
فرض کنید یک مسئلهی پیچیده رو به هزاران شخص رندوم بدیم و بعد جوابهای اونها رو تجمیع کنیم. در بسیاری از مواقع مشاهده خواهیم کرد که این جواب، بهتر از جواب یک شخص خبره هست. به این اتفاق میگن خرد جمع یا Wisdom of Crowd. بهطور مشابه، اگر تخمین گروهی از Predictorها رو جمع کنید (مثلا Classifierها یا Regressorها) اغلب اوقات تخمینهای بهتری رو نسبت به بهترین Predictor بهدست میارید. به یک گروه از Predictorها میگن Ensemble و به همین خاطر به این تکنیک میگن Ensemble Learning و به یک الگوریتم Ensemble Learning میگن Ensemble Method.
یک مثال از Ensemble Method آموزش یک گروه از Decision Tree Classifierها هست؛ بهطوری که هر کدوم از اونها روی قسمتهای رندوم و مختلف یک دیتاست آموزش دیده باشند. برای انجام تخمین، پیشبینی تمام درختها رو دریافت میکنیم و پیشبینی ای که بیشترین رای رو دریافت کنه بهعنوان پیشبینی نهایی انتخاب میشه. به این روش میگن Random Forest یا جنگل تصادفی و علارغم سادگیش، امروزه یکی از قویترین الگوریتمهای ماشین لرنینگ بهحساب میاد.
همونطور که در فصل دوم گفته شد، موقعی از الگوریتمهای Ensemble استفاده میکنیم که به آخر پروژه نزدیک شده باشیم؛ یعنی موقعی که چندتا Predictor خوب ساخته باشیم و حالا میخواهیم اونها رو با هم ترکیب کنیم تا به یک Predictor خوب برسیم. در واقع راهحلهای پیروز در مسابقات ماشین لرنینگ، اغلب شامل چند الگوریتم Ensemble هستند. (مثلا این مسابقهی Netflix)
در این فصل الگوریتمهای Ensemble محبوب شامل Bagging، Boosting و Stacking و همچنین Random Forest رو بررسی خواهیم کرد.
فرض کنید چندتا Classifier آموزش دادید و هر کدوم دقتی حدود 80 درصد دارند. شاید از Logistic Regression، SVM، Random Forest، K-Nearest Neighbor و ... استفاده کرده باشید.
یک راه ساده برای درست کردن یک Classifier بهتر، ترکیب پیشبینی هر Classifier هست بهطوری که هر پیشبینیای که بیشترین رای رو داشت، بهعنوان پیشبینی نهایی انتخاب بشه. این Majority-Vote Classifier (طبقهبندی کنندهای که تخمین رو با رای اکثریت انجام میده) Hard Voting Classifier نام داره.
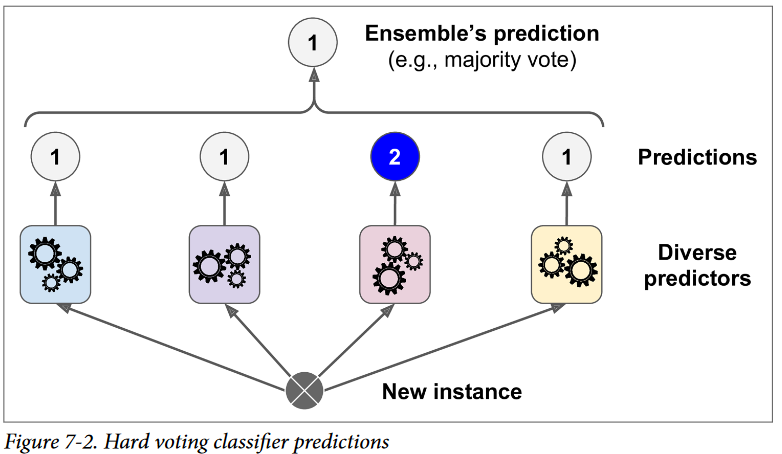
بهطرز تعجبآوری، این Voting Classifier در اکثر اوقات دقت بیشتری نسبت به بهترین Classifier در Ensemble داره. در واقع، اگر همهی Classifierها یک یادگیرندهی ضعیف ( Weak Learner ) باشند (یعنی فقط مقدار کمی بهتر از رندوم حدس زدن عمل میکنن) تجمیع اونها با هم دیگه یک یادگیرندهی قوی ( Strong Learner ) رو تشکیل میده که دقت بالایی داره؛ با فرض اینکه تعداد یادگیرندههای ضعیف کافی باشن و به اندازه کافی هم متفاوت از همدیگه باشن.
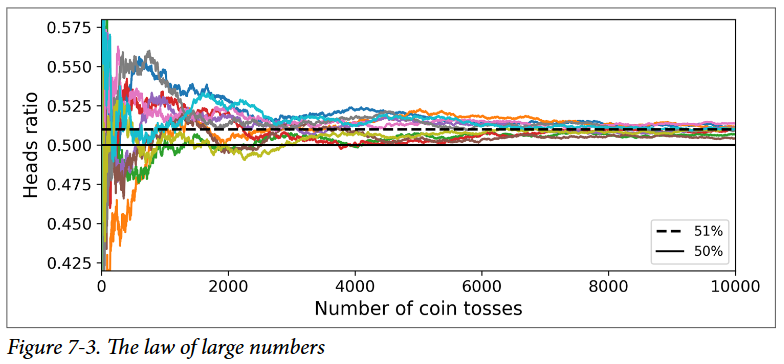
چطور همچین چیزی امکان داره؟ مقایسهی زیر میتونه به روشن شدن این معما کمک بکنه. فرض کنید یک سکهی معیوب دارید که احتمال شیر اومدن 51 درصد و احتمال خط اومدن 49 درصد هست. اگر این سکه رو 1000 بار بندازید، معمولا بیشتر یا کمتر از 510 تا شیر و 490 تا خط میارید. در نتیجه بیشتر شیر میارید. اگر از دید ریاضی به این مسئله نگاه کنیم، میبینید که احتمال رسیدن به تعداد شیرهای بیشتر بعد از 1000 بار تلاش، نزدیک به 75 درصد هست. هرچقدر بیشتر سکه رو پرتاب کنید، احتمال هم بیشتر میشه (برای مثال در ده هزار پرتاب، احتمال نزدیک به 97 درصد هست) دلیل این امر قانون اعداد بزرگ هست (Law of Large Numbers) : همینطور که به پرتاب سکه ادامه میدید، نسبت شیرها نزدیک و نزدیکتر میشه به احتمال شیر اومدن یعنی 51 درصد. شکل زیر پرتابهای 10 سری از سکههای معیوب رو نشون میده. ملاحظه میکنید که هرچقدر تعداد پرتابها افزایش پیدا میکنه، نسبت شیرها هم به 51درصد نزدیک میشه. در نهایت تمام 10 سری اونقدری به 51 درصد نزدیک میشن که همواره بالای 50 درصد هستن.
بهطور مشابه، فرض کنید یک مدل Ensemble ساختید که شامل 1000 Classifer میشه که هر کدوم 51 درصد اوقات درست هستند (در واقع فقط 1 درصد بهتر از رندوم حدس زدن بهتر عمل میکنن) حالا اگر با این مدل یک تخمین انجام بدید، میتونید امید داشته باشید که به دقت 75 درصد میرسید! اگرچه، این فقط مواردی صادق هست که همه Classifierها کاملا مستقل از هم باشند و خطاهای نامرتبط از هم داشته باشن (Uncorrelated Errors) که مشخصا در این مورد ما صدق نمیکنه چون همشون با یک ترینینگ دیتاست مشابه آموزش دیدند. در نتیجه احتمالا همشون یک نوع خطا رو انجام بدن و رای اکثریت برای کلاس اشتباه باشه که باعث بشه دقت مدل پایین بیاد.
