
شاید اسمش یه کم گولزننده باشه و فکر کنید قراره یه چیزی رو "رگرس" کنه، اما در واقع، رگرسیون لجستیک یه قهرمان بلامنازع در دنیای طبقهبندی (Classification) میباشد .
یادتونه تو مدلهای رگرسیون خطی، میخواستیم یه خروجی پیوسته رو پیشبینی کنیم؟
مثلاً قیمت خونه یا نمرات دانشجو و ...
خب، حالا فرض کنید میخوایم یه سوال "بله یا خیر" رو جواب بدیم.
مثلاً: آیا این ایمیل اسپمه؟ یا آیا این بیمار سرطان داره؟ یا آیا این مشتری محصول رو میخره؟
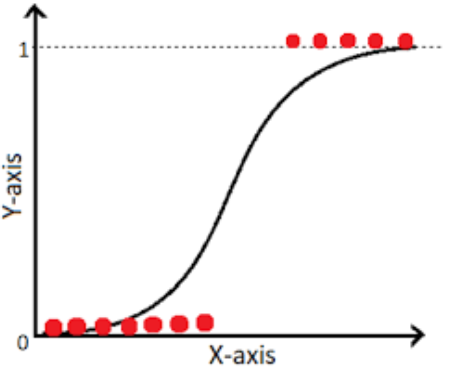
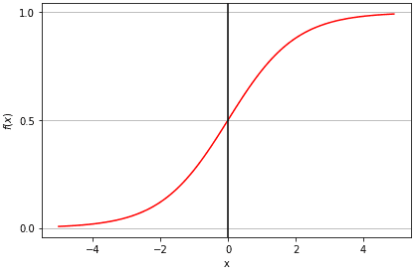
اینجا دیگه رگرسیون خطی کارساز نیست. چرا؟ چون خروجیش میتونه هر عدد حقیقی باشه، در حالی که ما فقط "بله" یا "خیر" (یعنی ۰ یا ۱) رو میخوایم.
اینجاست که رگرسیون لجستیک وارد میشه و با یه ترفند باحال، خروجی پیوسته رو تبدیل میکنه به یه احتمال بین ۰ و ۱.
اگه این احتمال مثلاً بالای ۰.۵ بود، میگیم "بله" وگرنه "خیر". ساده و کاربردی!
اگر اهل مقاله زبان اصلی هستید , مقاله های زیر رو بشدت پیشنهاد میدم مطالعه کنید ؛
https://www.datacamp.com/tutorial/understanding-logistic-regression-python

همانطور که در پست کلاس بندی گفتم ما میتونیم از Logistic Regression هم برای Binary Class و هم برای Multi Class استفاده کنیم :
Binary Logistic Regression : نهایتا ۲ دسته
Multinomial Logistic Regression : بالای ۲ دسته
Ordinal Logistic Regression: دسته ها دارای ترتیب هستند مثل سطح تحصیلات
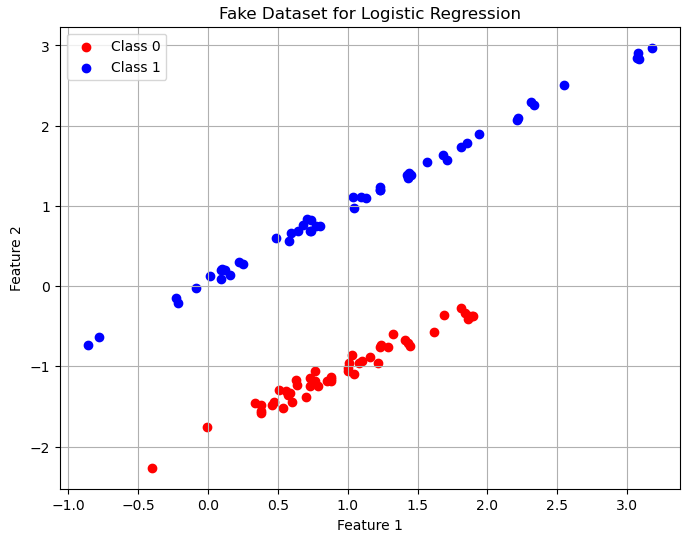
ابتدا این کد رو بزنید تا شما هم دیتاست من رو داشته باشید :
import numpy as np from sklearn.datasets import make_classification np.random.seed(42) X, y = make_classification(n_samples=100, n_features=2, n_classes=2, n_clusters_per_class=1, n_informative=2, n_redundant=0, random_state=42) plt.figure(figsize=(8, 6)) plt.scatter(X[y == 0, 0], X[y == 0, 1], color='red', label='Class 0') plt.scatter(X[y == 1, 0], X[y == 1, 1], color='blue', label='Class 1') plt.xlabel('Feature 1') plt.ylabel('Feature 2') plt.legend() plt.grid(True)
حالا پیاده سازی مدل و تست:
model = LogisticRegression(random_state=42) model.fit(X_train, y_train) y_pred = model.predict(X_test) accuracy = accuracy_score(y_test, y_pred) print(f"Accuracy: {accuracy:.2f}") cm = confusion_matrix(y_test, y_pred) plt.figure(figsize=(6, 4)) sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', cbar=False) plt.title('Confusion Matrix') plt.xlabel('Predicted') plt.ylabel('Actual') plt.savefig('confusion_matrix.png') print("\nClassification Report:") print(classification_report(y_test, y_pred))
نتیجه زیاد مطلوب نیست :

