بسیار عالی . حالا میخوایم از هرچیزی که تا الان یاد گرفتیم استفاده کنیم و یک پروژه بسازیم :
اگر تا الان باهامون همراه نبودی پیشنهاد میکنم یک سر به این پست بزن و برگرد .

https://github.com/mahdipakravan-dev/ai-practice/blob/main/califonia-house.ipynb
قیمت میانهی خانهها در یک ناحیه از کالیفرنیا.
این قیمت بر حسب 100,000 دلار داده شده : مثلا مقدار 2.45 یعنی 245,000 دلار
MedInc median income in block group (درآمد متوسط خانوارها در آن ناحیه، به هزار دلار)
HouseAge median house age in block group (سن متوسط ساختمانها در آن ناحیه (به سال))
AveRooms average number of rooms per household (کل تعداد اتاقها در ناحیه تقسیم بر تعداد خانوارها)
AveBedrms average number of bedrooms per household (مشابه بالا، ولی فقط اتاقخوابها)
Population block group population (تعداد کل افرادی که در آن ناحیه زندگی میکنند)
AveOccup average number of household members (تعداد کل افراد تقسیم بر تعداد خانوارها)
Latitude block group latitude موقعیت شمال-جنوب ناحیه (اعداد بزرگتر یعنی شمالتر)
Longitude block group longitude (موقعیت شرق-غرب ناحیه (اعداد منفی و نزدیک به -118 یعنی غربتر، نزدیک به ساحل))
۱-دیتاست برگرفته از سرشماری سال 1990
هر ردیف در دیتاست مربوط به یک گروه بلوکی (Block Group) از دادههای سرشماریه.
یعنی هر ردیف نمایندهی یک ناحیه کوچیکه (نه یک خونه خاص).
و Block Group معمولاً شامل 600 تا 3000 نفره.
۲-منظور از Household چیه؟
یک Household یعنی مجموعهای از افراد که با هم در یک خونه زندگی میکنن.
ستونهایی مثل Households, AveRooms, AveBedrooms بر اساس این مفهوم تعریف شدن.
۳-نکته درباره میانگینها:
ستونهایی مثل AveRooms یا AveBedrooms نشوندهنده میانگین بهازای هر Household هستن، نه هر خونه!
در جاهایی که تعداد خانوارها کم باشه اما خونه زیاد (مثلاً مناطق تفریحی یا ویلاها)، ممکنه میانگینها عدد بزرگی باشن.
دیتاست کجاست ؟ خود scikit-learn که میخوایم ازش برای پیاده سازی مدل هامون استفاده کنیم:
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.fetch_california_housing.html
from sklearn.datasets import fetch_california_housing from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error, r2_score from sklearn.preprocessing import StandardScaler import matplotlib.pyplot as plt import pandas as pd california = fetch_california_housing() X = california.data y = california.target feature_names = california.feature_names
الان دیتاست ما یک آرایه 20640 ردیف در ۸ ستونه هستش و در قالب پانداز نیست پس با کد زیر تبدیلش میکنیم به دیتاست پانداز :
df = pd.DataFrame(california.data, columns=california.feature_names) df['MedHouseVal'] = california.target
حالا میایم مراحل PreProcessing رو روش انجام میدیم که تمام اونها رو در این لینک توضیح دادم :
آموزش کامل Missing Values در این لینک موجوده
df.info()
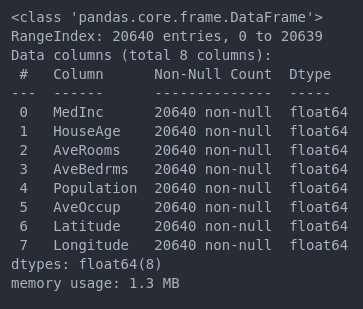
نتیجه : همونطور که میبینید خوشبختانه ما هیچ دیتای Missing Value توی دیتاستمون نداریم اگر هم داشتیم نگران نبودیم ما راه حل دقیقش رو میدونیم و توی این لینک کامل در موردش توضیح دادیم
اگر میخواستین خیالتون راحت باشه از کد زیر استفاده کنید که جمع تعداد Missing Value ها رو بهتون میده :
df.isnull().sum()
آموزش کامل Outlier ها در این لینک موجوده .