مدلهای Ensemble در مواقعی بهترین عملکرد رو دارن که Predictorها تا جایی که امکان داره از هم مستقل باشند. یک راه برای رسیدن به Classifierهای متفاوت از هم، این هست که اونها رو با الگوریتمهای متفاوت آموزش بدیم. این باعث میشه شانس انجام اشتباههای متفاوت بیشتر بشه و دقت مدل افزایش پیدا کنه.
کدی که میبینید یک Voting Classifier رو در Scikit-Learn درست و ترین میکنه که شامل 3 Classifier متفاوت هست(دیتاست برای فصل پنجم هست):
from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import VottingClassifier from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC
log_clf = LogisticRegression() rnd_clf = RandomForestClassifier() svm_clf = SVC()
votting_clf = VottingClassifier(
estimators = [('lr',log_clf), ('rf',rnd_clf), ('svc', svm_clf)], votting = 'hard')
votting_clf.fit(X_train, y_train)
from sklearn.metricsimport accuracy_score for clf in (log_clf, rnd_clf, svm_clf, voting_clf): clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(clf.__class__.__name__, accuracy_score(y_test, y_pred)) # LogisticRegression 0.864 # RandomForestClassifier 0.896 # SVC 0.888 # VotingClassifier 0.904
همونطور که میبینید Voting Classifier تک تک Classifier هارو شکست میده.
اگر تمام Classifierها قابلیت این رو داشتن که احتمال هر کلاس رو بهمون بدن (یعنی تابع predict_proba داشتن) اونوقت میتونستیم به Scikit-Learn بگیم که کلاسی رو که بهطور میانگین احتمال بیشتری رو بین Classifierها داره بهعنوان خروجی برگردونه. به این کار میگن Soft Voting. این کار معمولا عملکرد بهتری نسبت به Hard Voting داره چون وزن بیشتری رو به رایهایی میده که اعتماد بالایی دارن. تنها کاری که باید بکنید این هست که votting = 'hard' رو به votting = 'soft' تغییر بدید و مطمئن بشید که همه Classifierها میتونن احتمال هر کلاس رو بهدست بیارن. این مورد در SVC در حالت دیفالت صادق نیست. به همین دلیل باید هایپرپارامتر probablity=True رو لحاظ کنید. این کار باعث میشه که کلاس SVC برای محاسبه احتمال کلاسها از Cross-Validation استفاده کنه که باعث آرام شدن روند ترین میشه و یک تابع predict_proba هم اضافه میکنه. اگر این تغییر رو در کد بالا انجام بدید میبینید که دقت مدل به 91.2 درصد افزایش پیدا میکنه!
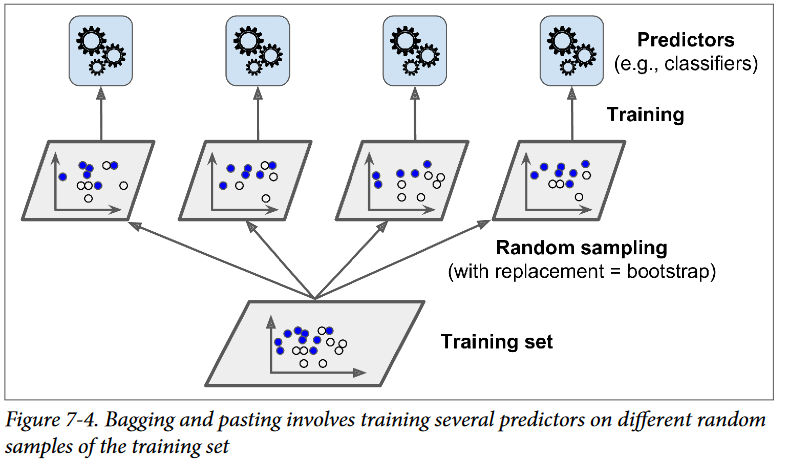
همونطور که گفتیم، یکی از راههای رسیدن به مجموعهای متنوع از Classifierها استفاده از الگوریتمهای متفاوت هست. یک راه دیگه استفاده از یک الگوریتم یکسان برای تمام Predictorها و آموزش اونها روی ترینینگ ستهای مختلف هست.
نمونهگیری (Sampling) با استفاده از جایگذاری، Bagging و بدون استفاده از جایگذاری Pasting نام داره. Bagging مخفف Bootstrap Aggregating هست.
بهعبارت دیگه، هردوی این روشها اجازه میدن تا نمونههای ترینینگ چندین بار در چندین Predictor استفاده بشن اما فقط Bagging اجازه میده که نمونهها چندین بار برای یک Predictor یکسان استفاده بشن. این توضیحهارو میتونید تو شکل زیر ببینید.
وقتی تمام Predictorها آموزش دیدند، این گروه از Predictorها میتونن با تجمیع پیشبینی همهی Predictorها یک پیشبینی برای یک نمونه انجام بدن. تابع تجمیع برای Classification ، مد یا Statistical Mode نام داره (پیشبینیای که بیشترین تکرار رو داره، مثل یک Hard Voting Classifier). برای Regression هم میانگین محاسبه میشه. اگر قرار بود هر کدوم از این Predictorها رو روی ترینینگ ست آموزش بدیم، خطای بیشتری داشتن اما تجمیع اونها باعث میشه تا مقدار خطا و واریانس کم بشه.
همونطور که در تصویر بالا میبینید، Predictorها رو میشه بهصورت موازی، با استفاده از هستههای مختلف CPU یا در سرورهای متفاوت، آموزش داد. بهطور مشابه، عملیات پیشبینی رو هم میشه به صورت موازی انجام داد. این یکی از دلایلی هست که Bagging و Pasting جزء روشهای محبوب به حساب میان: بهخوبی مقیاسپذیر هستند.
کتابخانه Scikit-Learn یک API ساده برای Bagging و Pasting از طریق کلاس BaggingClassifier ارائه میده (برای رگرسیون هم BaggingRegressor) کدی که در زیر میبینید 500 Decision Tree رو آموزش میده. هر کدوم از اونها روی 100 نمونه از نمونههای ترینینگ آموزش میبینه که بهصورت رندوم و با جایگذاری نمونهگیری شدند. (این یک مثال از Bagging هست، برای استفاده از Pasting از هایپرپارامتر bootstrap=False استفاده کنید) هایپرپارامتر n_jobs به Scikit-Learn میگه که از چه تعداد هستهی CPU برای آموزش و پیشبینی استفاده کنه. (قرار دادن 1- باعث میشه از تمام هستهها استفاده کنه)
from sklearn.ensemble import BaggingClassifier from sklearn.tree import DecisionTreeClassifier
bag_clf = BaggingClassifier( DecisionTreeClassifier(), n_estimators=500, max_samples=100, bootstrap=True, n_jobs-1)
bag_clf.fit(X_train, y_train) y_pred = bag_clf.predict(X_test)
اگر Base Classifier (که در اینجا ما DecisionTreeClassifier قرار دادیم) بتونه احتمال هر کلاس رو محاسبه کنه، BaggingClassifier بهصورت خودکار از Soft Voting استفاده میکنه، در غیر این صورت از Hard Voting. منظور از محاسبه احتمال هر کلاس این هست که تابع predict_proba داشته باشه.
