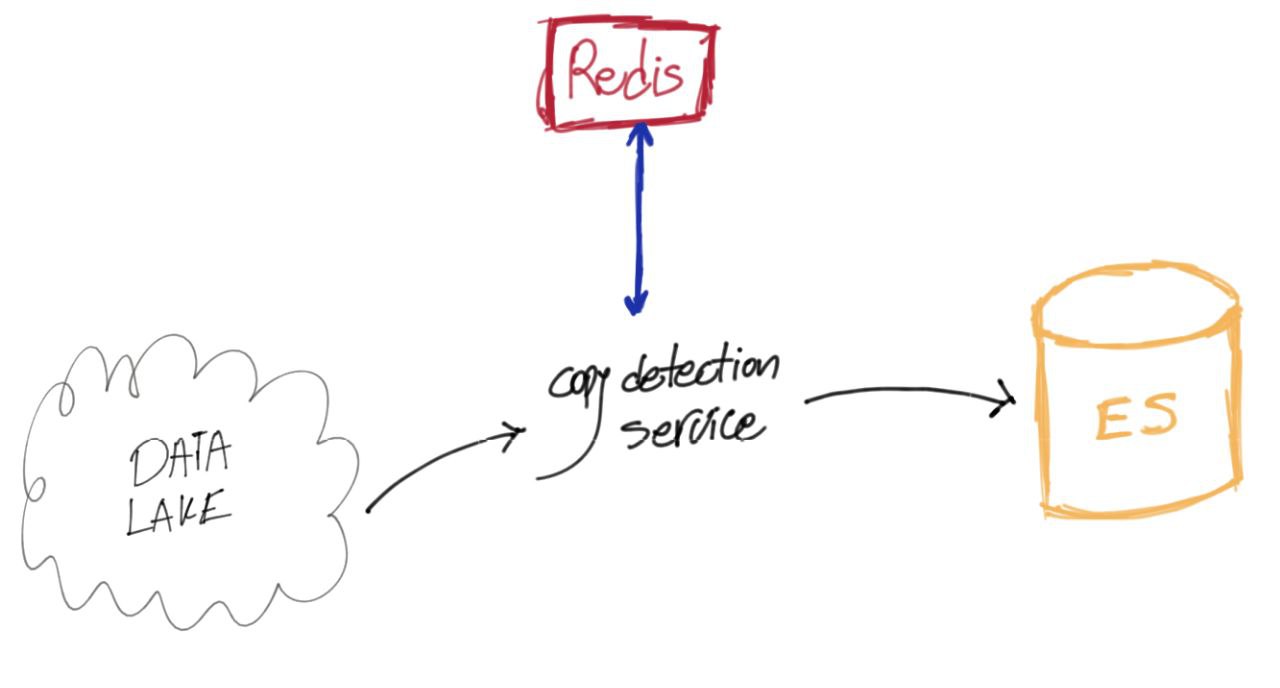
نکته: اینکه چجوری باکتهاتون رو درست میکنید توی فضای ذخیرهسازی و سرعت الگوریتم تأثیر بسزایی داره. ممکنه تو برخی سناریوها نیاز نباشه هش تمام داکیومنتها رو نگه داشت.
جمعبندی
مسئلهی تشخیص محتوای کپی، هم از نظر کیفیت تجربهی کاربر مهم است و هم برای تحلیلگران داده. چالش اصلی مقیاس و نیاز به سرعت بالاست. دیتاک با ترکیب LSH، ساختار ذخیرهسازی مبتنی بر Redis، و مدیریت هوشمندانهی باکتها توانسته این مسئله را در حجم چندمیلیونی روزانه حل کند. با این روش، هم نسخههای تکراری حذف میشوند و هم تصویر دقیقتری از انتشار محتوا شکل میگیرد.
مطلبی دیگر در همین موضوع
وقتى نيستى...
مطلبی دیگر در همین موضوع
جاوااسکریپت: لعنت یا نعمت؟
بر اساس علایق شما
موج اف ام ردیف سکوت