همانطور که در پست مربوط به Otlier ها توضیح دادم میتونیم با استفاده از یک کد تمامی Outlier ها رو رسم کنیم :
import matplotlib.pyplot as plt import seaborn as sns import pandas as pd plt.figure(figsize=(14, 6)) sns.boxplot(data=df) plt.xticks(rotation=45) plt.grid(True) plt.tight_layout() plt.show()
نتیجه :
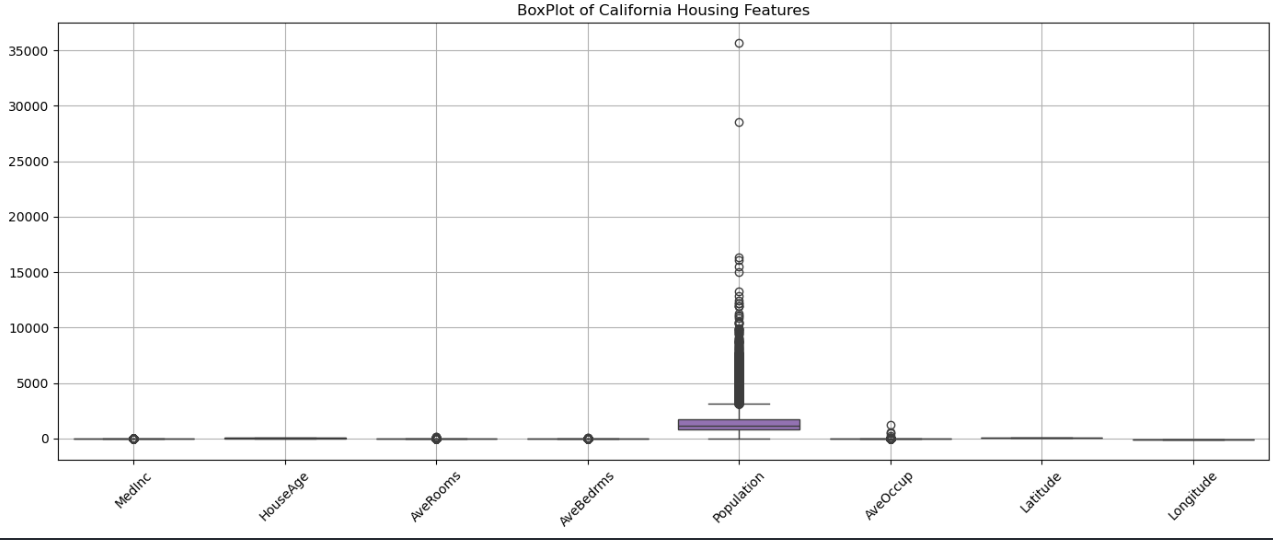
همانطور که میبینید Population به مقدار خیلی زیادی Outlier داره و همچنین یکمی AveOccup .
آیا میخواهی داده زیادی حذف نشود ؟ بله چون اینکه تعداد مردم یک منطقه چقدره برامون بسیار مهمه .
آیا مدلی که میخوای استفاده کنی به Outlier حساسه ؟ بله میخوایم از Linear Regression استفاده کنیم .
خب پس با این حساب :
بهترین انتخاب برای Population : تکنیک Capping Flooring
بهترین انتخاب برای AveOccup : تکنیک IQR یا Capping
برو بریم !
import numpy as np def remove_outliers_iqr(df, column): Q1 = df[column].quantile(0.25) Q3 = df[column].quantile(0.75) IQR = Q3 - Q1 lower = Q1 - 1.5 * IQR upper = Q3 + 1.5 * IQR return df[(df[column] >= lower) & (df[column] <= upper)] df_clean = df.copy() # Handling Population Outliers df_clean['Population'] = np.log1p(df_clean['Population']) # Handling AveOccup Outliers df_clean = remove_outliers_iqr(df_clean, 'AveOccup') df_clean
چرا اومدیم یک نسخه Copy ساختیم ؟ چون ممکنه در آینده بفهمیم میتونستیم تکنیک بهتری انتخاب کنیم.