شکل زیر مقایسهی بین مرز تصمیم یک Decision Tree رو با 500 درخت در Ensemble نشون میده (همون کد قبلی) همونطور که میبینید عمومیسازی مدل Ensemble بهتر از یک مدل مفرد هست: مدل Ensemble سوگیری (Bias) یکسان اما واریانس کمتری داره (تقریبا همون مقدار خطا رو انجام میده اما مرز تصمیمگیری اون کمتر نامنظم هست)
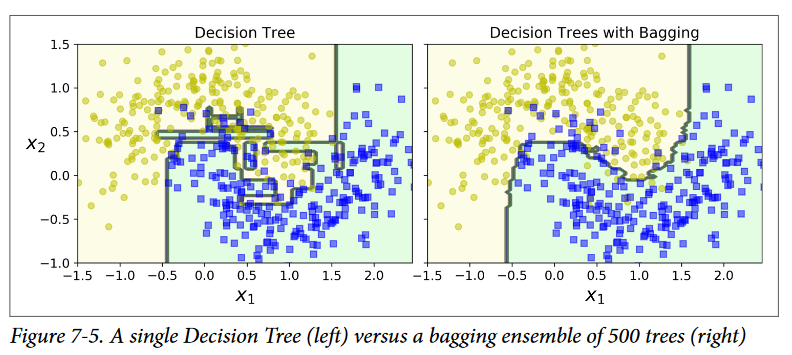
روش Bootstrap به زیرمجموعههایی که هر Predictor با استفاده از اونها آموزش میبینیه، تنوع بیشتری میبخشه؛ در نتیجه Bagging سوگیری بیشتری نسبت به Pasting داره ولی تنوع بیشتر همچنین باعث میشه که Predictorها کمتر با هم همبستگی داشته باشن در نتیجه واریانس این Ensemble کم میشه. بهطور کلی، Bagging مدل بهتری رو ارائه میده و به همین علت معمولاً ترجیح داده میشه. اگرچه، اگر زمان و قدرت CPU زیادی دارید، میتونید از Cross-Validation استفاده کنید تا هردوی Bagging و Pasting رو مقایسه کنید و بهترین مدل رو انتخاب کنید.
در روش Bagging بعضی از نمونهها ممکنه بارها نمونهگیری بشن درحالیکه از بعضیها اصلا استفاده نشه. بهصورت خودکار، یک BaggingClassifier تعداد m نمونه رو با استفاده از جایگذاری آموزش میده (bootstrap=True) که m اندازهی ترینینگ ست هست. این یعنی بهطور میانگین 63 درصد نمونههای ترینینگ روی هر Predictor آموزش داده میشه. (هرچقدر m بیشتر میشه، نسبت نزدیک میشه به exp(-1) - 1 که حدودا برابر 63 درصد هست) باقی 37 درصد نمونهها که نمونهگیری نمیشن، نمونههای Out-of-Bag(OOB) نام دارن. دقت کنید که برای همهی Predictorها لزوما مقدار برابر 37 درصد نیست.
از اونجایی که یک Predictor هیچوقت نمونههای OOB رو حین آموزش نمیبینه، میشه از اونها برای ارزیابی مدل استفاده کرد؛ بدون اینکه یک Validation Set جدا بسازیم. میشه کل Ensemble رو هم با گرفتن میانگین از ارزیابی هر Predictor با OOB ، ارزیابی کرد.
با استفاده از هایپرپارامتر oob_score=True بههنگام ساخت یک BaggingClassifier ، از Scikit-Learn میخوایم که بهصورت خودکار یک OOB Evaluation هم بعد از تموم شدن فرایند آموزش انجام بده. از طریق oob_score_ هم میشه به این امتیاز دست پیدا کرد:
bag_clf = BaggingClassifier( DecisionTreeClassifier(), n_estimators=500, oob_score = True, bootstrap=True, n_jobs-1) bag_clf.fit(X_train, y_train) bag_clf.oob_score_ # 0.90133333333333332
اینطور که این OOB Evaluation میگه، این مدل احتمالاً به دقت 90.1 درصد روی تست ست برسه. ببینیم:
from sklearn.metrics import accuracy_score y_pred = bag_clf.predict(X_test) accuracy_score(y_test, y_pred) # 0.91200000000000003
بعد از اجرای این کد میبینید که دقت مدل روی تست ست برابر 91.2 درصد هست !
از طریق oob_decision_function_ هم میشه به تابع تصمیم OOB برای هر نمونه ترین دست پیدا کرد. در مثال ما چون Base Estimator یک تابع predict_proba داره، تابع تصمیم احتمال هر کلاس رو برای هر نمونه برمیگردونه. برای مثال OOB Evaluation تخمین میزنه که اولین نمونه ترین به احتمال 68.25 درصد متعلق به کلاس مثبت و به احتمال 31.75 درصد متعلق به دسته منفی هست.

کلاس BaggingClassifier از نمونهگیری فیچرها هم پشتیبانی میکنه. این نمونهگیری با استفاده از دو هایپرپارامتر کنترل میشه: max_features و bootstrap_features. طرز کارشون مثل max_samples و bootstrap هست اما بهجای نمونهها، برای فیچرها کاربرد دارن. با این کار، هر Predictor روی زیرمجموعهای از فیچرها آموزش میبینه.
این تکنیک در مواقعی پرکاربرد هست که داریم با ورودیهایی با ابعاد بالا کار میکنیم ( مثل عکسها ) نمونهگیری از هردوی نمونهها و فیچرها Random Patches Method نام داره. نگه داشتن همه نمونههای ترینینگ ( bootstrap=False, max_sample=1.0) و نمونهگیری از فیچرها (bootstrap_features=True and/or max_features < 1.0) Random Subspaces method نام داره.
نمونهگیری فیچرها باعث میشه تنوع Predictorها بیشتر هم بشه و این کار باعث میشه سوگیری بیشتر اما واریانس کمتری داشته باشیم.
همونطور که گفتیم، Random Forest یک گروه از درختهای تصمیم هست که عموماً با استفاده از روش Bagging آموزش دیده (بعضی اوقات هم Pasting) و معمولا هایپرپارامتر max_samples برابر تعداد نمونههای ترینینگ ست هست. بهجای اینکه یک BaggingClassifier بسازیم و DecisionTreeClassifier رو به اون بدیم، میتونیم از کلاس RandomForestClassifier استفاده کنیم که هم راحتتر هست و هم برای درختهای تصمیم بهینه شده. (برای رگرسیون هم RandomForestRegressor وجود داره)
کلاس BaggingClassifier در مواقعی کاربردی هست که بخواید یک گروه از مدلهایی جز درخت تصمیم استفاده کنید
کدی که در زیر میبینید از تمام CPU استفاده میکنه تا یک Random Forest Classifier رو با 500 درخت که هر کدوم به ماکسیموم 16 گره محدود شدن، آموزش بده:
from sklearn.ensemble import RandomForestClassifier rnd_clf = RandomForestClassifier(n_estimators=500, max_leaf_node = 16, n_jobs=-1) rnd_clf.fit(X_train, y_train) y_pred_rf = rnd_clf.predict(X_test)
همونطور که انتظارش رو داشتیم، RandomForestClassifier تمام هایپرپارامترهای یک DecisionTreeClassifier رو داره که بتونیم رشد درخت رو کنترل کنیم و همینطور تمام هایپرپارامترهای BaggingClassifier تا بتونیم خود Ensemble رو کنترل کنیم.