اگر روش تحلیل رو نمیدونید این پست رو ببینید .
ما برای بهبود این نتیجه ها باید بیایم هایپر پارامتر ها رو تنظیم کنیم .
همانطور که الان میبینید در قسمتی که کلاس Logistic Regression رو فراخوانی کردیم آرگومان های خاصی بهش ندادیم . ولی ما میتونیم با تنظیم هایپرپارامتر ها بهترین نتیجه رو از مدل بگیریم .
برای اینکه بیشتر با مدل آشنا شوید این کد رو بزنید :

https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
penalty (جریمه):
توضیح: مشخص میکند که از چه نوع منظمسازی برای جلوگیری از بیشبرازش استفاده شود. منظمسازی وزنهای مدل را محدود میکند.
اگر با Lasso و Ridge در رگرسیون آشنایی ندارید انتهای این مطلب را مشاهده کنید .
مقادیر ممکن:'l1': منظمسازی L1 (Lasso)، که میتواند برخی وزنها را دقیقاً صفر کند.
'l2': منظمسازی L2 (Ridge)، که وزنها را کوچک میکند اما صفر نمیکند.
'elasticnet': ترکیبی از L1 و L2.
'none': بدون منظمسازی.
تأثیر: نوع جریمه روی پیچیدگی مدل و انتخاب ویژگیها تأثیر میگذارد. مثلاً L1 برای دیتاستهایی با ویژگیهای زیاد و غیرمرتبط مناسب است.
پیشفرض: 'l2'
max_iter (حداکثر تعداد تکرارها):
توضیح: حداکثر تعداد تکرارهایی که الگوریتم بهینهسازی برای همگرایی انجام میدهد.
مقادیر ممکن: یک عدد صحیح (مثلاً 100، 1000).
تأثیر: اگر خیلی کوچک باشد، مدل ممکن است قبل از همگرایی متوقف شود. برای دیتاستهای پیچیدهتر، عدد بزرگتری نیاز است.
پیشفرض: 100
tol (تحمل همگرایی):
توضیح: معیاری برای توقف زودهنگام الگوریتم بهینهسازی وقتی تغییرات در تابع هزینه کم شود.
مقادیر ممکن: یک عدد مثبت کوچک (مثلاً 1e-4، 1e-3).
تأثیر: مقادیر کوچکتر باعث میشوند الگوریتم دقیقتر عمل کند اما زمان بیشتری ببرد.
پیشفرض: 1e-4
class_weight (وزن کلاسها):
توضیح: برای مدیریت دیتاستهای نامتوازن، وزنهای متفاوتی به کلاسها اختصاص میدهد.
مقادیر ممکن:None: همه کلاسها وزن یکسان دارند.
'balanced': وزنها به صورت خودکار بر اساس تعداد نمونههای هر کلاس تنظیم میشوند.
دیکشنری مثل {0: 1.0, 1: 2.0} برای وزندهی دستی.
تأثیر: در دیتاستهای نامتوازن، این پارامتر به بهبود عملکرد مدل روی کلاس اقلیت کمک میکند.
پیشفرض: None
multi_class (استراتژی چندکلاسه):
توضیح: مشخص میکند چگونه مسائل چندکلاسه مدیریت شوند.
مقادیر ممکن:'ovr': یک مدل باینری برای هر کلاس در برابر بقیه.
'multinomial': یک مدل چندکلاسه با تابع هزینه softmax.
تأثیر: برای مسائل چندکلاسه، این پارامتر نوع مدل را مشخص میکند. در مسائل باینری تأثیر کمتری دارد.
پیشفرض: 'auto'
l1_ratio (نسبت L1 در elasticnet):
توضیح: نسبت ترکیب L1 و L2 در منظمسازی elasticnet (بین 0 و 1).
مقادیر ممکن: یک عدد بین 0 (فقط L2) و 1 (فقط L1).
تأثیر: فقط وقتی penalty='elasticnet' و solver='saga' باشد استفاده میشود. برای تعادل بین انتخاب ویژگی و کاهش وزنها مناسب است.
پیشفرض: None
برای بدست اوردن بهترین هایپر پارامتر ها میتونید از GridSearchCV استفاده کنید :
model = LogisticRegression(random_state=42) param_grid = { 'penalty': ['l1', 'l2'], 'C': [0.1, 1.0, 10.0], 'solver': ['liblinear'], 'max_iter': [100, 200] } grid_search = GridSearchCV(model, param_grid, cv=5, scoring='accuracy') grid_search.fit(X_train, y_train) print("Best Parameters:", grid_search.best_params_) print("Best Accuracy:", grid_search.best_score_) # تست مدل با بهترین پارامترها best_model = grid_search.best_estimator_ y_pred = best_model.predict(X_test) print("Test Accuracy:", grid_search.score(X_test, y_test))
امیدوارم این مقاله رو دوست داشته باشید و خوشحال میشم نظرتون رو بدونم .