البته تو دیتا های بزرگ که بعدا باهاشون برخورد میکنیم چون بزرگتر هستن یکم سخت تر میشه :)
آموزش کامل Categorical Value ها تو این لینک موجوده .
همانطور که میبینید ما داده هامون تماما String هستن و نیازی نیست مراحل Encoding روش داشته باشیم اما اگر شما این مشکل رو داشتین حتما این مقاله رو مطالعه کنید تا با موفقیت از پسش بر بیاید .
آموزش کامل در این لینک موجود است .
با توجه به اینکه میخوایم از Linear Regression در مرحله مدل سازی استفاده کنیم میایم و Standard Scalar رو استفاده میکنیم .
قبل اینکه Scale بکنیم یک نکته بسییییییییییار مهم رو داشتیم فراموش میکردیم .
ما دو ویژگی داریم به نام Latitude و Longitude .
آیا مختصات مکانی باید Scale شود ؟ خیر چون داده ما خراب میشه .
پس توی کد میایم و قبل از Scale کردن اون ها (مختصات مکانی) رو جدا میکنیم و بعد از Scale مجددا به دیتاست متصلشون میکنیم
numeric_cols = df_clean.select_dtypes(include=['int64', 'float64']).columns non_geo_cols = df_clean.drop(columns=['Latitude', 'Longitude']) scaler = StandardScaler() X_scaled_part = scaler.fit_transform(non_geo_cols) X_scaled_array = np.concatenate([X_scaled_part, df_clean[['Latitude', 'Longitude']].values], axis=1) final_columns = list(non_geo_cols.columns) + ['Latitude', 'Longitude'] df_scaled = pd.DataFrame(X_scaled_array, columns=final_columns) df_scaled
آموزش کامل مهندسی ویژگی در این لینک موجود است .
گاهی اوقات میتونیم ویژگیهامون رو طوری بازطراحی (مهندسی) کنیم که هم برای خودمون قابل درکتر بشن، هم برای مدلهای یادگیری ماشین مؤثرتر.
به عنوان مثال، در این دیتاست دو ستون Latitude و Longitude داریم.
اما آیا واقعاً برای ما (یا مدل) قابل درکه که مثلاً:
«خانهای در مختصات جغرافیایی 34.23 و -118.45 قیمتی معادل 250 هزار دلار دارد»؟
مسلماً نه! حتی یک انسان هم نمیتونه به راحتی از روی مختصات خام، درک درستی از موقعیت خانه داشته باشه.
حالا فرض کنید به جای مختصات، بگیم:
«این خانه در منطقه سعادتآباد قرار دارد و خانههای این منطقه بهطور متوسط گرانتر از مناطق پایینشهر هستند.»
اینجا نه تنها مدل راحتتر میتونه الگوها رو یاد بگیره، بلکه برای تحلیل ما هم معنادارتر خواهد بود.
پس بیایم و مهندسی ویژگی کنیم .