الگوریتم Random Forest بههنگام رشد درختها رندوم عمل میکنه؛ بهجای اینکه بههنگام قطع یک گره، بهدنبال بهترین فیچر باشه (مطلب درخت تصمیم رو ببینید) دنبال بهترین فیچر در میان زیرمجموعهای از فیچرها میگرده. این الگوریتم تنوع درختها رو بالا میبره که باعث میشه سوگیری بیشتر و واریانس کمتری داشته باشیم، که عموما عملکرد مدل رو افزایش میده. BaggingClassifierای که میبینید تقریبا برابر RandomForestClassifier قبلی هست:
bag_clf = BaggingClassifier( DecisionTreeClassifier(splitter="random", max_leaf_nodes=16), n_extimators=500, max_samples=1.0, bootstrap=True, n_jobs=-1)
در Random Forest وقتی یک درخت در حال رشد هست، در هر گره فقط زیرمجموعهای رندوم از فیچرها برای قطع شدن در نظر گرفته میشه. بهجای جستجو برای بهترین آستانهی ممکن، میشه با استفاده از آستانههای رندوم برای هر فیچر، درختهارو رندومتر هم کرد.
جنگلی به این اندازه رندوم، Extremly Randomized Trees نام داره. (یا بهطور خلاصه: Extra-Trees) این تکنیک هم سوگیری زیاد و واریانس کمی داره. این تکنیک همچنین نسبت به Random Forest معمولی، در زمان کمتری آموزش میبینه چون پیدا کردن بهترین مرز برای هر فیچر در هر گره، یکی از زمانبر ترین کارها برای یک درخت در حال رشد هست.
برای ساخت این مدل، از کلاس ExtraTreesClassifier استفاده میکنیم. این کلاس APIای شبیه به کلاس RandomForestClassifier هست. بهطور مشابه ExtraTreesRegressor هم وجود داره که APIای شبیه به کلاس RandomForestRegressor داره.
نمیشه گفت که RandomForestClassifier عملکرد بهتر یا بدتری نسبت به ExtraTreesClassifier داره. عموما تنها راه برای فهمیدن این موضوع، استفاده از هر دو و مقایسهی اونها با استفاده از Cross-Validation هست.
یکی دیگه از خصوصیتهای Random Forest اینه که به راحتی میشه اهمیت نسبی هر فیچر رو اندازهگیری کرد. Scikit-Learn نگاه میکنه که گرههای درختی که از یک ویژگی استفاده میکنه، چقدر بهطور متوسط ناخالصی (Imputiry) رو کاهش میده(در تمام درختهای جنگل) و با این روش اهمیت یک فیچر رو محاسبه میکنه. بهطور دقیقتر، این یک میانگین وزندار هست که وزن هر گره برابر تعداد نمونههای ترینینگ مرتبط با اون هست.
کتابخانه Scikit-Learn این امتیاز رو برای هر فیچر بعد از آموزش بهصورت خودکار محاسبه میکنه و سپس این نتایج رو طوری مقیاسبندی میکنه که مجموع اهمیتها برابر 1 بشه. این نتیجه رو میتونید با استفاده از feature_importances_ ببینید. کدی که میبینید یک RandomForestClassifier رو روی دیتاست Iris آموزش میده و اهمیت هر فیچر رو بهعنوان خروجی میده. اینطور که پیداست پر اهمیت ترین فیچرها Petal Length و Width هست. در حالیکه کمترین فیچرها Sepal Length و Width هست.
from sklearn.datasets import load_iris iris = load_iris() rnd_clf = RandomForestClassifier(n_extimators=500, n_jobs=-1) rnd_clf.fit(iris['data'], iris['target']) for name,score in zip(iris['feature_name'], rnd_clf.feature_importances_): print(name, score) #sepal length (cm) 0.112492250999 #sepal width (cm) 0.0231192882825 #petal length (cm) 0.441030464364 #petal width (cm) 0.423357996355
بهطور مشابه، اگر یک Random Forest روی دیتاست MNIST آموزش بدید و اهمیت هر پیکسل رو با نمودار نشون بدید، با این شکل روبرو میشید:
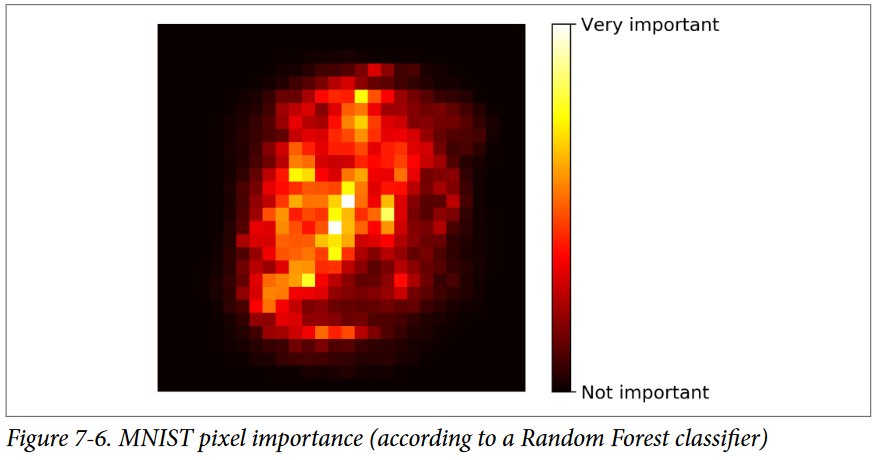
اگر احتیاج دارید که از بین فیچرها انتخاب کنید، Random Forest یک راه سریع برای فهمیدن اهمیت فیچرهاست.
روش Boosting (که در اصل Hypothesis Boosting نام داره) به هر روش Ensembleای گفته میشه که میتونه چند یادگیرندهی ضعیف رو با هم ترکیب کنه تا یک یادگیرندهی قوی بسازه. ایدهی عمومی بیشتر روشهای Boosting اینهکه Predictorها به ترتیب آموزش ببینن که هر کدوم سعی میکنن اشتباهات پیشنیان رو درست کنن. روشهای Boosting زیادی وجود داره اما تا اینجا محبوبترین ها AdaBoost (مخفف Adaptive Boosting) و Gradient Boosting هستن.
یک روش برای یک Predictor برای اصلاح پیشنیان اینه که به نمونههای ترینینگ که پیشنیان آندرفیت میکنن توجه بیشتری بکنه. این باعث میشه که Predictorهای جدید توجه بیشتر و بیشتری روی نمونههای سخت بکنن. این تکنیکی هست که AdaBoost استفاده میکنه.
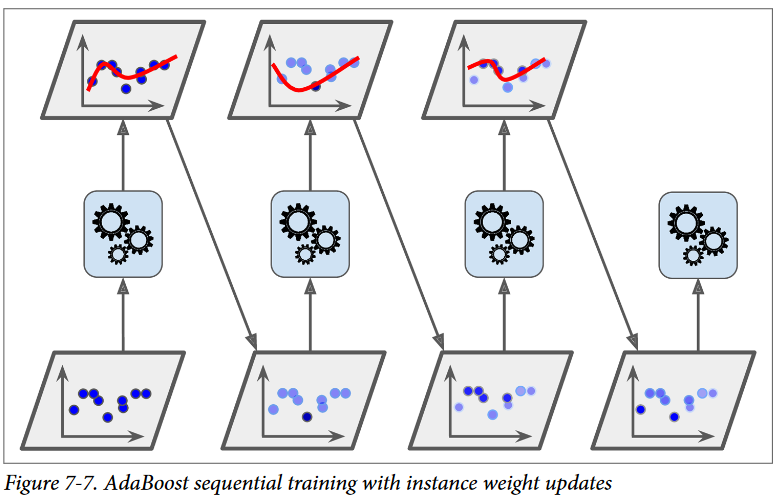
برای مثال وقتی داریم یک AdaBoost Classifier آموزش میدیم، الگوریتم در ابتدا یک Base Classifier آموزش میده (مثلا یک درخت تصمیم) و از اون استفاده میکنه تا پیشبینیهایی روی مجموعهی آموزشی انجام بده. بعد الگوریتم وزن نسبی نمونههای آموزشیای که به اشتباه طبقهبندی شدن، افزایش میده. بعد یک Classifier دوم رو با استفاده از وزنهای بهروزرسانی شده آموزش میده و دوباره روی ترینینگ ست پیشبینی انجام میده، وزن نمونههارو بهروزرسانی میکنه و الی آخر.
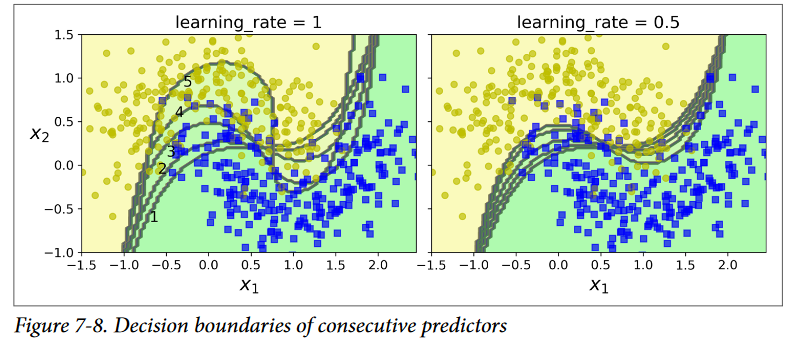
شکلی که مشاهده میکنید مرزهای تصمیم 5 Predictor پشت سر هم رو روی دیتاست Moons نشون میده. (در این مثال، هر Predictor یک SVM Classifier با RBF Kernel هست. البته این فقط برای نمایش هست. معمولا SVM ها Base Predictor خوبی برای AdaBoost بهحساب نمیان چون آهسته هستند و با این الگوریتم ناپایداری نشون میدن) اولین Classifier توی نمونههای زیادی اشتباه میکنه، پس وزن اونها افزایش پیدا میکنه. بخاطر همین دومین Classifier روی این نمونهها نتیجهی بهتری رو نشون میده و الی آخر.
شکل سمت راست همین ترتیب از Predictorها رو نشون میده با این تفاوت که Learning Rate نصف شده (یا به عبارتی دیگه در هر تکرار، وزن نمونههای بهاشتباه طبقهبندی شده یک دوم افزایش پیدا میکنه) همونطور که میبینید این تکنیک ِ یادگیری ِ ترتیبی، یک سری شباهتها به Gradient Descent داره، بهجز اینکه بهجای اینکه پارامترهای یک Predictor رو دستکاری کنیم تا تابع هزینه کاهش پیدا کنه، AdaBoost یک سری Predictorها رو به Ensemble اضافه میکنه تا بهتدریج نتیجه رو بهتر کنه.
وقتی تمام Predictorها آموزش دیدن، Ensemble شبیه به Bagging یا Pasting پیشبینی رو انجام میده،اما با این تفاوت که بسته به دقت کلی Predictorها در ترینینگ ست وزندار، وزنهای متفاوتی خواهند داشت.
این الگوریتم ترتیبی یک اشکال مهم داره:
این الگوریتم رو نمیشه بهصورت موازی یا جزء به جزء استفاده کرد چون هر Predictor بعد از آموزش و ارزیابی ِPredictor قبلی آموزش میبینه. بههمین خاطر مثل Bagging یا Pasting مقیاسپذیر نیست.
بیاید یک نگاه نزدیکتر به الگوریتم AdaBoost بندازیم.در ابتدا، وزن هر نمونه ( (i)^w ) برابر 1-^(m) هست. اولین Predictor آموزش میبینه و نرخ خطای وزن دار اون ( r_1 ) بر روی ترینینگ ست محاسبه میشه:

حالا با استفاده از فرمول زیر وزن Predictor محاسبه میشه که اون رو با آلفای جِی نشون میدیم. علامت اِتا در اینجا هایپرپارامتر Learning Rate هست (دیفالت برابر 1) هرچقدر Predictor دقیقتر باشه، وزنش هم بیشتر میشه. اگر بهصورت رندوم پیشبینیهارو انجام بده، وزن اون نزدیک به صفر میشه. اگر در اکثر مواقع اشتباه کنه (یعنی دقتش حتی از حدس زدن رندوم هم کمتر باشه) مقدارش منفی میشه.

این الگوریتم در قدم بعدی وزن نمونههارو بهروزرسانی میکنه. فرمول زیر وزن نمونههای اشتباهطبقهبندیشده رو بهروزرسانی میکنه:

بعد از اون تمام وزنها نرمال میشن (یعنی تقسیم بر سامیشن همه وزنها میشن)
و در نهایت یک Predictor جدید با استفاده از وزنهای بهروزرسانی شده آموزش میبینه و دوباره این روند تکرار میشه. ( وزن Predictor جدید محاسبه میشه، وزن نمونهها بهروزرسانی میشن و یک Predictor دیگه آموزش میبینه) هروقت به تعداد Predictor دلخواه رسیدیم یا هروقت به یک Predictor عالی رسیدیم، الگوریتم میایسته.
برای پیشبینی، AdaBoost پیشبینیهای همهی Predictorها رو محاسبه میکنه و با استفاده از وزن Predictor یعنی آلفا، به اونها وزن میده. کلاس خروجی کلاسی هست که اکثریت به اون رای میدن:

کتابخانه Scikit-Learn از ورژن چندکلاسی AdaBoost به نام SAMME استفاده میکنه (Stagewise Additive Modeling using a Multiclass Exponential loss function ) وقتی فقط دوتا کلاس داریم SAMME برابر با AdaBoost هست.اگر Predictorها بتونن احتمال هر کلاس رو محاسبه کنن (یعنی تابع predict_proba داشته باشن) Scikit-Learn میتونه از یک نوع SAMME به نام SAMME.R استفاده کنه (R مخفف Real هست) این نوع بهجای تکیه بر پیشبینیها، برپایهی احتمالات هست و عموما بهتر عمل میکنه.
کد زیر یک AdaBoost Classifier رو بر پایهی 200 Decision Stump با استفاده از کلاس AdaBoostClassifier درست میکنه. Decision Stump یک درخت تصمیم هست که هایپرپارامتر max_depth=1 هست. به عبارت دیگه، یک درخت که شامل یک گرهی تصمیم بهاضافهی دو برگ هست. این Base Estimator دیفالت برای این کلاس هست. همونطور که انتظار دارید، یک کلاس AdaBoostRegressor هم وجود داره.
from sklearn.ensemble import AdaBoostClassifier ada_clf = AdaBoostClassifier( DecisionTreeClassifier(max_depth=1), n_estimators=200, algorithm="SAMME.R", learning_rate=0.5 ) ada_clf.fit(X_train, y_train)
اگر AdaBoost اورفیت شده، میتونید تعداد Estimatorها رو کم کنید یا Base Estimator رو Regularize کنید.
یک الگوریتم Boosting دیگه که خیلی پرطرفدار هست، Gradient Boosting نام داره. مثل AdaBoost ، این الگوریتم هم با اضافه کردن پی در پی Predictor ها به یک Ensemble کار میکنه که هر کدوم از اونها پیشنیان خودشون رو اصلاح میکنن. اما بهجای اینکه مثل AdaBoost وزن هر نمونه رو در هر تکرار تنظیم کنه، این روش سعی میکنه Predictor جدید رو به Residual Error که Predictor قبلی درست کرده، فیت کنه.