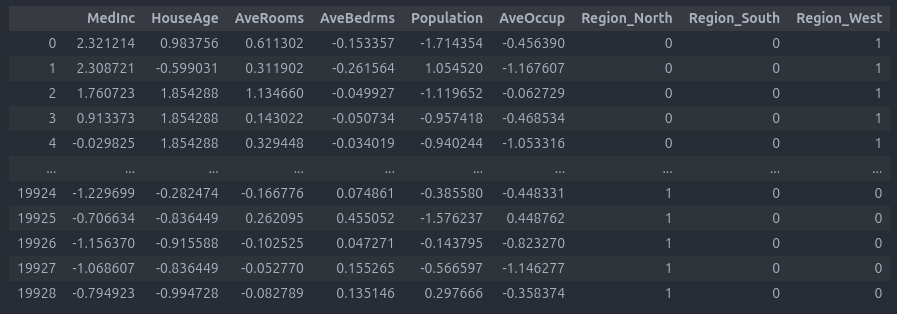
def map_location_to_region(lat, lon): if lat > 38: return 'North' elif lat < 33: return 'South' elif lon < -121: return 'West' else: return 'Central' df_scaled['Region'] = df_scaled.apply(lambda row: map_location_to_region(row['Latitude'], row['Longitude']), axis=1)
الان به دیتاست زیر میرسیم :

خب همونطور که میبینید ما یک ستون جدید اضافه کردیم به نام Region و به صورت String هستش پس میایم Categorical Value رو هندل میکنیم :
چون به صورت رده ای نیست (بالا به پایین مهم نیست) میایم از Label Encoding استفاده میکنیم :
df_encoded = pd.get_dummies(df_scaled, columns=['Region'], drop_first=True, dtype=int) df_encoded
نتیجه نهایی :
آموزش کامل مهندسی ویژگی اینجا موجود است
میایم کد زیر رو میزنیم :
import seaborn as sns import matplotlib.pyplot as plt numeric_df = df_encoded.select_dtypes(include=['int64', 'float64']) correlation_matrix = numeric_df.corr() plt.figure(figsize=(10, 6)) sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt='.2f', linewidths =0.5) plt.title('Correlation Matrix') plt.show()
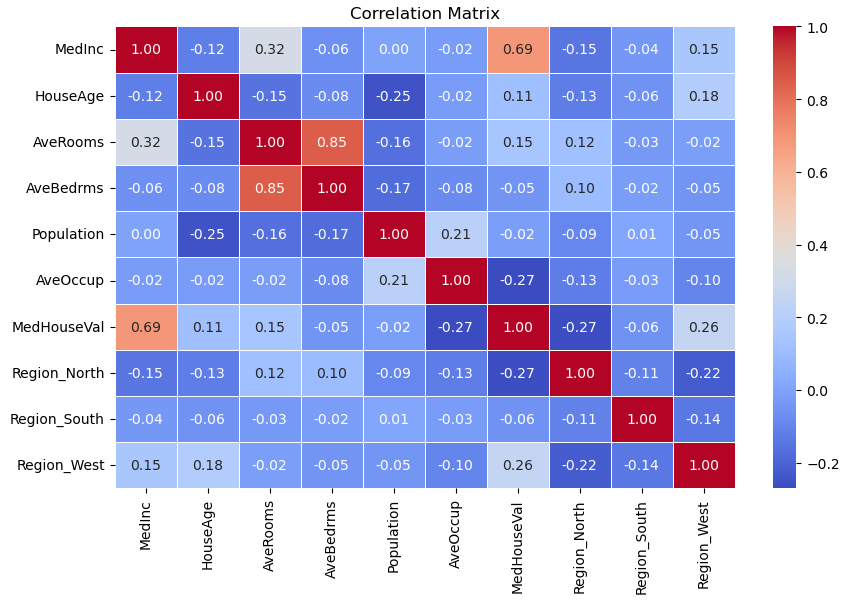
هدف ما ستون MedHouseVal هستش به این ستون و تاثیر سایر ستون ها روی اون دقت کنید .
اما یک نکته حائز اهمیت دیگه ای که داریم شباهت AveRooms و AveBedrms هستش
میتونیم یک فیچر از ترکیبشون تولید کنیم یا یکیشون رو حذف کنیم .
چون خانههایی با اتاقهای بیشتر معمولاً اتاقخواب بیشتری هم دارند
df_encoded = df_encoded.drop(["AveBedrms" ] , axis=1)
حالا وقتشه که کدی که زدیم رو تست بکنیم و ببینیم چقدر تو مدل درست جواب میده .