بذارید یک مثال رگرسیون ساده رو بررسی کنیم که توی اون Base Predictor یک درخت تصمیم هست (بله البته، Gradient Boosting از پس رگرسیون هم برمیاد) به این کار میگن Gradient Tree Boosting یا Gradient Boosted Regression Trees (GBRT). اول یک DecisionTreeRegressor رو با ترینینگ ست فیت میکنیم (برای مثال یک ترینینگ ست درجه دو که نویز داره):
from sklearn.tree import DecisionTreeRegressor tree_reg1 = DecisionTreeRegressor(max_depth=2) tree_reg1.fit(x, y)
بعد یک DecisionTreeRegressor دوم رو با Residual Error مدل قبلی درست میکنیم:
y2 = y - tree_reg1.predict(X) tree_reg2 = DecisionTreeRegressor(max_depth=2) tree_reg2.fit(X, y2)
حالا یک مدل سوم رو با Residual Error مدل قبلی درست میکنیم:
y3 = y2 - tree_reg2.predict(X) tree_reg3 = DecisionTreeRegressor(max_depth=2) tree_reg3.fit(X, y3)
حالا یک Ensemble داریم که شامل 3 درخت هست. این مدل میتونه با جمع کردن پیشبینی 3 مدل، یک پیشبینی انجام بده:
y_pred = sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2, tree_reg3))
شکلی که پایین میبینید، پیشبینی این 3 درخت رو در ستون چپ و پیشبینی Ensemble رو در ستون راست نشون میده. در ردیف اول، Ensemble فقط یک درخته در نتیجه پیشبینی اون دقیقا مثل اولین درخته. در ردیف دوم یک درخت جدید روی Residual Error درخت اول ایجاد شده. در سمت راست میبینید که پیشبینی Ensemble برابر مجموع پیشبینیهای دو درخت قبلی هست. بهطور مشابه، در ردیف سوم یک درخت دیگه روی Residual Error درخت دوم ایجاد شده. ملاحظه میکنید که پیشبینیهای Ensemble بهتدریج با اضافه شدن درختها، بهتر و بهتر میشه.
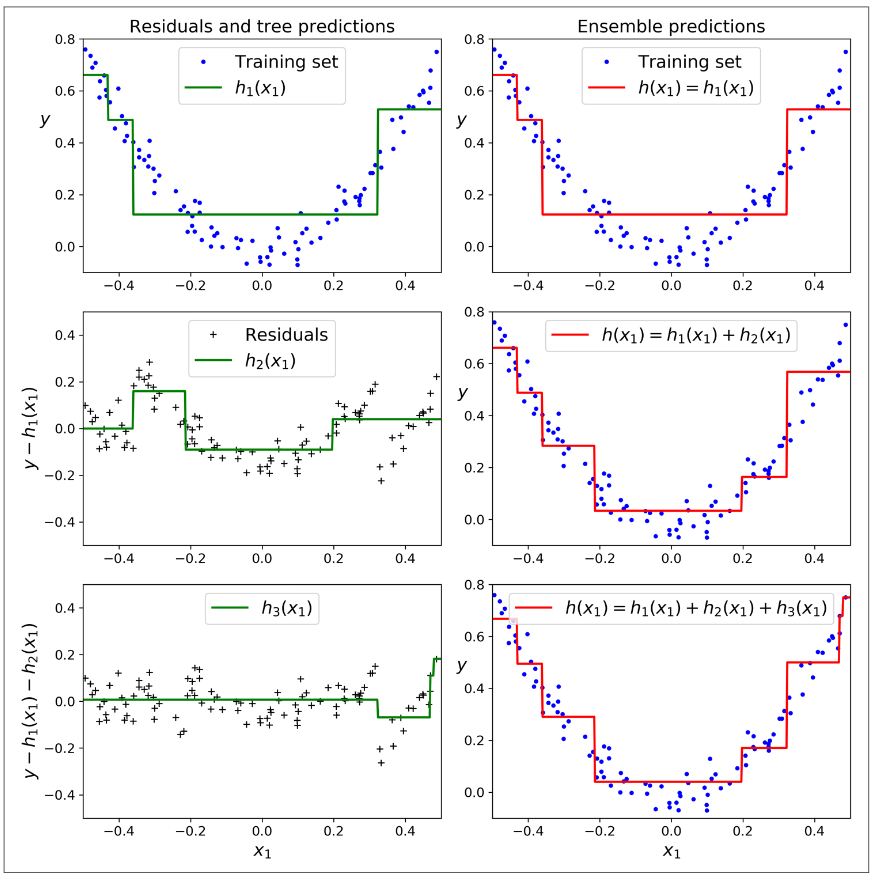
یک راه ساده برای آموزش یک GBRT Ensemble استفاده از کلاس GradientBoostingRegressor هست.مثل کلاس RandomForestRegressor ، این کلاس هم هایپرپارامترهایی برای کنترل رشد درختهای تصمیم داره. (برای مثال، max_depth, min_samples_leaf) همینطور هایپرپارامترهایی برای کنترل آموزش Ensemble مثل تعداد درختها (n_estimators). کدی که میبینید همون Ensemble ای رو تولید میکنه که بالاتر درست کردیم:
from sklearn.ensemble import GradientBoostingRegressor gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=3, learning_rate=1.0) gbrt.fit(X, y)
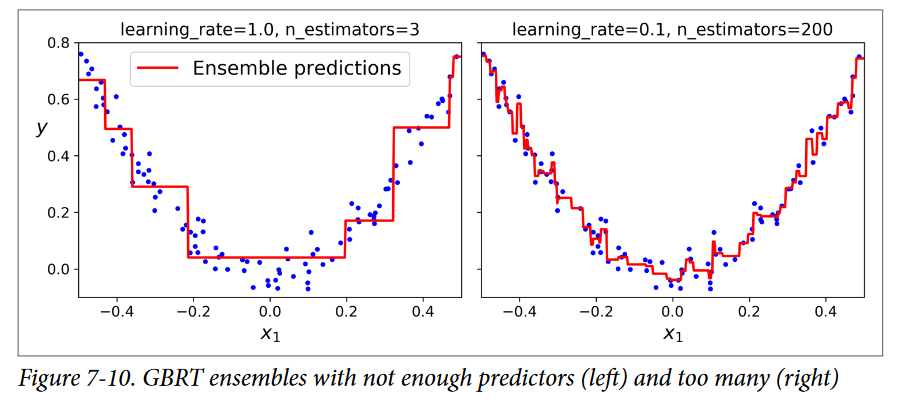
هایپرپارامتر learning_rate میزان مشارکت هر درخت رو مقیاسبندی میکنه. اگر اون رو برابر یک مقدار کم مثل 0.1 قرار بدید، به درختهای بیشتری در Ensemble احتیاج خواهیم داشت تا روی ترینینگ ست فیت بشه اما معمولا در این حالت پیشبینیها بهتر عمومیسازی میشن. این تکنیک Regularization میگن Shrinkage. شکل پایین دو GBRT Ensemble رو نشون میده که Learning Rate توی اونها کم هست. مدل سمت چپ تعداد درختهای کافی نداره تا روی ترینینگ ست فیت بشه در حالیکه مدل سمت راست تعداد درختهای زیادی داره و ترینینگ ست رو اورفیت میکنه.
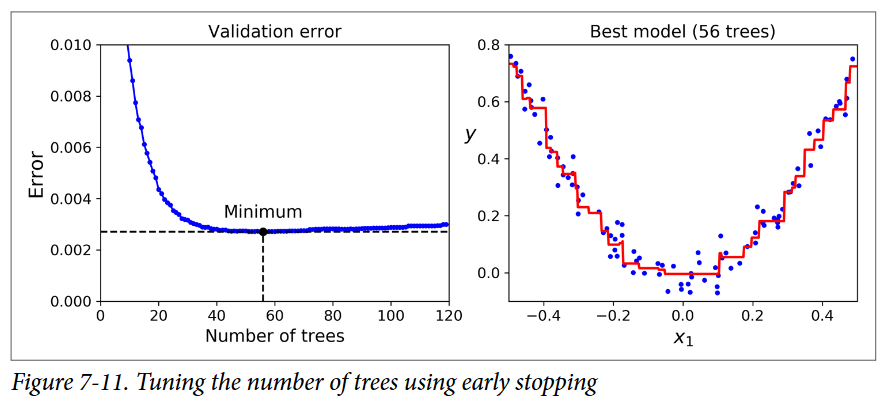
برای پیدا کردن تعداد مناسبی از درختها، میتونیم از Early Stopping استفاده کنیم.(آشنایی با Early Stopping) یک راه ساده برای پیادهسازی این روش، استفاده از تابع staged_predict هست: این تابع یک Iterator روی پیشبینیهایی که Ensemble در هر مرحله از آموزش انجام داده، برمیگردونه.(با یک درخت، دو درخت و الی آخر) کد زیر یک GBRT Ensemble رو با 120 درخت آموزش میده، بعد Validation Error رو در هر مرحله از آموزش محاسبه میکنه تا تعداد بهینهی درختهارو پیدا کنه و در نهایت یک GBRT Ensemble رو با استفاده از تعداد درختهای بهینهای که پیدا کرده، درست میکنه:
import numpy as np from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error X_train, X_val , y_train, y_val = train_test_split(X, y) gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=120) gbrt.fit(X_train, y_train) errors = [mean_squared_error(y_val,y_pred) for y_pred in gbrt.staged_predict(X_val)] best_n_estimators = np.argmin(errors) + 1 gbrt_best = GradientBoostingRegerssor(max_depth=2, n_estimators=best_n_estimators) gbrt_best.fit(X_train, y_train)
میزان خطاها در سمت چپ شکل و پیشبینیهای بهترین مدل در سمت راست قرار دارن:
همچنین میشه برای پیادهسازی Early Stopping بهجای اینکه اول تعداد زیادی از درختهارو آموزش بدیم و سپس بگردیم که بهترین تعداد درخت رو پیدا کنیم، فرآیند آموزش رو زودتر متوقف کنیم. استفاده از هایپرپارامتر warm_start = True باعث میشه Scikit-Learn وقتی تابع fit فراخوانی میشه، درختهای موجود رو نگهداره و امکان آموزش افزایشی یا Incremental Learning رو فراهم کنه. کد زیر هر وقت Validation Error برای 5 پیمایش پشت سر هم بهتر نشه، فرآیند آموزش رو متوقف میکنه:
gbrt = GradientBoostingRegressor(max_depth = 2, warm_start = True) min_val_error = float('inf') error_going_up = 0 for n_estimators in range(1, 120): gbrt.n_estimators = n_estimators gbrt.fit(X_train, y_train) y_pred = gbrt.predict(X_val) val_error = mean_squared_error(y_val, y_pred) if val_error < min_val_error: min_val_error = val_error error_going_up = 0 else: error_going_up += 1 if error_going_up == 5: break # early stopping
کلاس GradientBoostingRegressor همچنین از یک هایپرپارامتر به نام subsample پشتیبانی میکنه که این هایپرپارامتر کسری از نمونههای آموزشی رو مشخص میکنه که برای آموزش هر درخت باید استفاده بشه. برای مثال اگر subsample=0.25 باشه، هر درخت با 25درصد از نمونههای آموزشی آموزش میبینه که اونها هم رندوم انتخاب میشن. همونطور که حدس زدید، این تکنیک سوگیری بالا و واریانس کمی داره. همچنین به طرز قابل توجهی هم فرآیند آموزش رو سریع میکنه. این روش Stochastic Gradient Boosting نام داره.
همچنین این امکان وجود داره که از Gradient Boosting بههمراه دیگر تابعهای هزینه استفاده کرد. این کار رو میشه با استفاده از هایپرپارامتر loss انجام داد
در اینجا نکتهی قابل توجه اینه که یک پیادهسازی بهینه از Gradient Boosting در کتابخانه محبوب XGBoost وجود داره، که مخفف Extreme Gradient Boosting هست. در ابتدا این پکیج رو Tianqi Chen بهعنوان قسمتی از Distributed(Deep) Machine Learning Community گسترش داد و هدفش این بود که فوق العاده سریع، مقیاسپذیر و قابل حمل باشه. در واقع XGBoost اغلب اوقات یکی از اجزای مهم برندگان مسابقات ماشین لرنینگ هست. XGBoost یک API شبیه به Scikit-Learn داره:
import xgboost xgb_reg = xgboost.XGBRegressor() xgb_reg.fit(X_train, y_train) y_pred = xgb_reg.predict(X_val)
این کتابخونه همچنین یک سری ویژگیهای خوب هم داره، مثل خودکار مدیریت کردن Early Stopping:
xgb_reg.fit( X_train, y_train, eval_set=[(X_val, y_val)], early_stopping_rounds=2 ) y_pred = xgb_reg.predict(X_val)
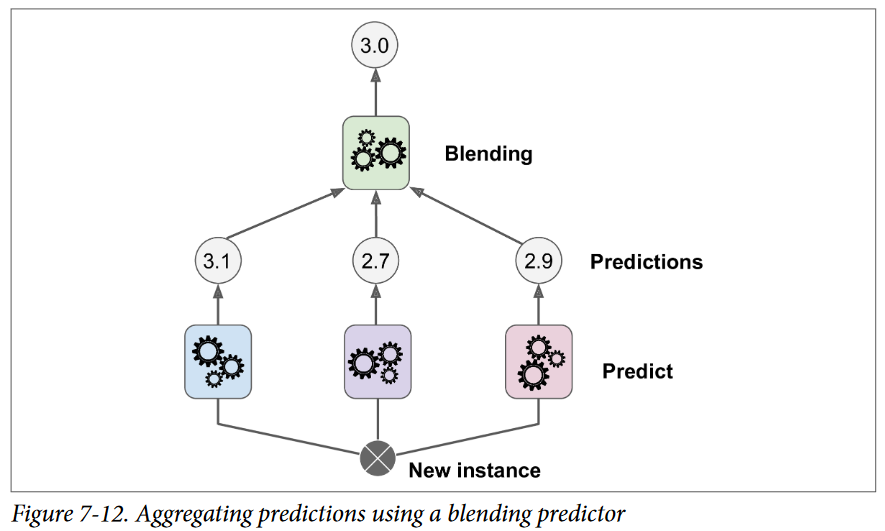
آخرین روش Ensemble که توی این فصل میخوایم بررسی کنیم، Stacking نام داره (کوتاه شدهی Stacked Generalization). این روش برپایهی یک ایدهی ساده هست: بهجای استفاده از تابعهای اضافهای (مثل Hard Voting) برای تجمیع پیشبینی همهی Predictorها در یک Ensemble ، چرا یک مدل آموزش ندیم که این تجمیع رو انجام بده؟ شکلی که در پایین میبینید یک همچین Ensemble رو نشون میده که یک عملیات رگرسیون رو بر روی یک نمونهی جدید انجام میده. هر کدوم از سه Predictor پایین یک مقدار متفاوت رو پیشبینی میکنه (3.1و 2.7 و 2.9) و Predictor نهایی (به نام Blender یا Meta Learner) این پیشبینیهارو بهعنوان ورودی میگیره و پیشبینی نهایی رو انجام میده (3.0)
یک راه عمومی برای آموزش یک Blender ، استفاده از Hold-Out Set هست. ببینیم چجوری کار میکنه. اول ترینینگ ست به دو زیرمجموعه تقسیم میشه. از اولین زیرمجموعه برای آموزش Predictorها در لایهی اول استفاده میشه.