به زبان ساده بیایم ببینیم اگر بخوایم پیش بینی کنیم قیمت خانه در کدام ناحیه چقدره مدل چه جوابی بهمون میده و بعدش ببینیم این مدل چقدر درست کار میکنه .
from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error, r2_score X = df_encoded.drop(columns=['MedHouseVal']) y = df_encoded['MedHouseVal'] X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42 ) model = LinearRegression() model.fit(X_train, y_train) y_train_pred = model.predict(X_train) y_test_pred = model.predict(X_test) mse_train = mean_squared_error(y_train, y_train_pred) r2_train = r2_score(y_train, y_train_pred) mse_test = mean_squared_error(y_test, y_test_pred) r2_test = r2_score(y_test, y_test_pred) print(f"Train Mean Squared Error: {mse_train:.2f}") print(f"Train R^2 Score: {r2_train:.2f}") print(f"Test Mean Squared Error: {mse_test:.2f}") print(f"Test R^2 Score: {r2_test:.2f}")
نتیجه نهایی :
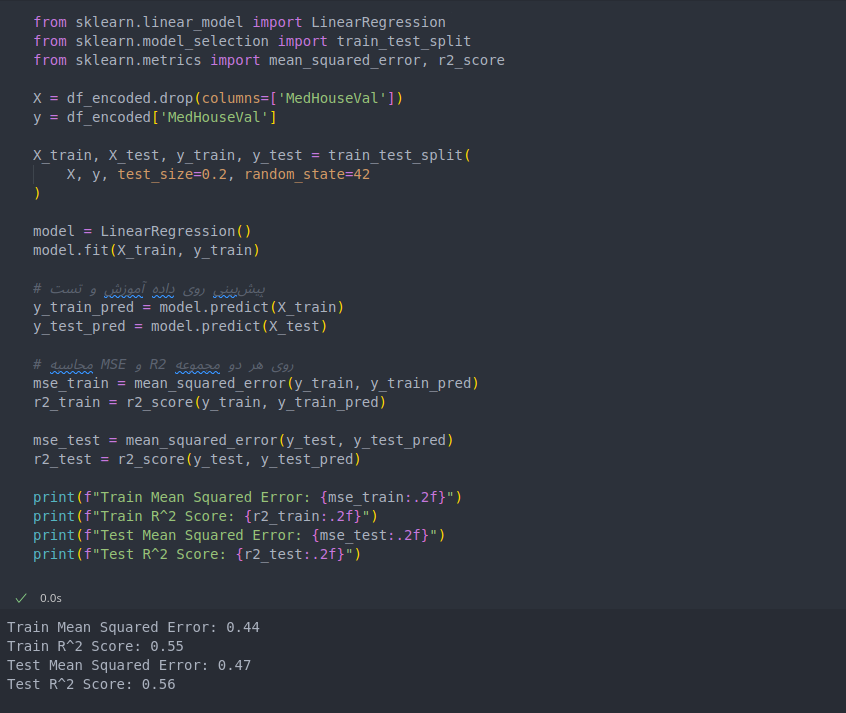
این یعنی چی ؟
اگر خطای روی دادهی آموزش خیلی کم باشه ولی روی دادهی تست زیاد، مدل احتمالاً Overfit داره.
اگر خطا روی هر دو داده بالا باشه، یعنی مدل نمیتونه خوب یاد بگیره، احتمالاً Underfit است.
در نتیجه :
جواب Train و Test خطا و R² خیلی نزدیک هم هستن
یعنی مدل روی داده آموزش و تست تقریباً یک عملکرد مشابه داره
تفسیر:
مدل نه Overfit داره (چون خطا روی آموزش خیلی پایینتر نیست)
نه Underfit خیلی شدید (چون خطا نسبتاً معقوله ولی R² هم زیاد بالا نیست)
مدل فعلی داره همون کاری که میتونه انجام بده رو انجام میده، به احتمال زیاد با دادهها و ویژگیهای فعلی، این بهترین عملکردشه.
بهتره به جای تغییر مدل خیلی ساده (LinearRegression)، مدلهای قویتر (مثل RandomForest، GradientBoosting، یا حتی مدلهای غیرخطی) رو امتحان کنیم
تو قسمت های بعدی مدل های دیگر رو یاد میگیریم و مجددا دیتاست نهاییمون رو باهاش تست میکنیم .
خوشحال میشم نظرتون رو در مورد این قسمت بدونم :)
تا مقاله بعدی خدانگهدار