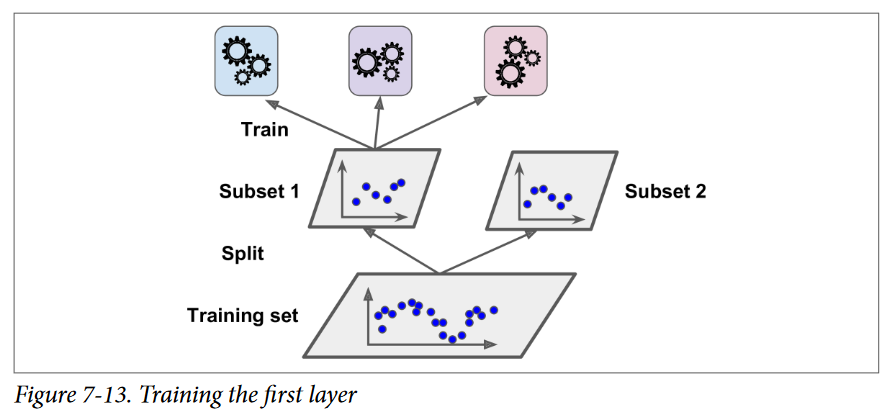
بعد، از Predictorهای لایهی اول استفاده میشه تا پیشبینیهایی روی زیرمجموعهی دوم انجام بشه. با این کار اطمینان حاصل میشه که پیشبینیها پاک هستن چونPredictorها هیچوقت حین آموزش این نمونههارو ندیدن. برای هر نمونه در Hold-Out Set سه مقدار ِ پیشبینی شده وجود داره. میتونیم یک ترینینگ ست جدید با استفاده از این مقادیر پیشبینیشده بهعنوان ورودی درست کنیم (که باعث میشه این ترینینگ ست 3 بعدی بشه) و مقادیر Target رو نگه داریم. Blender روی این ترینینگ ست آموزش میبینه، پس یاد میگیره که مقادیر Target رو با دریافت پیشبینیهای لایهی اول پیشبینی کنه.
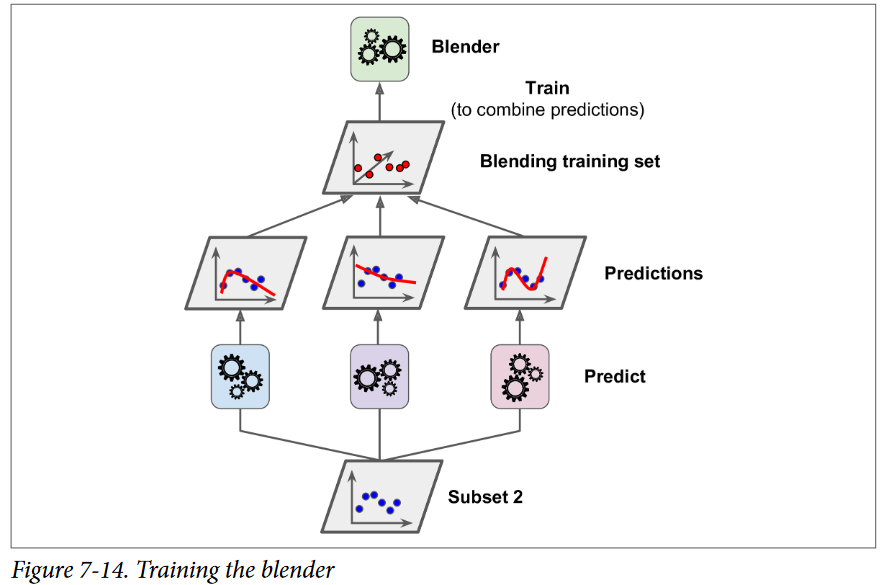
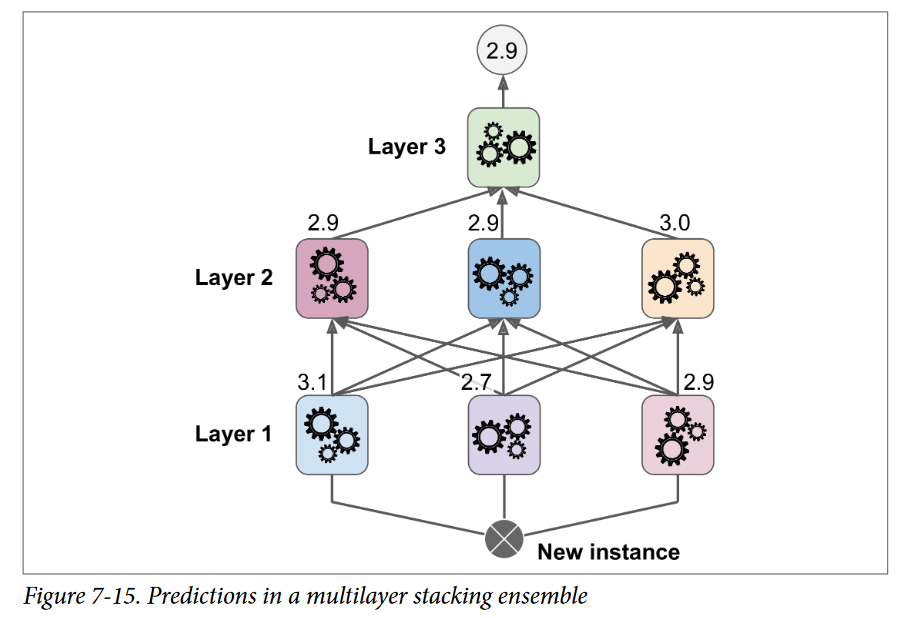
با این روش میتونیم چندین Blender متفاوت رو آموزش بدیم تا یک لایهی کامل از Blenderها داشته باشیم. (مثلا یکی با استفاده از Linear Regression و یکی با استفاده از Radnom Forest Regression) نکته اینجاست که ترینینگ ست رو به سه زیرمجموعه تقسیم کنیم: از اولین زیرمجموعه استفاده میشه تا لایهی اول آموزش ببینه، از دومی استفاده میشه تا یک ترینینگ ست برای آموزش لایهی دوم درست بشه (با استفاده از پیشبینیهایی که توسط Predictorهای لایهی اول انجام شده) و از سومی استفاده میشه تا یک ترینینگ ست برای آموزش لایهی سوم درست بشه ( با استفاده از پیشبینیهایی که توسط Predictorهای لایهی دوم انجام شده) وقتی این کار تموم بشه، میتونیم با رفتن به هر لایه بهصورت ترتیبی، یک پیشبینی برای یک نمونهی جدید انجام بدیم. در شکل پایین نشون داده شده.
این هم از فصل ۷ کتاب Hands-On Machine Learning. امیدوارم مفید واقع شده باشه.